吴恩达机器学习笔记(二)
吴恩达机器学习笔记(二)
决策树模型
什么是决策树
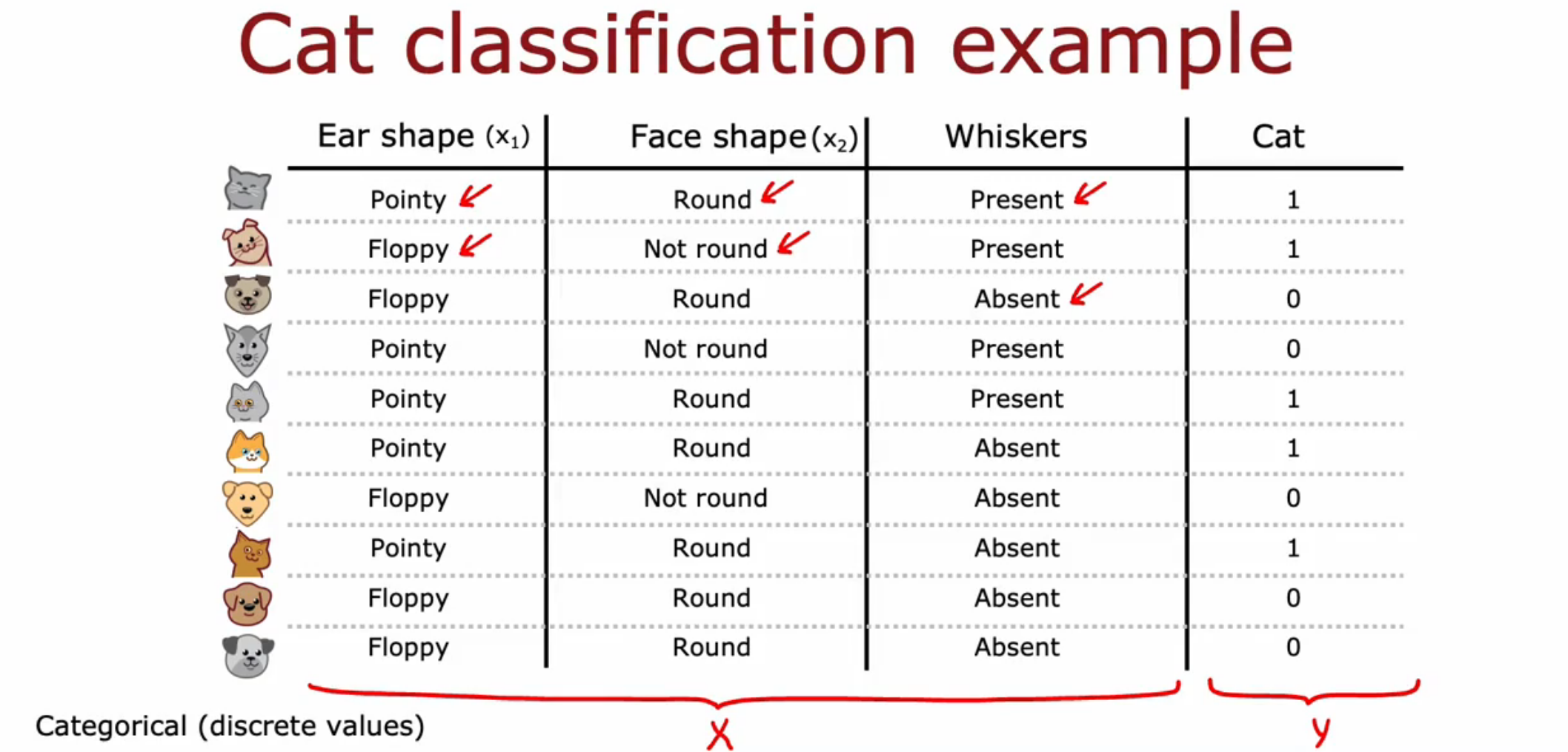
给定一组数据,如果想对数据进行分类或者回归,可以采用决策树来解决这个问题。
决策树是一种树形结构,从训练数据众多特征中选择一个特征作为决策依据。其中,树的每个节点(除叶节点)表示一个特征的决策,用于对不同的数据进行分类。而叶节点表示分类的结果。
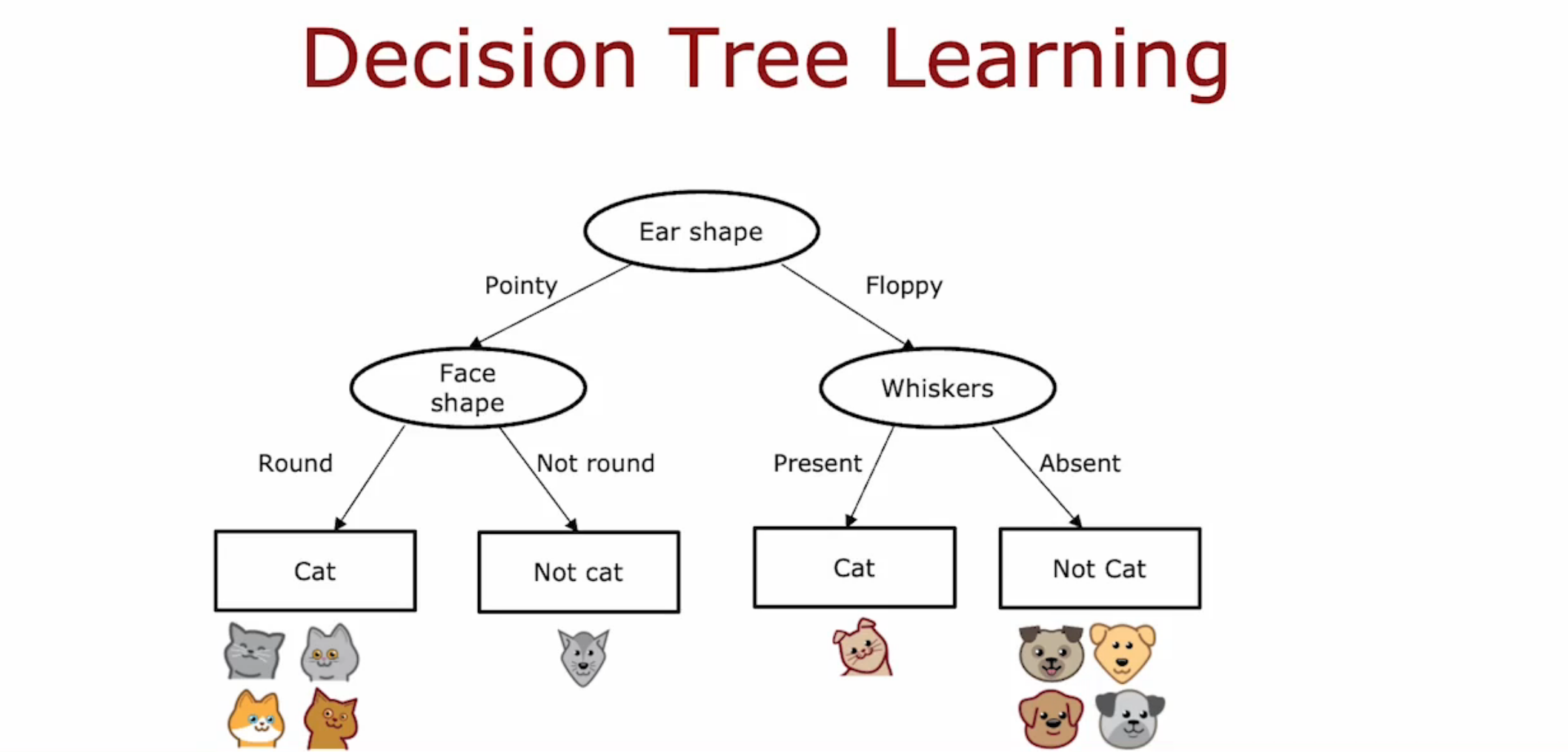
决策树是由根节点不断分裂而成的
- 怎么选择分裂的特征
- 可以采用信息增量(Information Gain)来决策,优先选择信息增量较大的特征。信息增量的概念由下文解释。
- 何时停止分裂
- 当这个节点下只有一个类的时候
- 当再进行一次分裂,将会超过设定的树的深度的时候
- 当分裂后提升的纯度不够大(小于设定的阈值)
- 当节点下的数据项过少
纯度
采用信息熵(Entropy)来表示数据的混乱性。
同时,将父子节点之间减少的熵定义为信息增量(IG),公式以根节点和其下分裂的节点为例。
其中,\(P(x_i)\)表示特征\(x_i\)占当前样本的比例。\(w^{left}\)表示左节点项目的数量占整体(根节点项目数量)的比例。\(w^{right}\)同理。
\[H(x) = -\sum^{n}_{i=1} P(x_i) \log_2 P(x_i)
\]
\[IG = H(p^{root}_1) - (w^{left}H(p^{left}_1) + w^{right}H(p^{right}_1))
\]

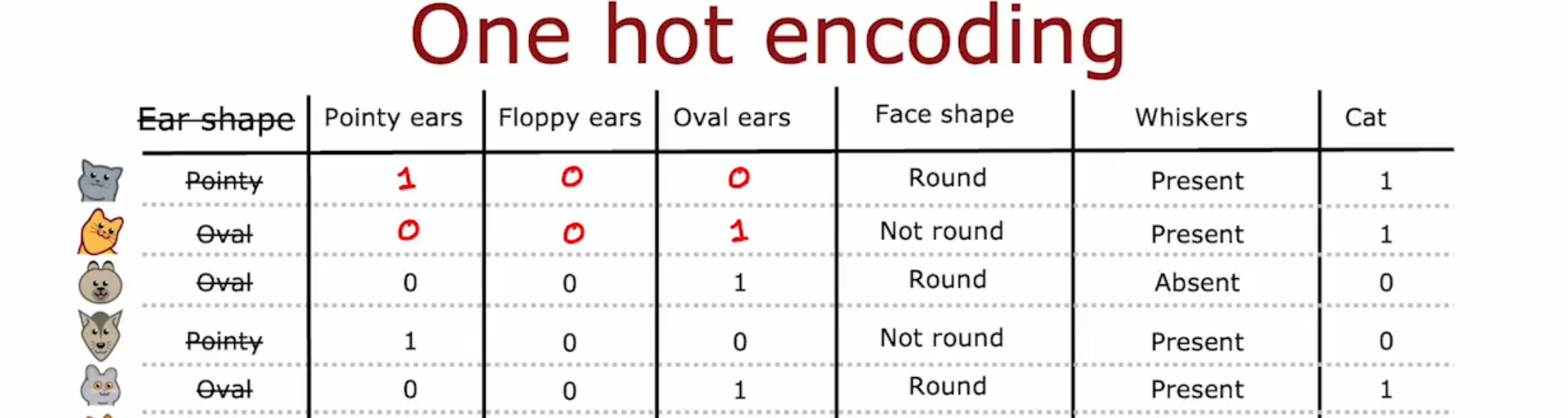
One-Hot Encoding
一种编码方式,如果一个特征可以取k个值,那么将其分为k个二进制特征,即以\(101110...\)这种方式表示。
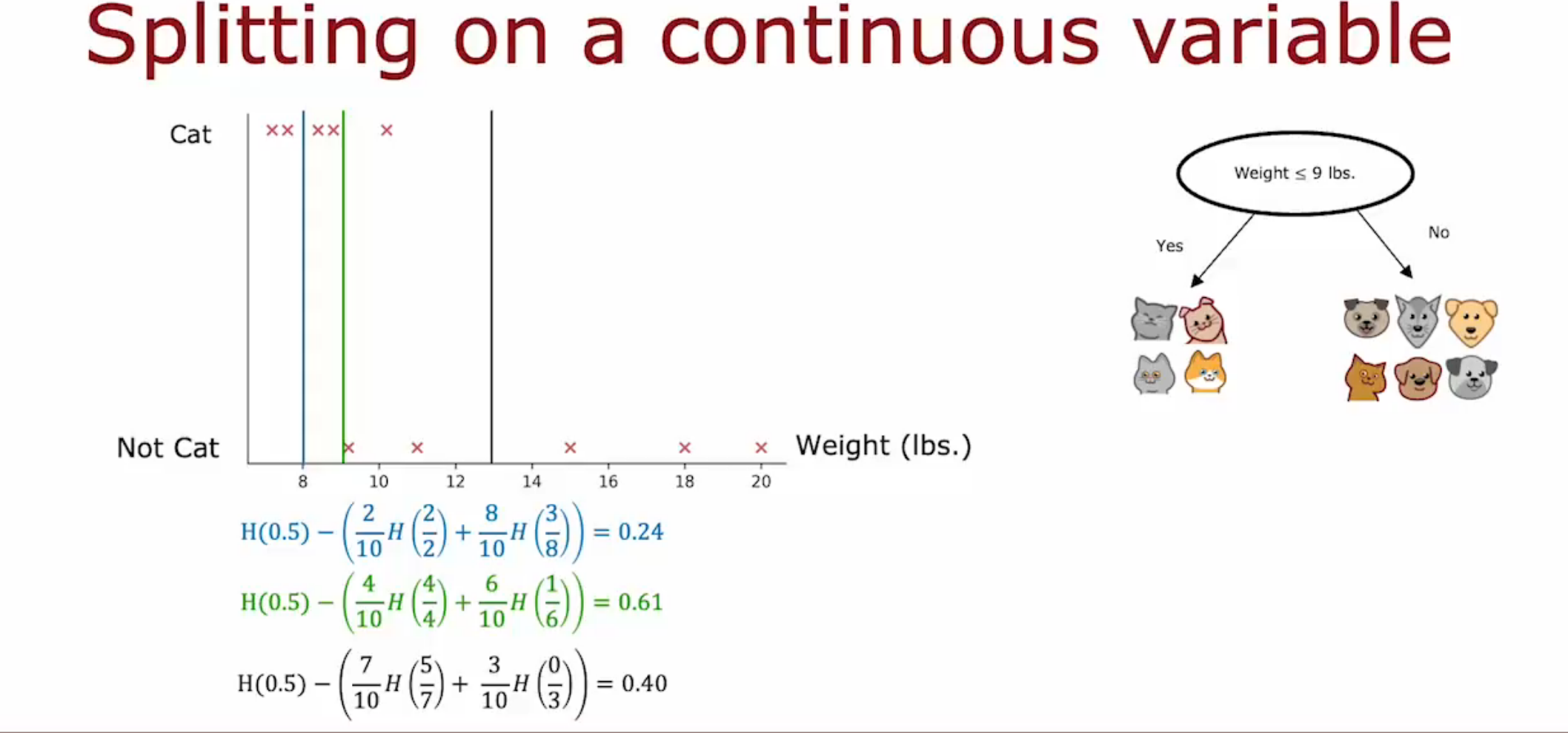
连续型变量的分裂
同样采用信息增量用于分裂计算。只是在分裂时,将特征判断变为\(w > x\)的形式(\(w\)是特征,\(x\)是判断的阈值)
回归树
回归树输出的值是连续的,而决策树输出的值是离散的。可以采用方差来计算信息增量。

随机森林算法
Tree Ensemble
单个决策树的稳定性不高。比如,在分裂时一个数据不同就可能导致分裂的特征取不同的值。所以需要多个决策树来解决这个问题,即Tree Ensemble
这个模型用多个树的结果进行投票来确定预测。比如,对于一个数据(猫和狗的分类),有两个树的结果是猫,一个不是,那么预测的结果就是猫。
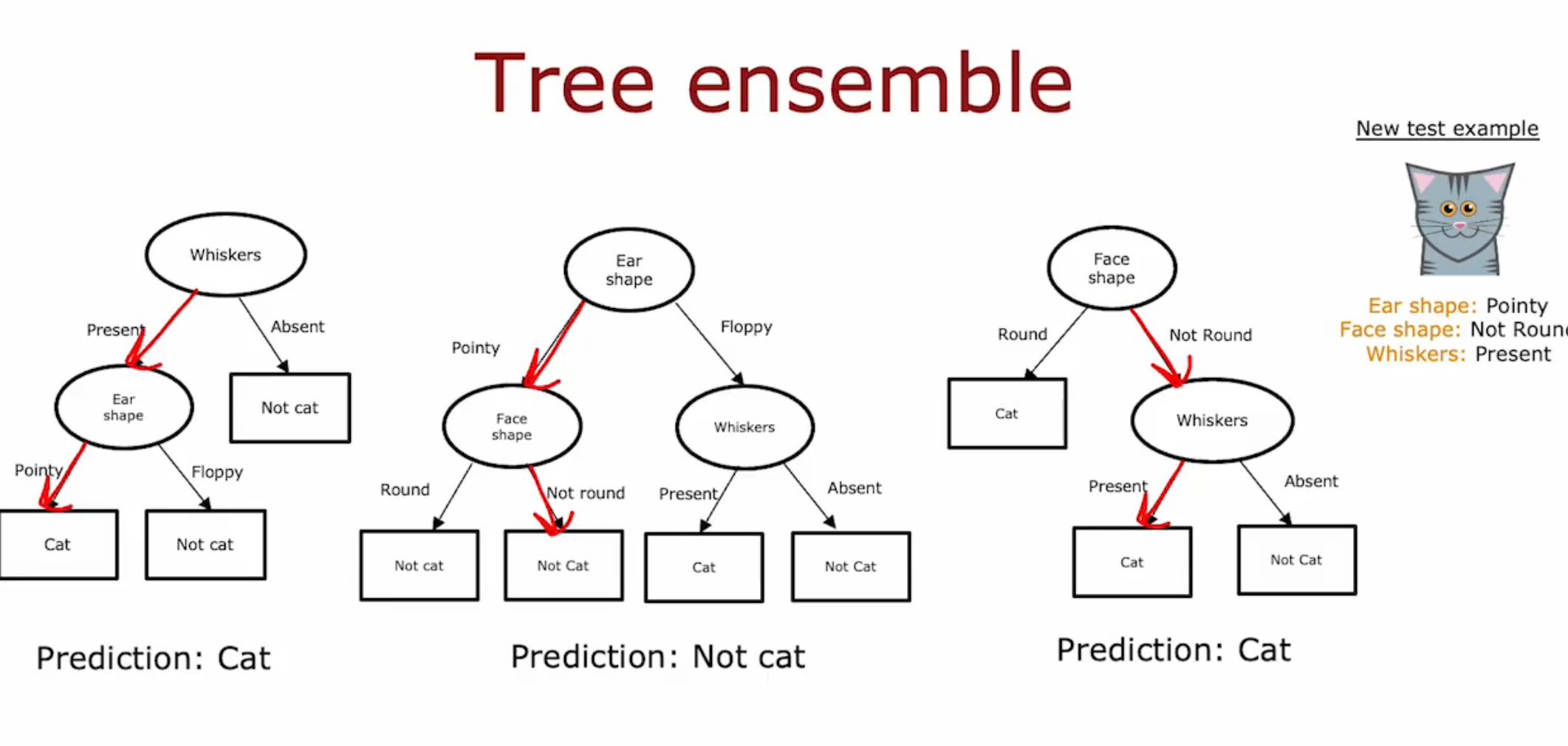
随机森林
随机森林通过以下两种方法创建模型
- 从总训练集中进行放回抽样,生成一棵树的训练集
- 选取分裂特征时,若一共有\(n\)个特征,可选取\(k = \sqrt{n}\)个特征作为分裂特征

XGBoost
是一种改进的Boosted Tree。主要原理是在训练模型时,预测错误的数据在下一棵树的放回抽样中有更高的概率被抽取。
决策树与神经网络
决策树适合被应用于结构化的模型(表格类)。小型的决策树容易可视化,同时训练速度较快。
神经网络可以处理结构化与非结构化的数据(图像、声音),同时,可以采用迁移学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号