吴恩达机器学习笔记(一)
吴恩达机器学习笔记(一)
迁移学习
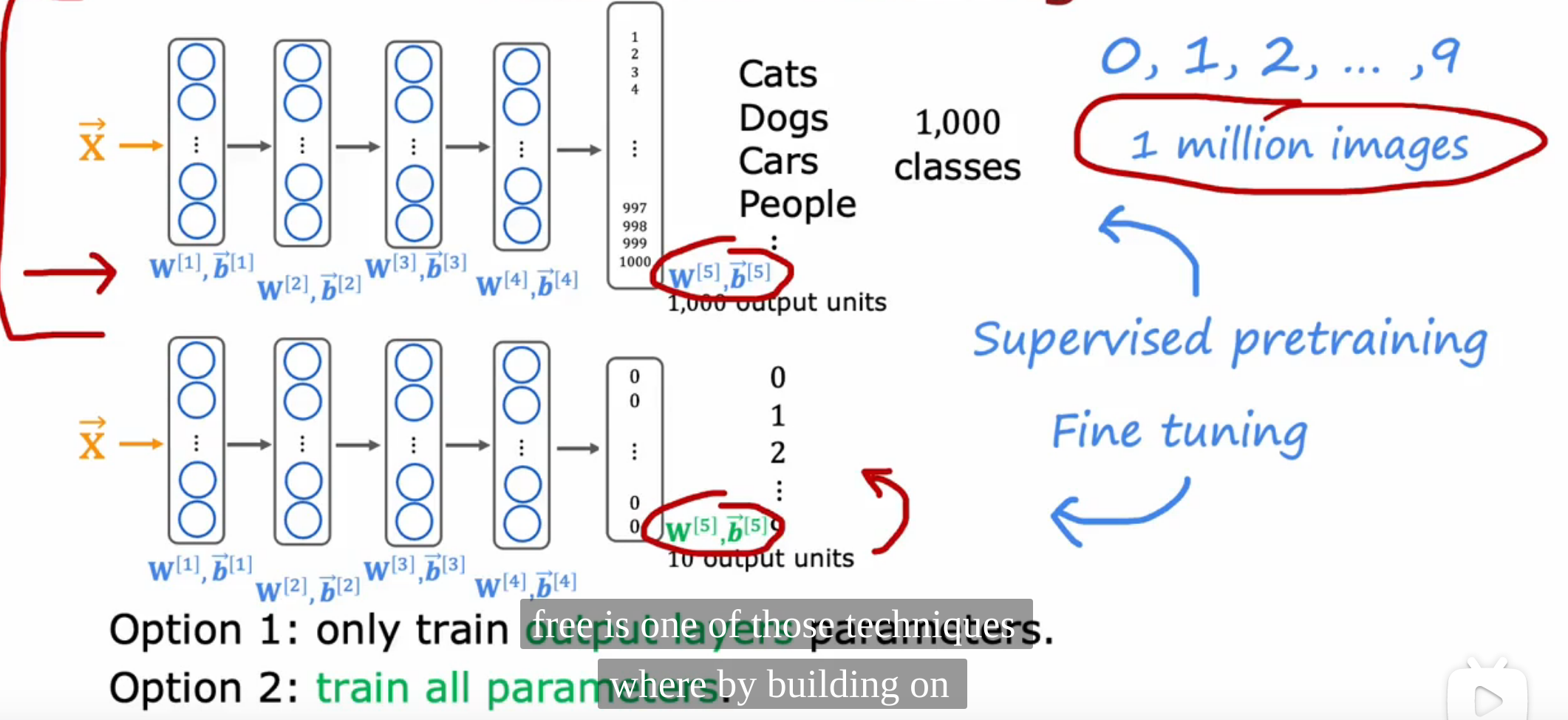
解释:
当需要训练小数据模型时,可以使用已经训练好的大模型(需要输入数据类型相同)。更改其输出层符合输出格式。比如将分类1000种物品的输出层(1000个输出)改为分辨0~9手写数字的输出层(10个输出)。
- 当训练集非常小:只更改输出层参数
- 当训练集比较小:可更改所有层参数
倾斜数据集的误差指标
使用混淆矩阵来表明各个任务指标,矩阵如下:
| 预测值=0 | 预测值=1 | |
|---|---|---|
| 真实值=0 | TN(真反例) | FP(假正例) |
| 真实值=1 | FN(假反例) | TP(真正例) |
准确率(Accuracy)
\[Accuracy = \frac{TP+TN}{TP+TN+FP+FN}
\]
准确率是最为明显的分类指标,但是数据不平衡时,准确率的效果是低下的。比如100个样本里有99个正样本,那只用一直预测正样本,准确率就会很高,但是预测不出负样本。
精确率(Precision)
\[Precision = \frac{TP}{TP+FP}
\]
精确率表示预测结果为正样本中正样本的比例。
当反例被误认为正例的代价很高时,宜采用精确率。例如检测一例罕见病的代价很高,但是如果一个没罕见病的患者被预测为患有罕见病(FP),那么就要付出比较高的检测代价。
召回率(Recall)
\[Recall = \frac{TP}{TP+FN}
\]
召回率表示实际结果为正样本中预测为正样本。
当正例被误认为反例的代价很高时,宜采用召回率。比如在银行中,将欺诈性交易预测为非欺诈性交易的情况。
F1 Score
\[F1\ Score = 2×\frac{Precision×Recall}{Precision+Recall}
\]
Precision越高,模型越能区分负样本。Recall与正样本的区分能力正相关。而F1 Score是两者的综合,越高则模型越稳健。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号