
索引的一些事一些情
之前在我的上一篇文章《系统性能优化二三事》中提到了sql的性能优化的问题。因为时间和篇幅的关系,当时并没有进行什么讨论,那现在我们就来讨论关于索引的一些事一些情~
b-tree索引的结构如上图所示。从结构上我们知道b-tree索引是一个树状的数据结构结点间相互连接,同一层的结点从左到右按value的值排序好,其实这种数据结构就叫b+tree。这个b+tree中文的意思就叫平衡树的意思。叫平衡树的原因,因为从树的根结点到任意一个叶子经过的路径长度都是相等的~。对于b+ree这种搜索树的结构来说其实树越矮越胖是越好的,因为在这些结构中查询数据的时间复杂度其实是与树的高度成正比的~,原理和我们的二叉搜索树是一样的。正因为b-tree索引因为数据是排好序的所以它支持模糊匹配,范围查询,排序,group by 等高级操作~。
如果有一个情景是让我们从user表中查询名字叫"jack"的年龄是25岁的男性,那应该是怎么去建一个b-tree索引?。
如果是我一般会建一个(name,age,sex)的b-tree复合索引,why?。因为复合索引有一个最左匹配原则,我们sql的过滤条件都是先按最左边的过滤,如果索引的前面的列不能过滤那么后面的列也是不能过滤的这个道理我相信大家都理解。而我们的用户查询中常用的一个查询就是根据名字查询,所以name要放在第一列,至于第二列为什么放的是age呢,其实是从我们上面的三个维度和三星原则出发的。因为name通常是sex是强相关的,比如在西方国家一个叫jack的人通常可以肯定是个man而不会是个miss,这个在东方国家也是适用的,你能想像一个男人起个名字叫翠花么。。。并且因为人口基数众多,同名的人也多。所以name,sex放在前面两列是起不了多大的过滤效果。这就不符合我们的"减少服务器需要扫描的数据量"和三星标准的第一标准,但是age是可以的,并且如果是按年排序的话,age第二列就已经排好序了,不经意间我们就创建了一个二星索引,所以把age第二行!。sex第三列则是用于滤精确结果。如果查询只要求返回name,age,sex三列那我们都不需要去查表里面的数据,直接返回索引里面的数据就可以了,这就是一个perfect的三星索引~。
下面列举一些常用建索引的最佳实践:
1、一般建索引时优先创建复合索引而不是多个单列索引,比如常用的几个过滤条件是A,B,C。那就应该创建一个(A,B,C)同时包含三列的复合索引因为这样的过滤效果最好,而不是分别建A,B,C三个单独索引。因为mysql在一个查询语句中只能选择生效一个索引~。如果创建单列索引的话,比如生效了(A)索引,B,C列的过滤就只能是读取表中的记录之后再进行过滤,如果是(A,B,C)复合索引的话就直接在索引就可以过滤好记录,大大的减少了服务器的读取数量~。
2、复合索引一般是常用的过滤项放在靠前的位置,两个强相关的列不要放在紧挨在一起,这个上面的jack例子就有说明。
3、一般来说优先选择数字的列和字段较小的列建索引,选择数字的列是因为cpu天生就支持数字的比较,运算复杂度看作是O(1),如果是varchar(n)的话就要一个个字符去比较,那平均复杂度就是O(n/2)了。选择字段较小的列是因为索引也是占空间,如果索引太大不放进内存里面那每次读索引都要进行一次磁盘的读取,这个就很影响性能了。
顺序IO、随机IO与索引
上面提到 "索引建的不好的一般的结果是没有走索引也就是索引没起效这种结果就是扫全表,但是有些时候你可能会发现走了某些索引的查询可能会比扫全表更慢"。why?这就需要分析顺序IO与随机IO的区别了。顺序IO指的磁盘沿着扇区一直扫,比如磁盘的读取速度是40M/S,一条记录的大小是400Byte。那读取一条记录的时间是0.01ms。而一次随机IO理想的估算是大概是10ms左右,分析如下所示。
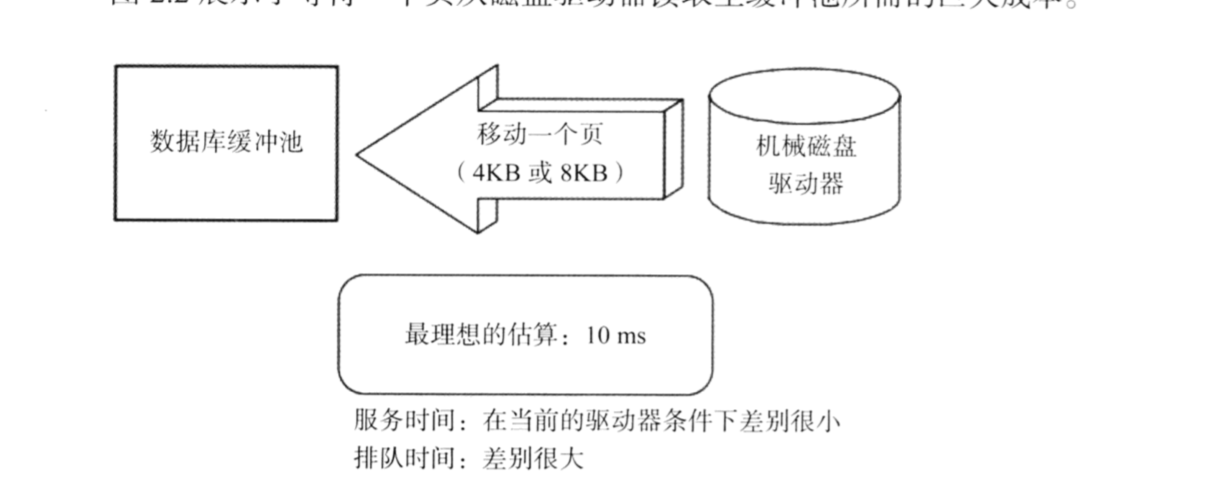
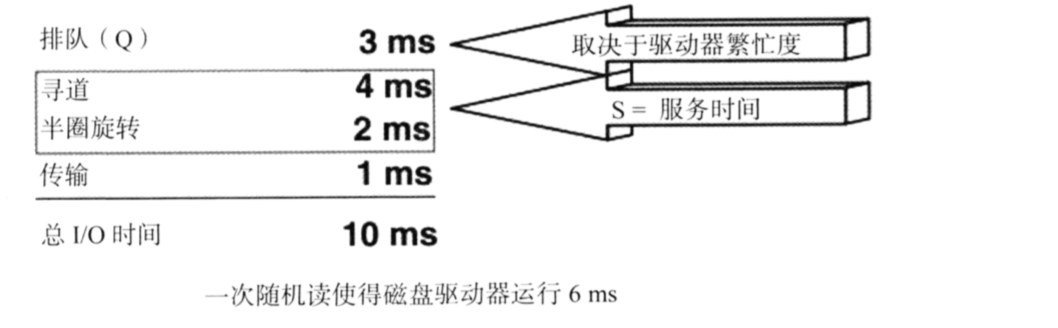
比如从一个10W条记录里面读取2000条记录如果是扫全表那花的时间是
10ms + 100000 * 0.01ms ~= 1s
如果是随机I/O:
2000 * 10ms = 20s;
所以如果你的建的索引并没有把随机I/O变成顺序I/O那就可能会出现上面的这种情况了。不过有时候也不必要太担心,因为db都有一个叫优化器的东西,优化器往往能够分析出这种成本,帮你选择一种合理的执行方式。
索引是唯一提升查询速度的因素吗?
这个当然不是了。在《系统性能优化二三事》中我们提到缓存是一种性能优化的方式~。其实这在db查询也是一样的道理,比如mysql服务器会预加载索引和表行数据进到缓存里面,如果缓存已经有了需要的数据,那就不需要读一次磁盘,而我们的磁盘也有一层缓存,如果磁盘缓存里面有需要的数据,也不需要进行一次物理文件的读取。所以缓存的设置也是很重要的。
索引的误区和注意的地方。
1、索引的层级不要超过5层。这条是常见的索引规范,其实这条的规范是有一定的适用范围的,并不是绝对的适用。因为提出这条规范的时候当时的计算机的内存还是非常的小,内存能放的东西非常的有限。如果索引的层级太多,那内存就可能放不下索引,这样读索引就要读一次磁盘,这性能就很差。但现在的计算机内存的容量比当时已经增大了成千上百倍,即使时是超过5层的索引也是可以放到内存里面。索引的层数越多,那过滤的效果就越好,实际读取的表数据就越好。
2、单表的索引数不要超过六个。这个其实也是有适用范围的。提出这个规范的原因一方面是上面提到内存问题,另一个是表频繁更新问题,因为如果更新表的索引列索引也是更新的,索引的更新最终也会写回到磁盘。这就会增加磁盘的负载,影响整个数据库的性能。但如果这个表是不怎么更新的呢,更新频率很低或者不存在瞬间密集的更新,其实建立超过六个的索引也是可以的。
其实索引还有很多东西可以讲,不过要讲清楚的话恐怕还要个十篇八篇才行。。。现在就暂说到这~。后面有时间再陆续分享。
阅读容易,码字不易。如果你喜欢我的文章或者觉得有所收获就请你点下关注或者推荐吧。这样作者才更加有写下去的动力~。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号