
记一次CPU占用率和load高的排查
前不久公司进行了一次大促,晚上值班。大促是从晚上8点多开始的,一开始流量慢慢的进来,观察了应用的各项指标,一切都是正常的,因为这是双11过后的第一次大促,想着用户的购买欲应该不会太强,所以我们的运维同事9点多就回家了在家里面远程支持,留下交易组和其它后端的技术值班,楼主就是交易组的。谁知10点整的时候我们的前置服务器突然告警,报资源占用过高。如下图:

说实话,load超过10还是第一次见。。。。
我是第一个发现情况的,所以我第一时间把告警信息发到群上之后,然后通知运维jstack当时的线程堆栈。就直接登录其中一台服务器用top -c 命令查看占用cpu最高命令的进程。发现是一个进程号为19988的java进程。然后用top -Hp 命令查看下面的线程。然后记录下来
过了几分钟之后收到运维主管发过来的jstack的文件,一个66M的文件。。。。。
然后我用记录下的线程ID去里面查,居然一个都没找到。。。。 后面确认了运维发过的来jstack文件有信息缺失。。。。。
然后看到群上一些技术同事说问题可能是调用IT部门的会员卡查询突然变慢了,响应时间由几十ms变成5s,导致了线程数堆积。这里说一下这个IT部门是我们集团里面的一个老部门和我们部门是独立的,我所在的部门是互联网这一块,IT部门相对来就是传统的那种。IT的系统都是外包来做的,性能真的不敢恭维,已知某个系统的qps是3, 所以技术水平自己脑补。当时我看了一下cat监控,确实有很多查IT会员卡的超时告警,但这个情况是一直都存在的,以前却不会出现这种情况。并且负责会员卡的用户组同事说:他们已经对IT的接口加了限流,如果超时太多,就会限制调用IT的接口的次数,线程堆积的情况应该是不存在的。当时分析了一下就算有很多这种等待io的线程,其现象也应该是load高,但cpu占用率应该不是会太高的。这种cpu高和load高的情况一种很常见的情况就是频繁的GC。我于是再回到cat上面去看监控指标,点heartbeat这一栏。对比各项指标,果然间发现GC的时间和次数在10点的时候突然变多了。
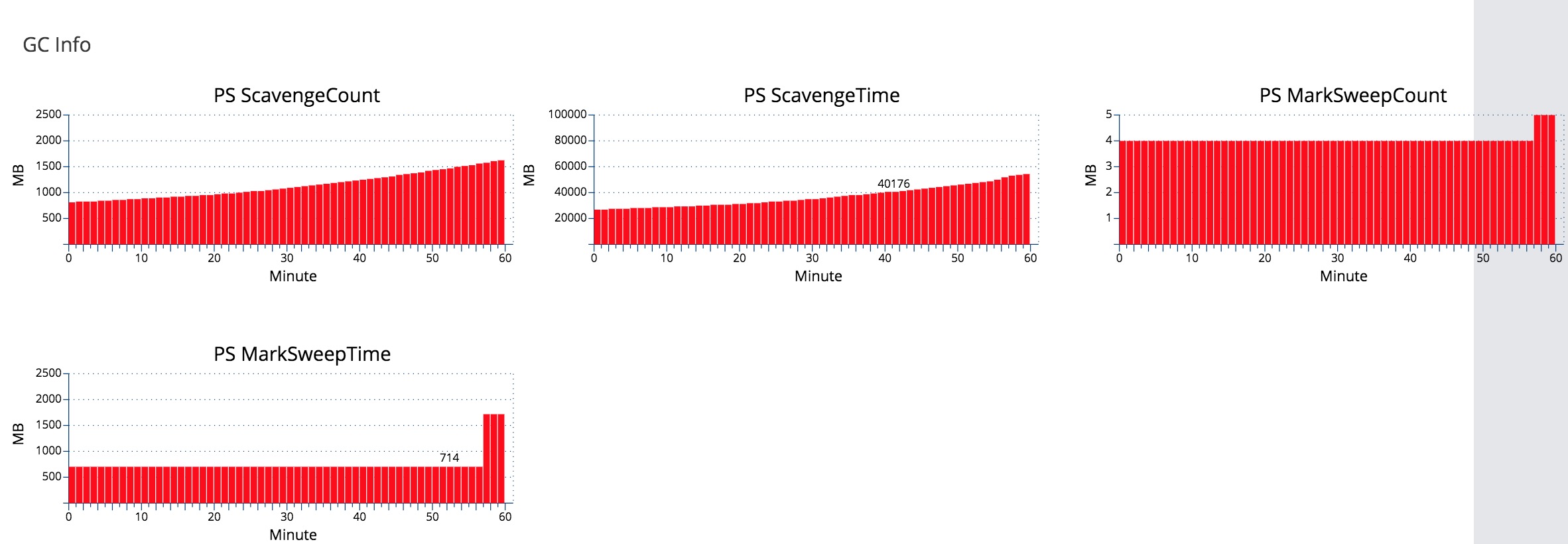
嗯,问题应该是确认了。我于是在有问题机器查找对应的GC日志:
[GC (Allocation Failure) [PSYoungGen: 1321555K->7203K(1354752K)] 2182429K->881391K(4151296K), 0.0216324 secs] [Times: user=0.08 sys=0.00, real=0.02 secs] [GC (Allocation Failure) [PSYoungGen: 1317411K->6176K(1353216K)] 2191599K->882824K(4149760K), 0.0177299 secs] [Times: user=0.06 sys=0.00, real=0.02 secs] [GC (Allocation Failure) [PSYoungGen: 1316384K->7255K(1357824K)] 2193032K->885846K(4154368K), 0.0198454 secs] [Times: user=0.07 sys=0.00, real=0.02 secs] [GC (Allocation Failure) [PSYoungGen: 1323607K->6080K(1356288K)] 2202198K->886357K(4152832K), 0.0194745 secs] [Times: user=0.07 sys=0.00, real=0.02 secs] [GC (Allocation Failure) [PSYoungGen: 1279980K->117750K(1073152K)] 2366227K->1332344K(3869696K), 0.1398088 secs] [Times: user=0.51 sys=0.00, real=0.14 secs] [GC (Allocation Failure) [PSYoungGen: 1073142K->94600K(1176576K)] 2287736K->1409135K(3973120K), 0.1220951 secs] [Times: user=0.47 sys=0.00, real=0.13 secs] [GC (Allocation Failure) [PSYoungGen: 1049992K->105231K(1184256K)] 2364527K->1492688K(3980800K), 0.1323488 secs] [Times: user=0.45 sys=0.00, real=0.13 secs] [GC (Allocation Failure) [PSYoungGen: 1073935K->111730K(1182208K)] 2461392K->1563948K(3978752K), 0.1109970 secs] [Times: user=0.42 sys=0.00, real=0.11 secs] [GC (Allocation Failure) [PSYoungGen: 1080434K->81108K(1197568K)] 2532652K->1607799K(3994112K), 0.1113381 secs] [Times: user=0.42 sys=0.00, real=0.11 secs] [GC (Allocation Failure) [PSYoungGen: 1065684K->79209K(1184768K)] 2592375K->1654630K(3981312K), 0.1410440 secs] [Times: user=0.40 sys=0.00, real=0.14 secs] [GC (Allocation Failure) [PSYoungGen: 1063785K->75484K(1219584K)] 2639206K->1694154K(4016128K), 0.1043986 secs] [Times: user=0.39 sys=0.00, real=0.10 secs] [GC (Allocation Failure) [PSYoungGen: 1106652K->71290K(1209344K)] 2725322K->1727044K(4005888K), 0.0994654 secs] [Times: user=0.38 sys=0.00, real=0.10 secs] [GC (Allocation Failure) [PSYoungGen: 1102458K->74219K(1236480K)] 2758212K->1769216K(4033024K), 0.1000352 secs] [Times: user=0.38 sys=0.00, real=0.10 secs] [GC (Allocation Failure) [PSYoungGen: 1141227K->74573K(1228288K)] 2836224K->1809430K(4024832K), 0.1089653 secs] [Times: user=0.40 sys=0.00, real=0.11 secs] [GC (Allocation Failure) [PSYoungGen: 1141581K->70656K(1250816K)] 2876438K->1842238K(4047360K), 0.1406505 secs] [Times: user=0.38 sys=0.00, real=0.14 secs] [GC (Allocation Failure) [PSYoungGen: 1168384K->95266K(1244672K)] 2939966K->1897805K(4041216K), 0.1442105 secs] [Times: user=0.40 sys=0.00, real=0.14 secs]
果然看到了过了10点,堆内存的使用突然暴涨,应用在频繁的GC,并且每次GC时间基本都在100ms以上。至于具体是什么原因导致的GC现在还没得知,唯一的办法就是dump出当时内存镜像,遗憾的是当时没有及时的dump下来。CPU占用率高和load高的情况只持续了一分钟时间,运维同事也没有dump下来。
要找出原因只能从当时的请求来入手,于是我看当时的应用请求情况。发现GC的的时间点还真的和会员卡的请求突然大量增加和超时基本吻合,于是我来拉下会员卡项目的代码选了其中的会员卡列表和微信卡包列表等相关接口来看一下,还真的发现了一些的问题。其中比较重要的一个是:如果客户端没传分页传参数进来程序就会load用户所有数据出去,之前听说某些用户下面有1000多张会员卡。然后我去看了请求日志发现微信卡包列表的所有请求都没有传分页参数进来,客户端某些版本没有传。并且会员卡列表和微信卡包列表当请求量是平时的几十倍。load用户全部数据,请求量大,这种情况引起GC的概率确实比较大。后面我把了解的情况反馈给了用户组的同事。
总结一下整个过程:从告警到问题定位,中间的几个点其实是可以改进的。
1、jstack文件信息大多,但关键信息却丢失了。原因是jstack是10秒钟才记录一次,所以我记录下来的线程ID和运维给的文件里面的信息里面并不一定对得上。运维同事最好可以提供一下实时工具保留当时的第一手信息。另外如果有什么好用的工具欢迎推荐~。
2、监控不到位。会员卡用的限流组件是阿里最新开源的Sentinel,采用的qps限流并不是线程数限流。所以当时并不知道会员卡相关到底吃了系统多少线程。对于限流组件这块我个人是比较推荐hystrix,因为功能比较齐全,开源时间长,很多坑别人都已经踩过了。阿里的Sentinel刚出来应该很多点还需要完善。另外一点就是GC内存的文件没有及时dump下来。
3、代码规范和code-view。最好接入一些代码检查工具比如sonar,及时找出程序里面一些坑。一些热点代码最好组织一下code-view,这些也可以避免很多线上问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号