
为什么要使用索引?
索引可以避免全表扫描去查找索引,提升检索效率。
什么样的信息能成为索引?
主键,唯一键等能区分数据唯一性的字段都能成为索引。
索引的数据结构?
主流是B+树,还有Hash,Bitmap。其中MySQL数据库不支持Bitmap索引。
密集索引和哈希索引的区别?
索引的优化
1、二叉查找树
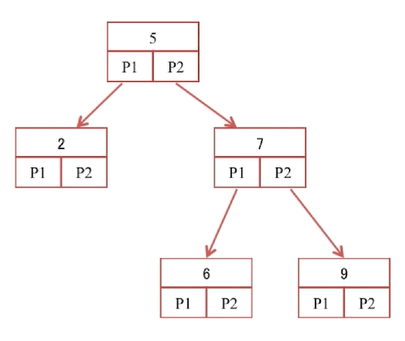
左侧的节点比右侧的节点小。
时间复杂度O(logn)
平衡二叉搜索树
每个节点的左子树和右子树的高度差不超过1
对于n个节点,树的深度是log2n, 查询的时间复杂度是O(log2n) 例如64个节点,最多只要查询6次。
2、B-Tree
定义:
根节点至少包括两个孩子
树种每个节点最多含有m个孩子(m>=2)
除根节点和叶子节点,其它每个节点至少有ceil(m/2) 个孩子
所有叶子节点都位于同一层
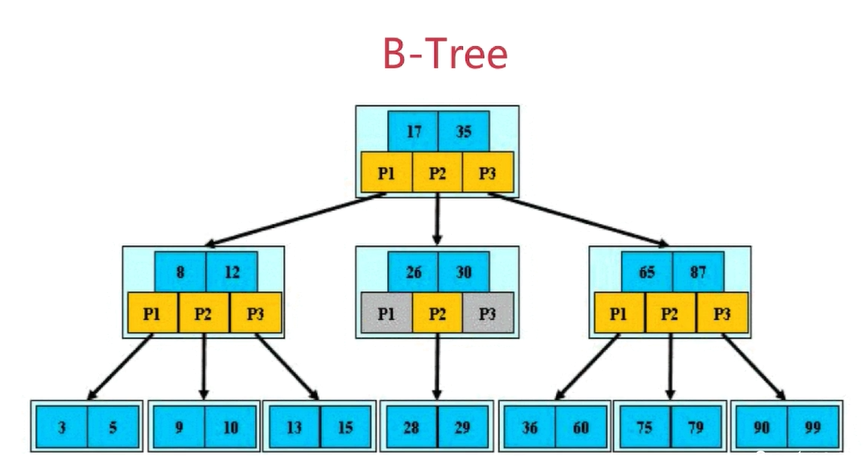
3、B+-Tree
B+树是B树的变体,其定义基本与B树相同,除了
非叶子节点的子树指针与关键字个数相同。
非叶子节点的子树指针P[i], 指向关键字(K[i],k[i+1])的字树
非叶子节点仅用来索引,数据都保存在叶子节点中
所有叶子节点均有一个链指针指向下一个叶子节点
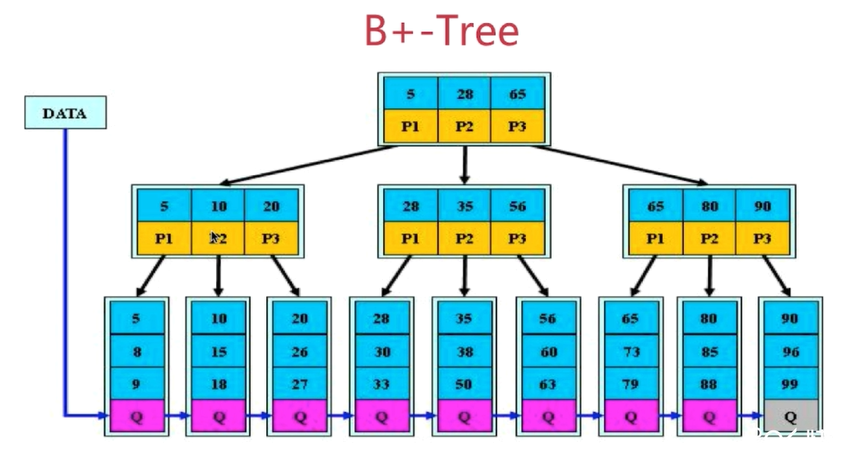
结论:
B+树更适合用来做索引
B+树对磁盘读写代价更低
B+数的查找效率更加稳定
B+数更有利于对数据库的扫描
B-Tree和B+Tree的区别?
1) B+Tree 有n个子节点的节点中含有n个关键字
B-Tree是n个子节点有n-1个关键字
2) B+Tree中,所有的叶子节点中包含了全部关键字的信息,且叶子节点按照关键字的大小自小到大顺序链接,构成一个有序链表
B-Tree的叶子节点不包括全部关键字。
3) B+Tree中,非叶子节点仅用于索引,不保存数据,记录放在叶子节点中。
B-Tree中,非叶子节点既保存索引,也保存数据记录。
B-Tree(B+Tree)特性
完全匹配 index(name) where name = '张三'
范围匹配 index (age) where age > 34
前缀匹配 index(name) where name like '张%' 。 右模糊可以使用索引,左模糊不能使用索引,如'%三'
B-Tree(B+Tree)限制?
index(name, age, sex)
1) 查询条件不包括最左列,无法使用索引。
where age = 34 and sex = 1 无法使用索引。
2) 跳过了索引中的列,则无法完全使用索引
where name = ‘张三’ and sex = 32 跳过了age,只能使用name索引这一列。
3) 查询中某个列的范围(模糊) 查询,则其右边所有列都无法使用索引
where name=‘张三’ and age > 32 and sex = 1 ,只能用name,age两列。
MySQL数据引擎存储方式
1) InnoDB存储方式
B+Tree
主键索引: 叶子节点存储主键及数据
非主键索引(二级索引、辅助索引): 叶子节点存储索引以及主键。
2) MyISAM存储方式
B+Tree
主键/非主键索引的叶子节点都是存储指向数据块的指针。
总结:
InnoDB称为聚簇索引
MyISAM称为非聚簇索引。
4、Hash索引
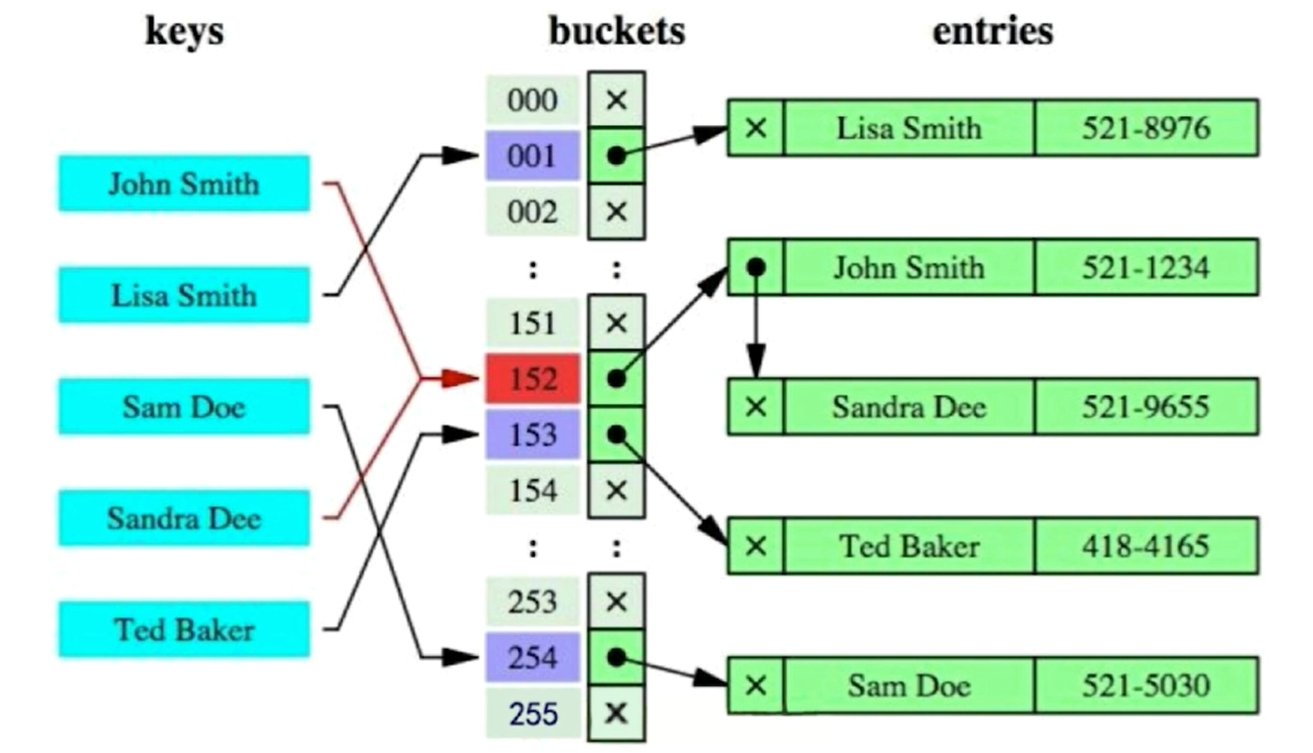
Hash索引特性(缺点):
仅能满足“=”,“IN”,不能使用范围查询,模糊查询
无法被用来避免数据的排序操作。Hash索引并不是按照索引值排序,所以没法使用排序
不能利用部分索引键查询。 hash(a,b) a,b两列的hash所有, where a = 1,只有一列a,
不能避免表扫描
遇到大量Hash值相等的情况后性能不一定就会比B-Tree索引高。一般性能比B-Tree(B+Tree) 要好一些。
Hash冲突越严重,性能下降越厉害。
5、BitMap索引(位图索引)(使用较少)

6、空间索引(R-Tree索引) 使用较少
存储GIS数据,基于R-Tree
MySQL 5.7 开始InnoDB支持空间索引。
7、全文索引
适应全文搜索的需求
MySQL 5.7之前,全文索引不支持中文,经常搭配Sphinx。
MySQL 5.7 起,内置ngram, 支持中文。
全文索引目前用的不多,主要使用ES等搜索引擎。
8、创建索引的原则(原则只是参数,还要根据实际情况)
哪些场景建议创建索引
哪些场景不建议创建索引。
1) 建议创建索引的场景
select 语句,频繁作为where条件的字段
update/delete语句的where条件
需要分组、排序的字段
distinct所使用的字段
字段值有唯一性约束
对于多表查询,联接字段应创建索引,且类型务必保持一致,避免隐式转换。
2) 不建议创建索引的场景
where字句里用不到的字段
表的记录非常少
有大量重复数据,选择性低。如性别字段 (索引的选择性越高,查询效率越好,因为可以在查找的过滤更多行)
频繁更新的字段,如果创建索引要考虑其索引维护开销。(如修改/删除某条数据,相应的要更新索引)
9、可能导致索引失效的场景
1) 索引列不独立。独立是指: 列不能是表达式的一部分,也不能是函数的参数
select * from employees where emp_no +1 = 10003。 这里列emp_no是表达式的一部分,不能使用索引。
解决方法: select * from employees where emp_no = 10002
select * from employees where SUBSTRING(first_name, 1, 3 ) = 'Geo' (first_name是索引列)
解决方法: 预先计算好结果,再传过来,在where条件的左侧,不要使用函数;或者使用等价
select * from employees where first_name like 'Geo%' ;
2) 使用了左模糊
select * from employees where first_name like '%Geo%' ;
解决方法: 尽量避免使用左模糊。如果避免不了,可以考虑搜索引擎去解决。
3) 使用OR查询的部分字段没有索引
select * from employees where first_name = 'Georgi' or last_name = 'Georgi' first_name是索引字段,last_name 不是索引字段。这条SQL不能使用索引。
解决方法: 将last_name 字段添加成索引。
4) 字符串条件未使用'' 引起来。
explain select * from dept_emp where dept_no = 3;
dept_no 是字符型,这里 3没有加单引号, 不能使用索引。 type为All

解决方法: 规范的编写SQL
explain select * from dept_emp where dept_no = '3';

type为ref,可以使用索引。
5) 不符合最左前缀原则测查询
explain select * from employees where first_name = 'Facello'
索引为Index(last_name, first_name) last_name在前面,此时无法使用索引。
解决方法: 将索引的顺序倒一下, 索引为Index( first_name,last_name)。或者Index( first_name)
6) 索引字段建议添加NOT NULL约束
单列索引无法储null值,符合索引无法储全为null的值
查询时,采用is null条件时,不能利用到索引,只能全表扫描
explain select * from users where mobile is null。 (mobile可以允许为空,这条SQL不能使用索引)
解决方法: 把索引字段设置成Not null, 甚至可以把所有字段都设置成not null,并为字段设置默认值。
7) 隐式转换导致索引失效。
where a.Id = b.Id a表id是int,b表id为varchar,则存在隐式转换
解决方法: 创建表的时候要规范,统一为int或varchar。
作者:Work Hard Work Smart
出处:http://www.cnblogs.com/linlf03/
欢迎任何形式的转载,未经作者同意,请保留此段声明!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号