

个人项目:论文查重
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Networkengineering1834 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Networkengineering1834/homework/11146 |
| 这个作业的目标 | 实现论文查重算法,学会使用PSP表格估计,学会 Git commit 规范,学会单元测试 |
1. Github仓库
https://github.com/linjiahui020/paper-check
2. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 15 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 15 |
| Development | 开发 | 465 | 525 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 30 |
| · Design Spec | · 生成设计文档 | 60 | 60 |
| · Design Review | · 设计复审 | 60 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 15 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 180 | 240 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 60 | 60 |
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| Total | · 合计 | 535 | 600 |
3.计算模块接口的设计与实现过程
![]()
![]()
![]()
主方法里通过IOUtils工具类获取源文件和比对文件对应的字符串,然后经过jieba分词库的api调用,将字符串解析成关键词构成的集合。然后通过CosSimilarity类的getSimilarity余弦相似度算法算出源字符串集合和比对字符串集合的余弦值。
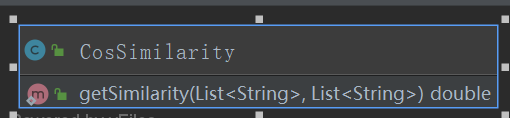
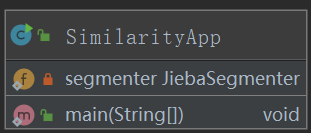
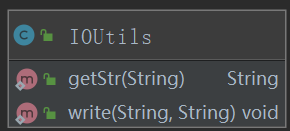
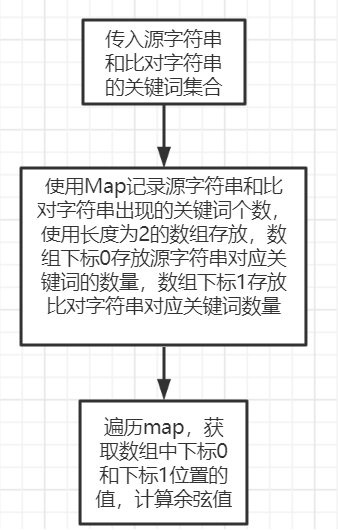
余弦相似度算法:
jieba分词库原理:
- 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
- 动态规划查找最大概率路径, 找出基于词频的最大切分组合
- 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
jieba分词过程:
- 加载字典, 生成trie树。
- 给定待分词的句子, 使用正则获取连续的 中文字符和英文字符, 切分成 短语列表, 对每个短语使用DAG(查字典)和动态规划, 得到最大概率路径, 对DAG中那些没有在字典中查到的字, 组合成一个新的片段短语, 使用HMM模型进行分词, 也就是作者说的识别未登录词。
- 使用python的yield 语法生成一个词语生成器, 逐词语返回。
4.计算模块接口部分的性能改进:

由图可以发现jieba库加载词典,进行分词的时间最多,余弦相似度算法反而占总时间很少
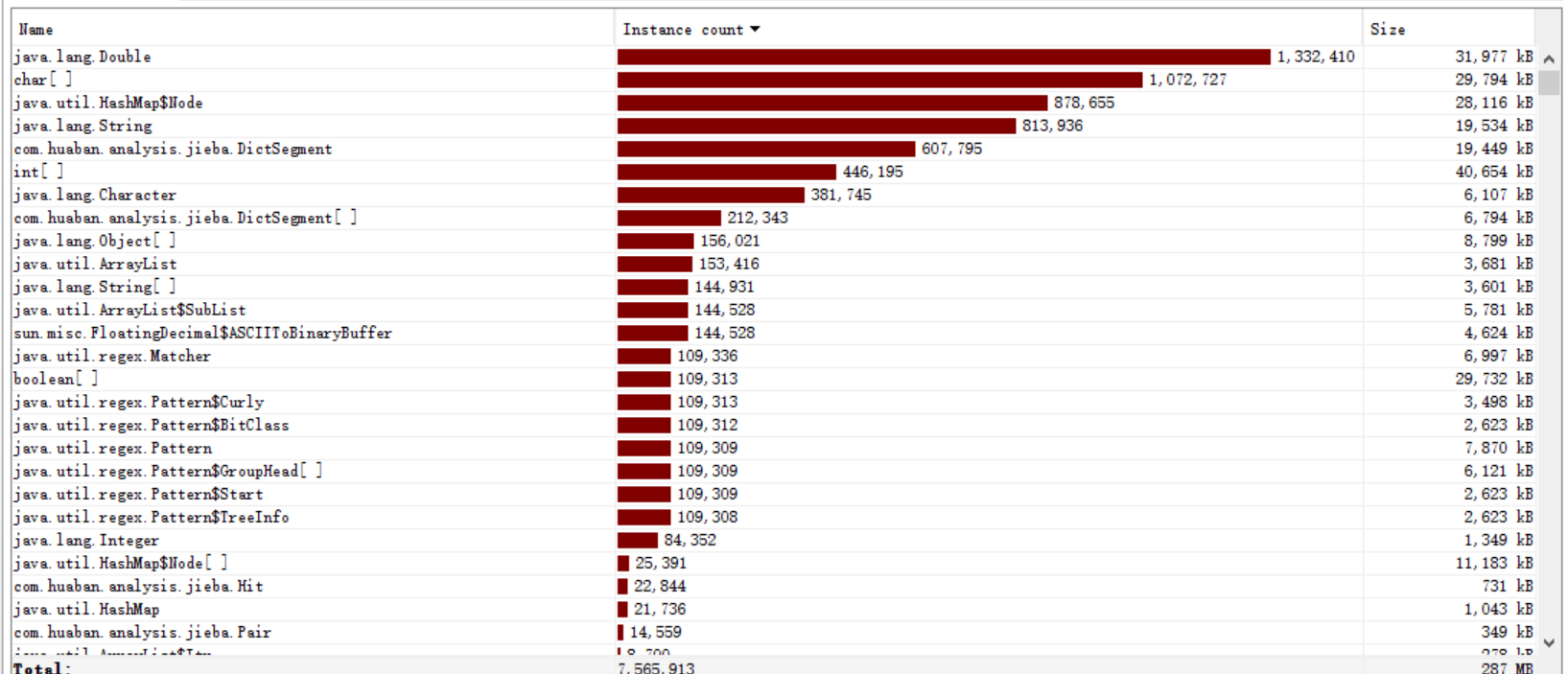
由图可以看出,计算余弦相似度算法时,double类型数据占用空间最多。
运行时间:大致600ms-700ms完成一次查重。

5.单元测试:
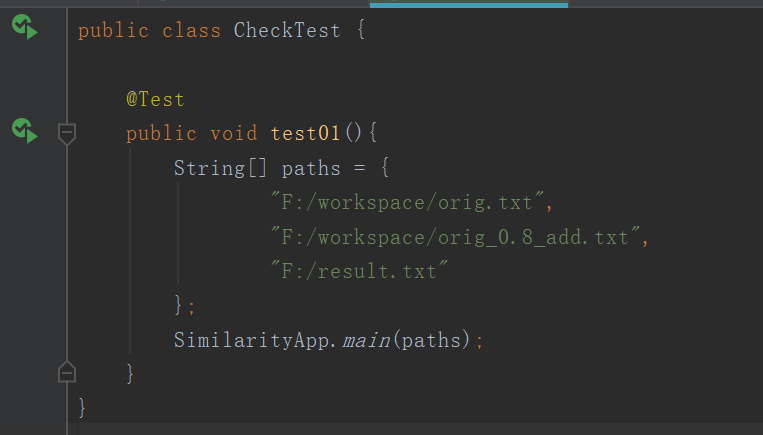
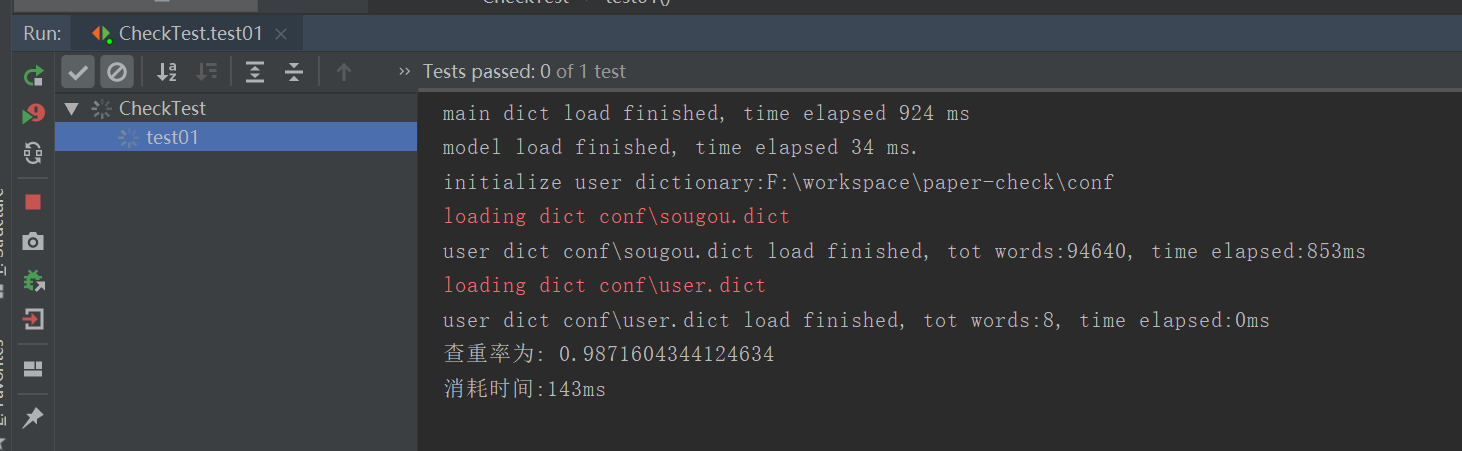
单元测试代码覆盖率:

命令行测试抄袭文本:







命令行测试相同文本:

命令行测试不相关文本:


命令行测试空文本:

输入参数不足三个:

文件路径不存在:

输出文件路径为文件夹:

总结:
- 项目使用了jieba库的jar包进行分词,自行载入自定义词典,虽然用9w多字的词典,但误差仍然很大,光使用余弦相似度算法,与实际查重率偏差较大,所以应该配合其他算法进行查重。
- 使用不同分词器,不同算法会导致同一文本查重率却不一样,所以要根据文本进行合适的算法,分词对查重率的准确也是影响很巨大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号