



作业5 6 7 8 补交原因:忘记交了
作业5
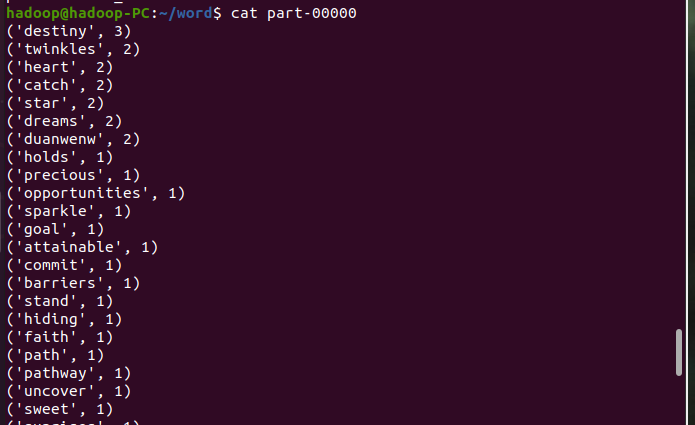
一、词频统计
A. 分步骤实现
准备文件
1.下载小说或长篇新闻稿

2.上传到hdfs上
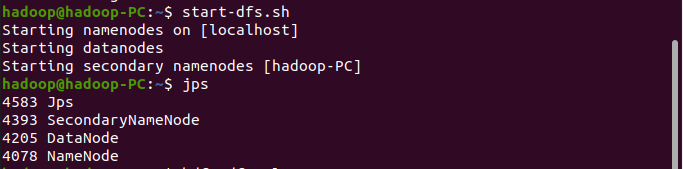
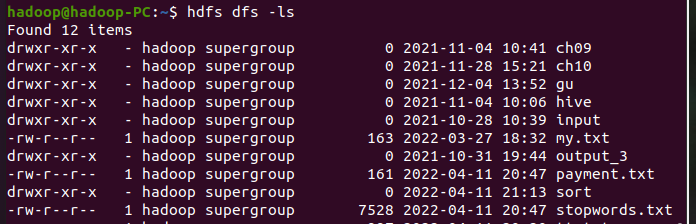
读文件创建RDD

分词
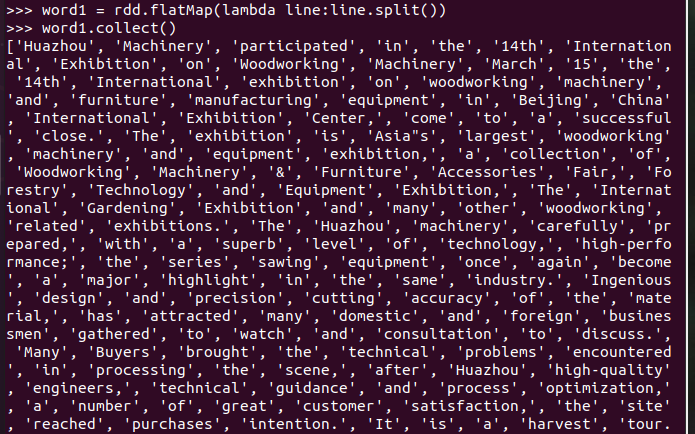
排除大小写lower(),map()
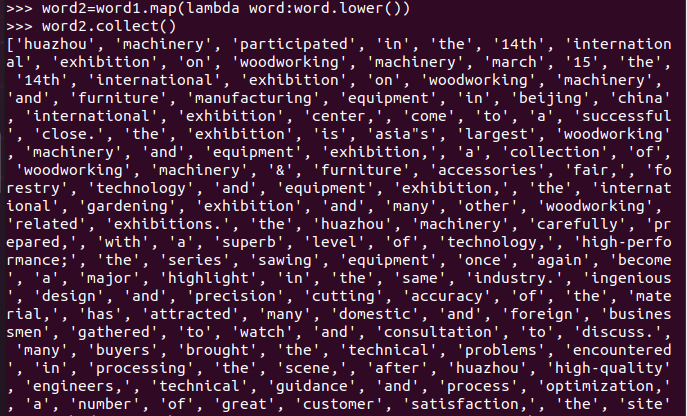
标点符号re.split(pattern,str),flatMap(),
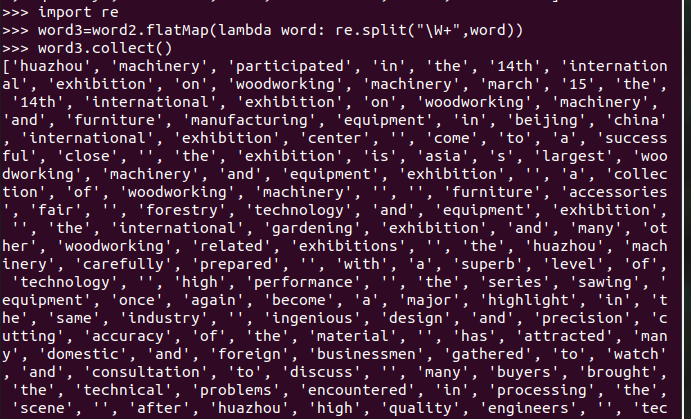
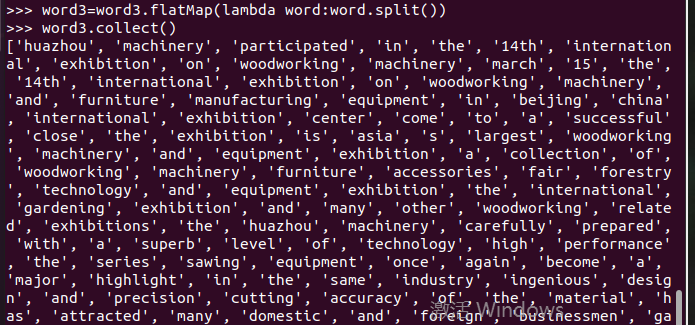
停用词,可网盘下载stopwords.txt,filter(),
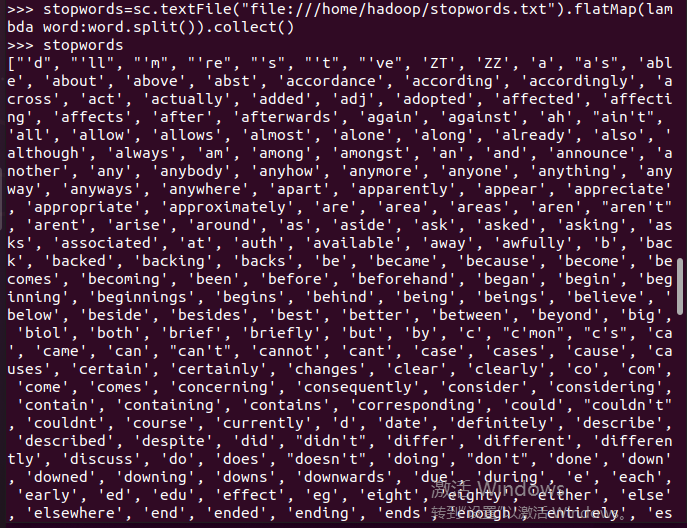
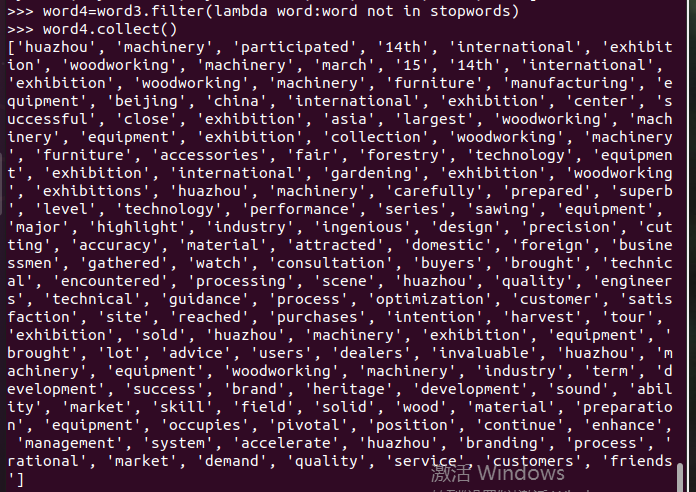
长度小于2的词filter()
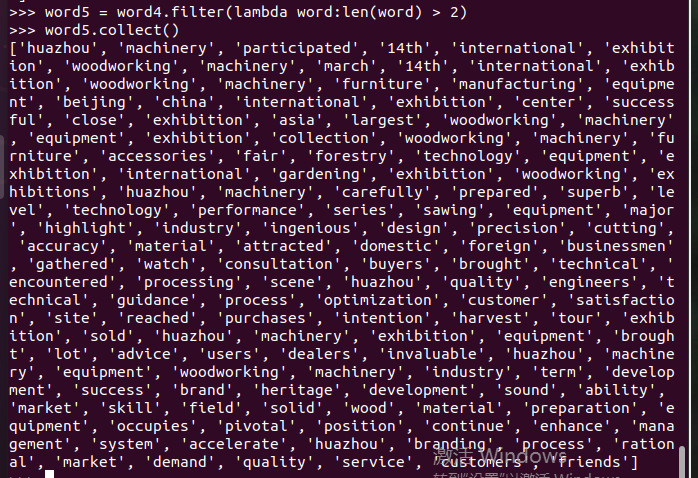
统计词频

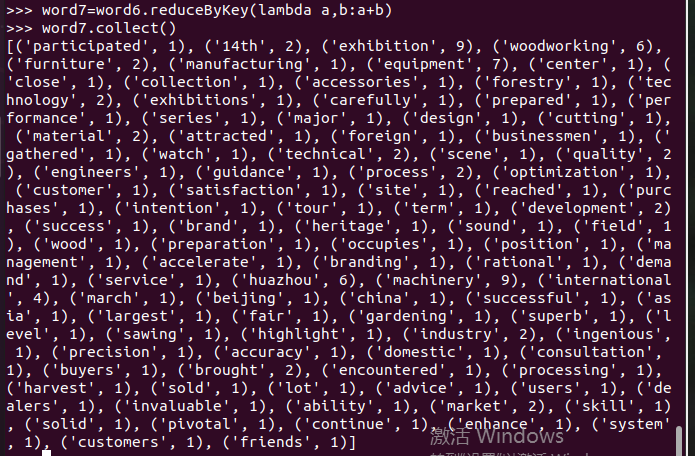
按词频排序
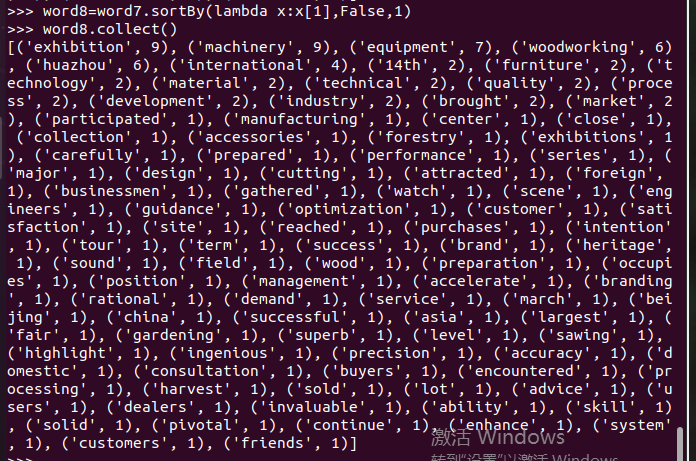
输出到文件

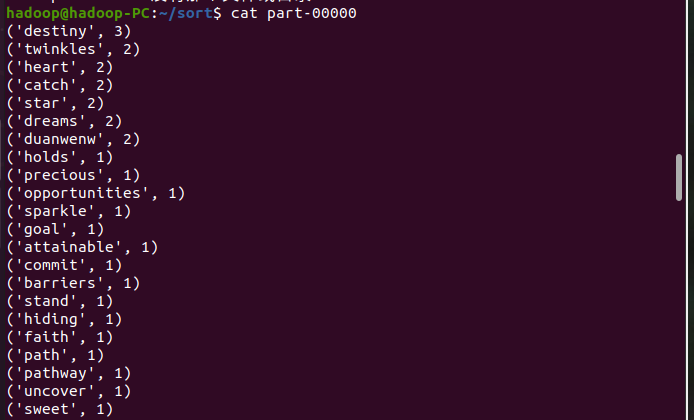
查看结果
B. 一句话实现:文件入文件出

二、求Top值
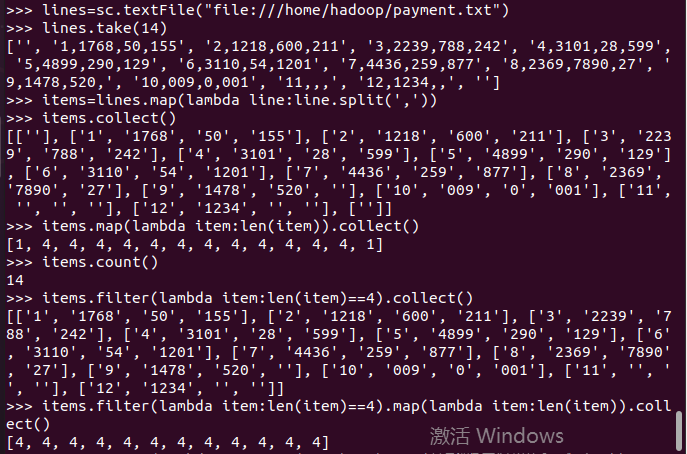
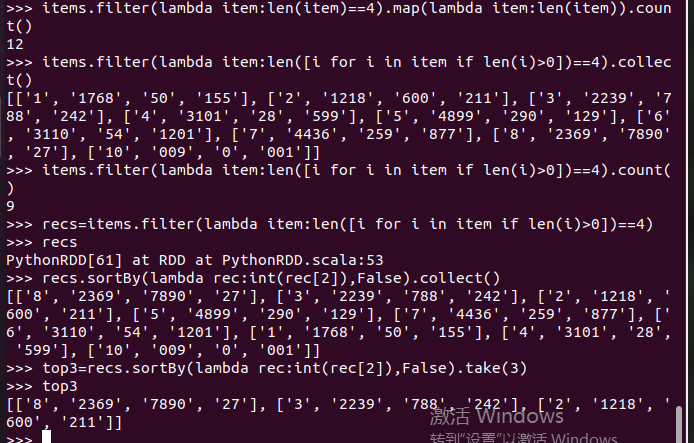
网盘下载payment.txt文件,通过RDD操作实现选出最大支付额的用户。
作业6
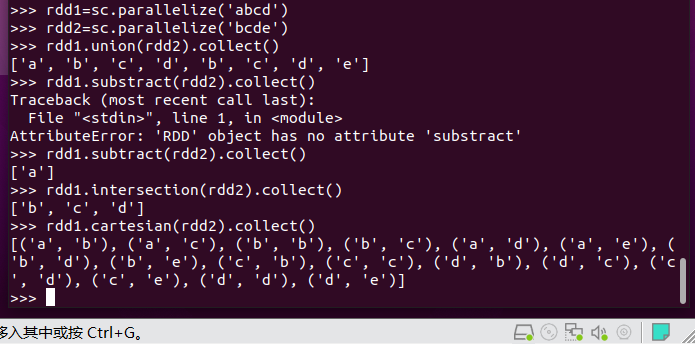
集合运算练习
union(), intersection(),subtract(), cartesian()
内连接与外连接
join(), leftOuterJoin(), rightOuterJoin(), fullOuterJoin()
多个考勤文件,签到日期汇总,出勤次数统计
三、
持久化 scm.cache()


总共有多少学生?map(), distinct(), count()
开设了多少门课程?

生成(姓名,课程分数)键值对RDD,观察keys(),values()

每个学生选修了多少门课?map(), countByKey()
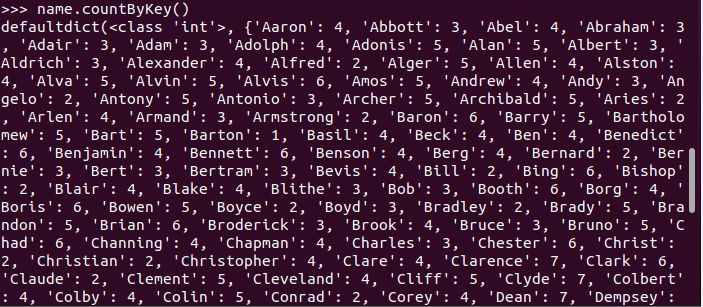
每门课程有多少个学生选?map(), countByValue()


有多少个100分?

Tom选修了几门课?每门课多少分?filter(), map() RDD


Tom选修了几门课?每门课多少分?map(),lookup() list


Tom的成绩按分数大小排序。filter(), map(), sortBy()

Tom的平均分。map(),lookup(),mean()

生成(课程,分数)RDD,观察keys(),values()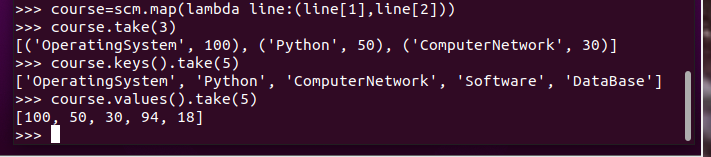
生成(姓名课程,分数)RDD,观察keys(),values()

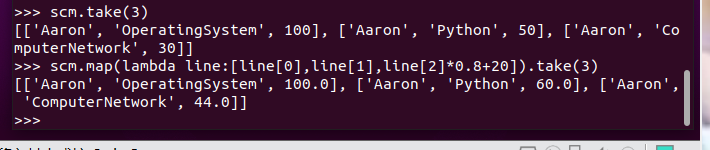
每个分数+20平时分。
分别用mapValues(func)和 map(func)实现。
并查看不及格人数的变化

作业7
.请分析SparkSQL出现的原因,并简述SparkSQL的起源与发展。
答:1.关系数据库已经很流行 2.关系数据库在大数据时代已经不能满足要求•首先,用户需要从不同数据源执行各种操作,包括结构化、半结构化和非结构化数据。其次,用户需要执行高级分析,比如机器学习和图像处理•在实际大数据应用中,经常需要融合关系查询和复杂分析算法(比如机器学习或图像处理),但是,缺少这样的系统。
Spark SQL填补了这个鸿沟:首先,可以提供DataFrame API,可以对内部和外部各种数据源执行各种关系型操作。其次,可以支持大数据中的大量数据源和数据分析算法Spark SQL可以融合:传统关系数据库的结构化数据管理能力和机器学习算法的数据处理能力
2. 简述RDD 和DataFrame的联系与区别?
答:联系:Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询
区别:1.RDD是分布式的Java对象的集合,但是,对象内部结构对于RDD而言却是不可知的 2.DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息
3.DataFrame的创建
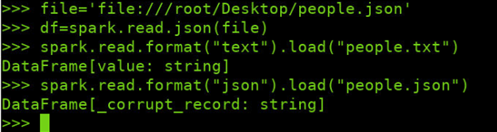
spark.read.text(url)
spark.read.json(url)
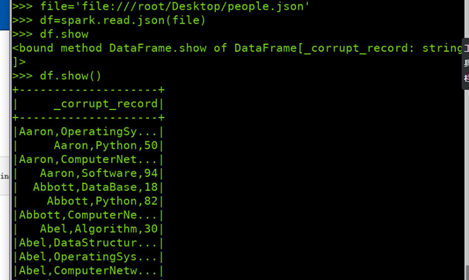
spark.read.format("text").load("people.txt")
spark.read.format("json").load("people.json")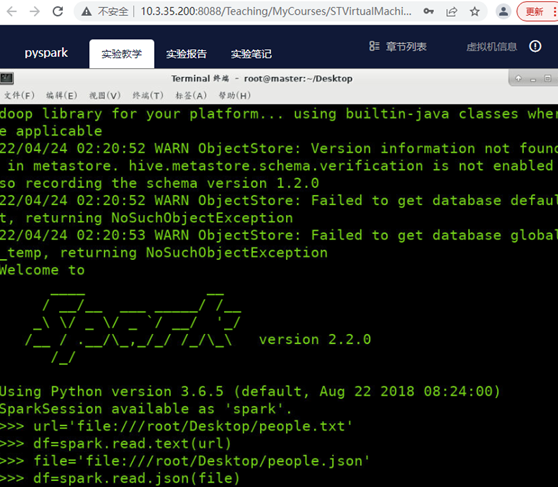
4. PySpark-DataFrame各种常用操作
打印数据 df.show()默认打印前20条数据

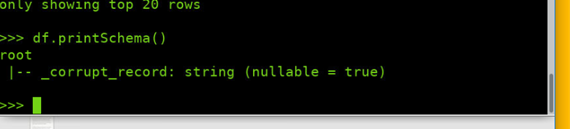
打印概要 df.printSchema()
查询总行数 df.count()

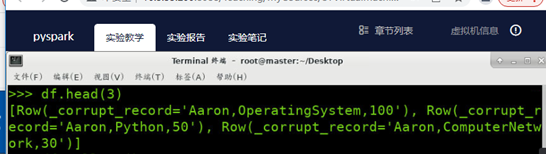
df.head(3) #list类型,list中每个元素是Row类
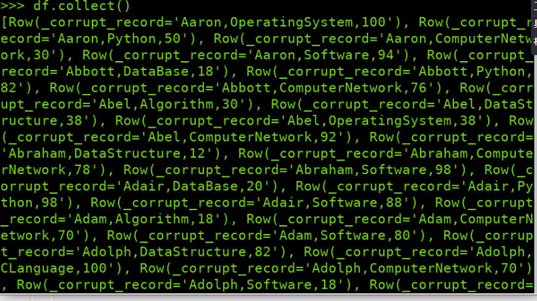
输出全部行 df.collect() #list类型,list中每个元素是Row类
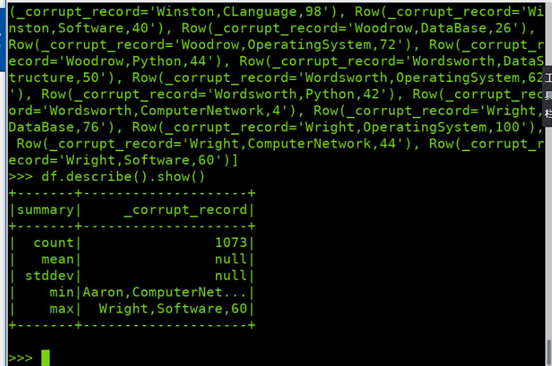
查询概况 df.describe().show()
取列 df[‘name’]df.name
5.Pyspark中DataFrame与pandas中DataFrame
分别从文件创建DataFrame
比较两者的异同
作业8
综合练习:学生课程分数
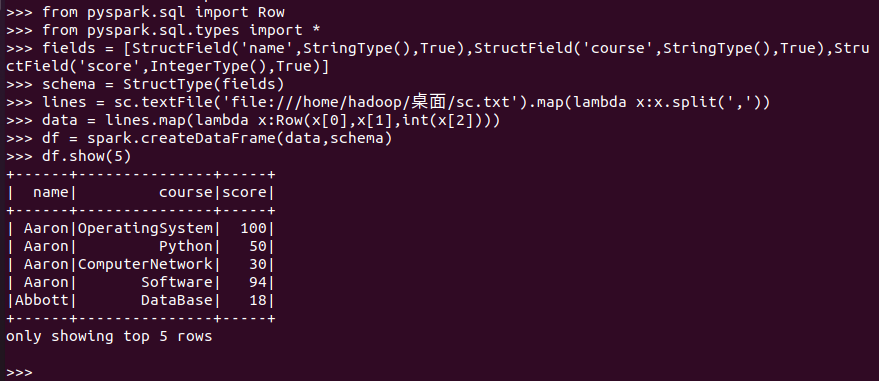
网盘下载sc.txt文件,创建RDD,并转换得到DataFrame。

>>> lines = spark.sparkContext.textFile('file:///home/hadoop/wc/sc.txt')
>>> parts = lines.map(lambda x:x.split(','))
>>> people = parts.map(lambda p : Row(p[0],p[1],int(p[2].strip()) ))
>>> from pyspark.sql.types import IntegerType,StringType
>>> from pyspark.sql.types import StructField,StructType
>>> from pyspark.sql import Row
>>> fields = [StructField('name',StringType(),True),StructField('course',StringType(),True), StructField('age',IntegerType(),True)]
>>> schema = StructType(fields)
>>> lines = spark.sparkContext.textFile('file:///home/hadoop/wc/sc.txt')
>>> parts = lines.map(lambda x:x.split(','))
>>> people = parts.map(lambda p : Row(p[0],p[1],int(p[2].strip()) ))
>>> schemaPeople = spark.createDataFrame(people,schema)
>>> schemaPeople.printSchema()
>>> schemaPeople.show(10)
分别用DataFrame操作和spark.sql执行SQL语句实现以下数据分析:
准备: 创建RDD,并转换为DataFrame;scm持久化;创建spark.sql临时表等预处理:


-
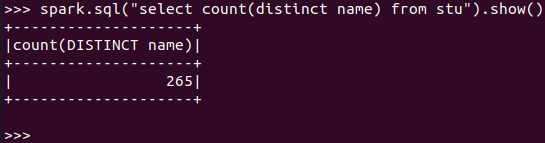
总共有多少学生?
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
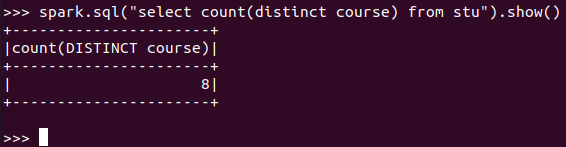
总共开设了多少门课程?
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
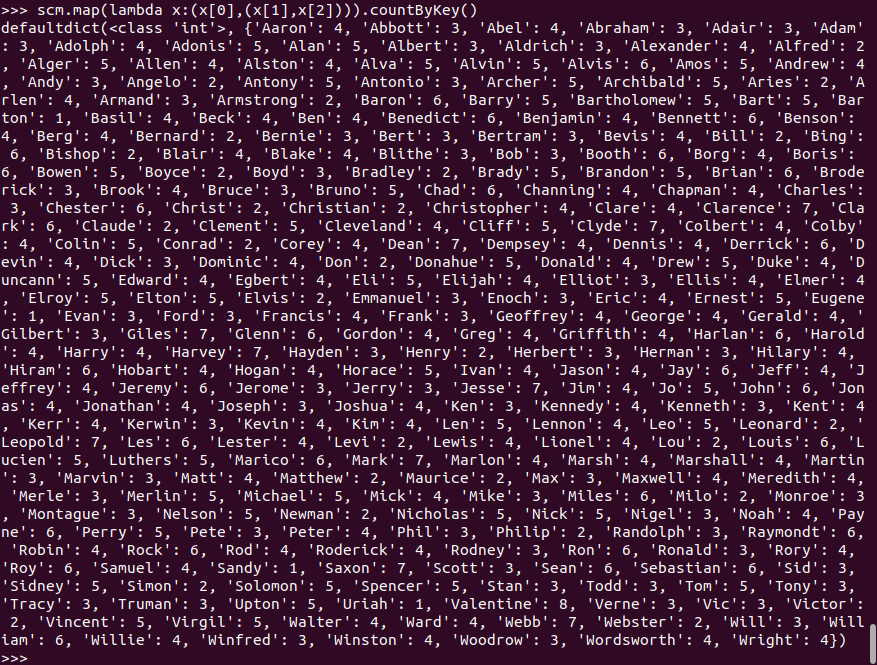
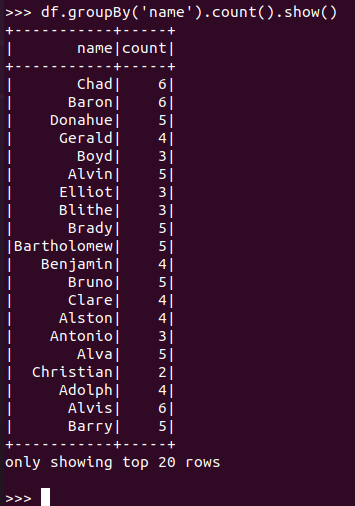
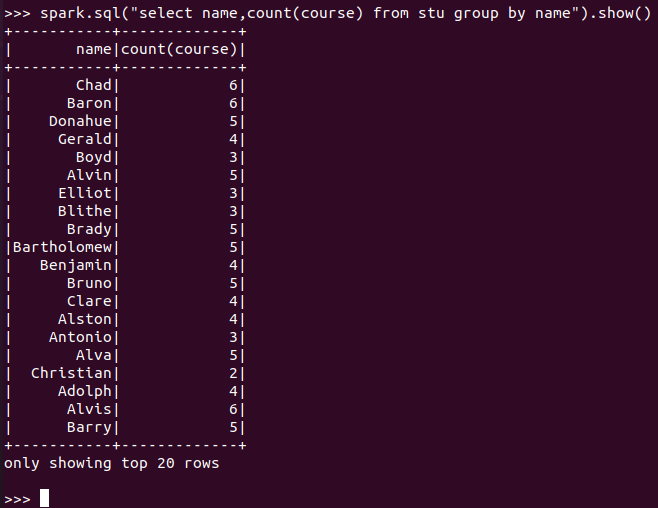
每个学生选修了多少门课?
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
每门课程有多少个学生选?
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
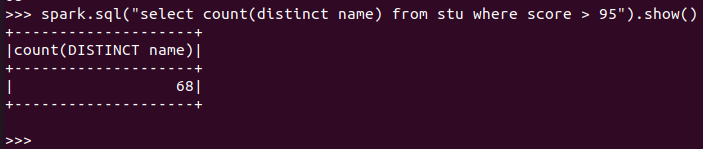
- 每门课程>95分的学生人数
RDD:
DataFrame:
![]()
spark.sql:
![]()
-
课程'Python'有多少个100分?
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
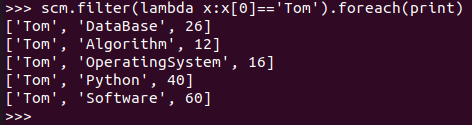
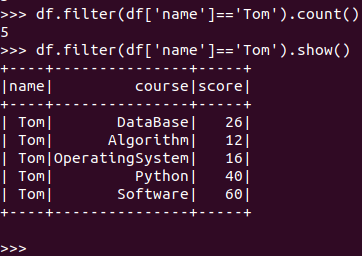
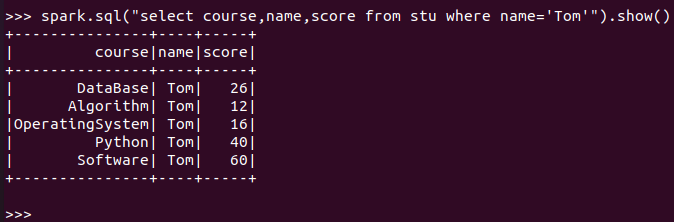
Tom选修了几门课?每门课多少分?
RDD:
![]()
![]()
DataFrame:
![]()
spark.sql:
![]()
![]()
-
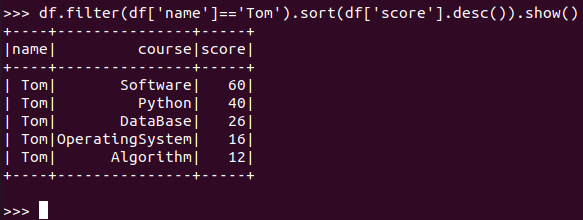
Tom的成绩按分数大小排序。
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
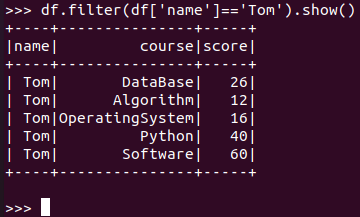
Tom选修了哪几门课?
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
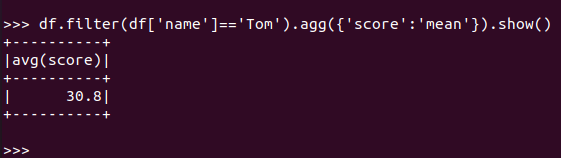
Tom的平均分。
RDD:
![]()
DataFrame:
![]()
spark.sql:(保留了2位小数,round())
![]()
-
'OperatingSystem'不及格人数
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
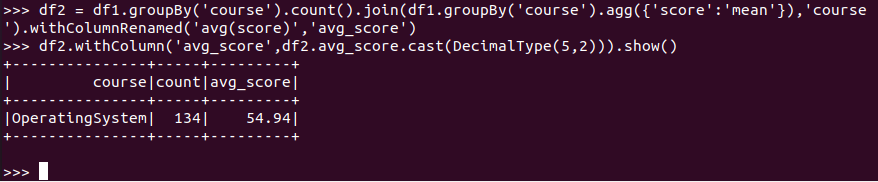
'OperatingSystem'平均分
RDD:
![]()
DataFrame:
![]()
spark.sql:(保留了2位小数,round())
![]()
-
'OperatingSystem'90分以上人数
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
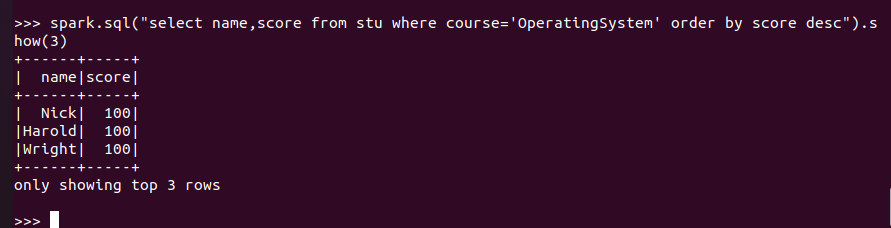
'OperatingSystem'前3名
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
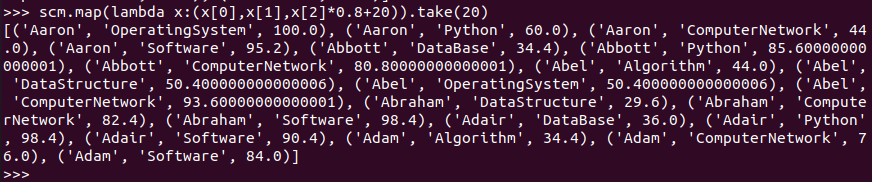
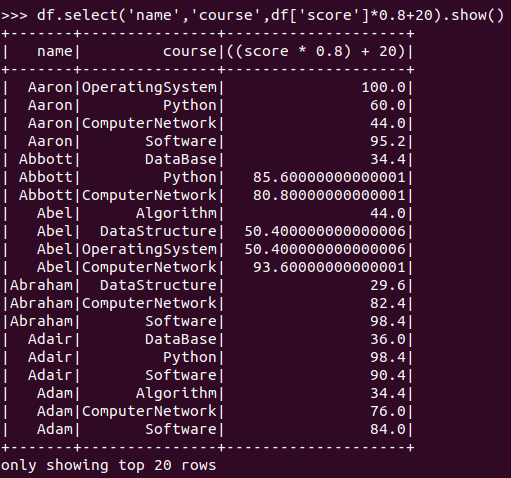
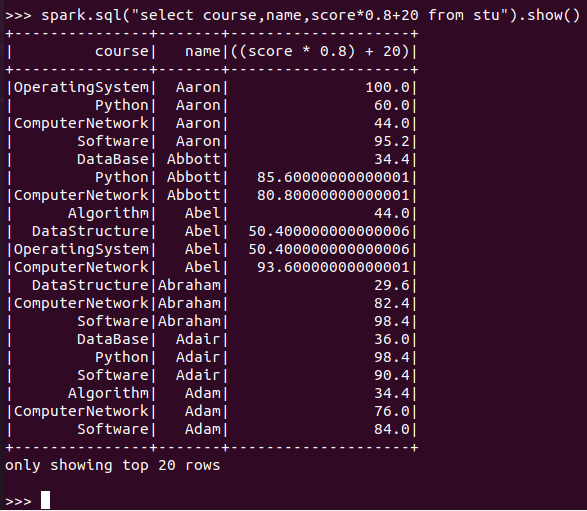
每个分数按比例+20平时分。
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
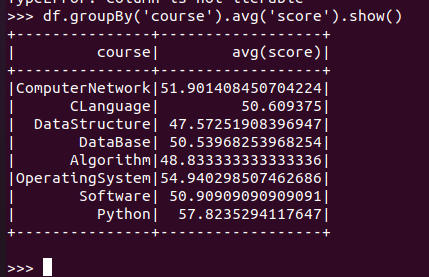
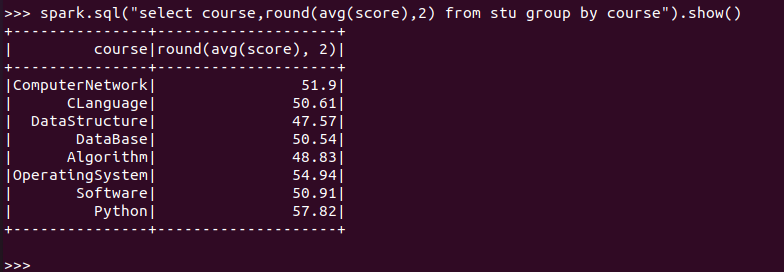
求每门课的平均分
RDD:
DataFrame:
![]()
spark.sql:
![]()
-
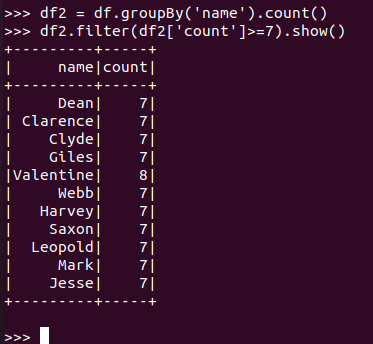
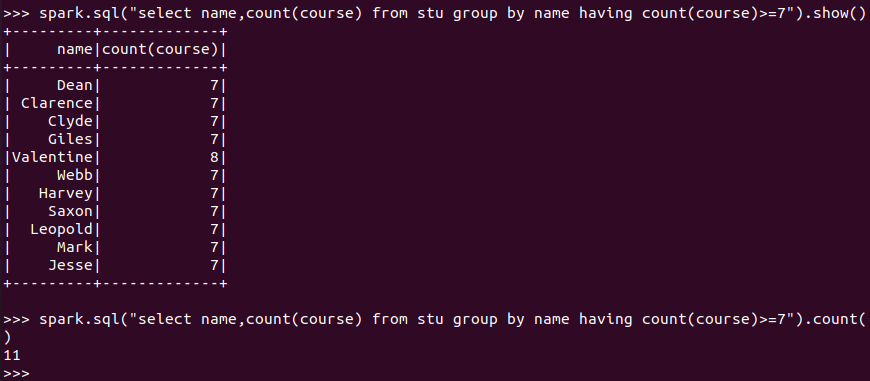
选修了7门课的有多少个学生?
RDD:
DataFrame:
![]()
spark.sql:
![]()
-
每门课大于95分的学生数
RDD:
DataFrame:
spark.sql:
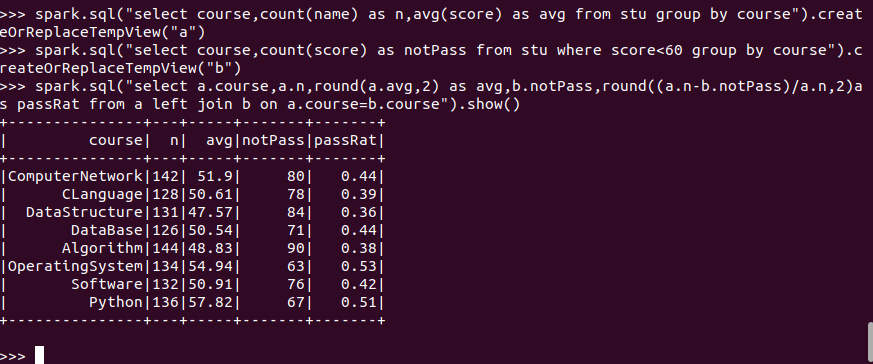
- 每门课的选修人数、平均分、不及格人数、通过率
RDD:
DataFrame:
spark.sql:
![]()































 浙公网安备 33010602011771号
浙公网安备 33010602011771号