
论文阅读 Improving Conversational Recommender Systems via Knowledge Graph based Semantic Fusion

本篇论文选自于ACM SIGKDD 2020。
前言
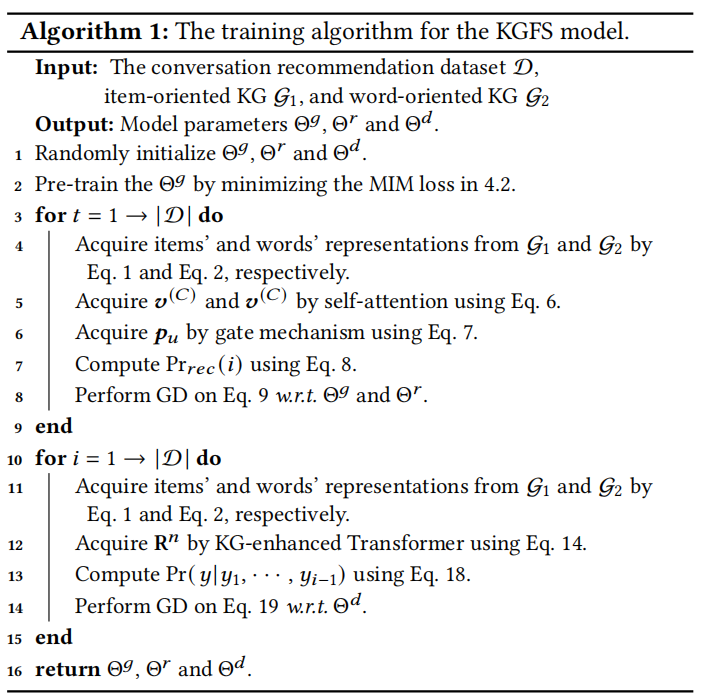
当前,CRS仍然存在两个主要问题:① 会话数据缺乏足够的上下文信息,无法准确理解用于偏好;②自然语言表达于项目级用户级偏好之间存在语义差异。为了解决这个问题,本文提出了word-oriented和entity-oriented两个知识图谱以增强数据表示,并采用Mutual Information Maximization对词层和实体层语义空间进行对齐。进一步的,提出了KG-enhanced recommender组件和KG-enhanced dialog组件。前者用来做精确推荐,后者在回答文本中产生信息关键字或实体。
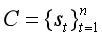 表示,其中st是第t轮对话句子。每一轮对话中,推荐组件选择一系列候选项It,对话组件会产生下一和表达st作为回应。当然It可以为空。对话组件可以生成一个更为清晰的问题后者产生一个闲聊回应。推荐系统最终会生成的回应包括推荐集It+1或回应语句sn+1。
表示,其中st是第t轮对话句子。每一轮对话中,推荐组件选择一系列候选项It,对话组件会产生下一和表达st作为回应。当然It可以为空。对话组件可以生成一个更为清晰的问题后者产生一个闲聊回应。推荐系统最终会生成的回应包括推荐集It+1或回应语句sn+1。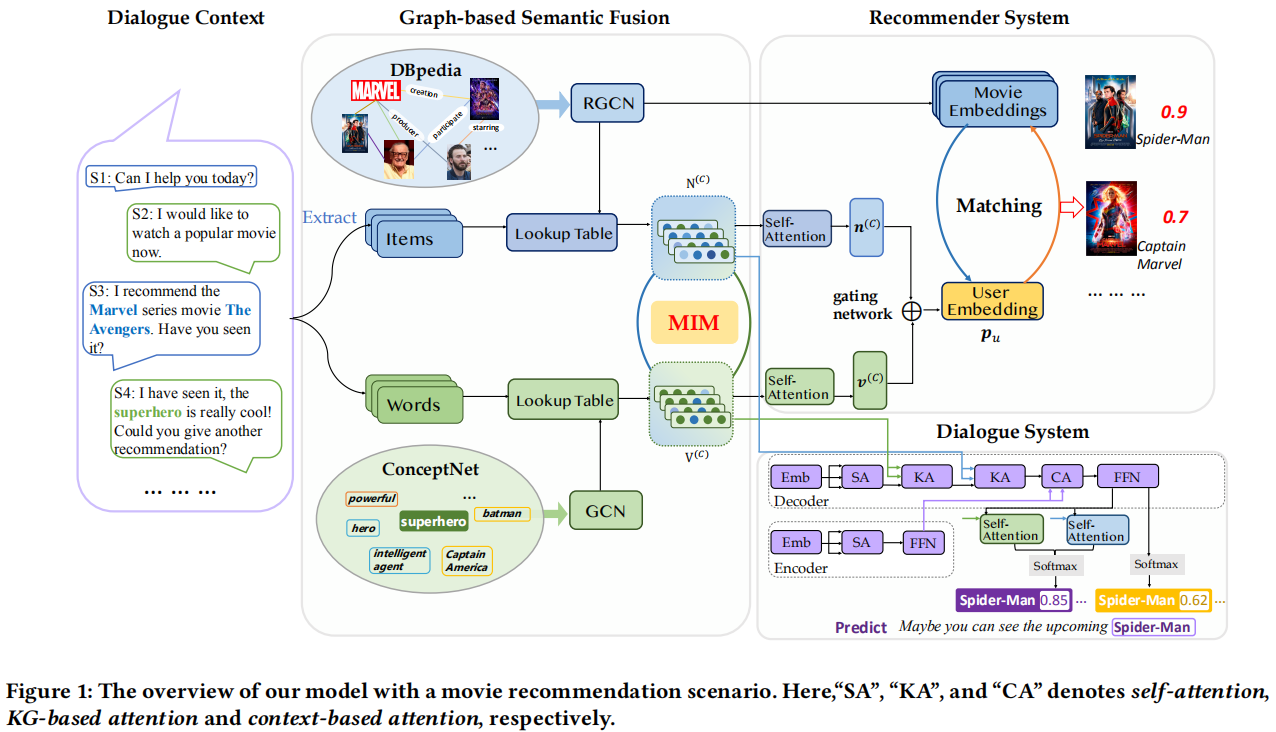
4.1 Encoding External Knowledge Graphs
将对话系统和推荐系统中基本语义单元分别定义为word和item,使用两个独立的知识图谱来增强两种语义单元的表达。采用MIM loss对第4.1.1节和4.1.2节中GNN模型的参数进行预训练。
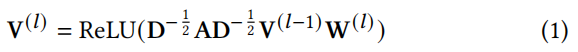
 。通过堆叠多个卷积,信息可以沿着图结构一起传播。算法结束时,获取一个单词的表示nw(dw维)。此时不需要包含关系信息。
。通过堆叠多个卷积,信息可以沿着图结构一起传播。算法结束时,获取一个单词的表示nw(dw维)。此时不需要包含关系信息。4.1.2 Encoding Item-oriented KG
采用DBpedia作为Item-oriented KG。DBpedia的三元组可以表示为<e1,r,e2>,其中e1,e2∈ε是实体集ε中的项目或实体,r是关系集R中的entity relation。
采用R-GCN来提取子图上是项目表示。节点e在(L+1)层的表示计算为:
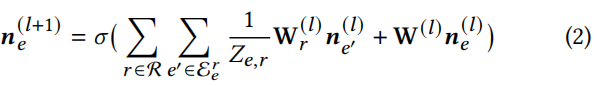
其中,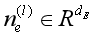 是节点e在第l层的表示;
是节点e在第l层的表示;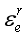 表示节点e在关系r下的邻接节点集;
表示节点e在关系r下的邻接节点集;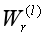 是一个特定的变换矩阵,对于具有r关系的相邻节点的嵌入;W(l)是一个可学习的矩阵,用于变换第l层节点的表示形式;Ze,r是一个归一化因数(normalization factor)。
是一个特定的变换矩阵,对于具有r关系的相邻节点的嵌入;W(l)是一个可学习的矩阵,用于变换第l层节点的表示形式;Ze,r是一个归一化因数(normalization factor)。
从4.1已经得到Word-oriented 和Item-oriented 的KG的节点表示,并分别用嵌入矩阵V(vw表示词w)和N(ne表示项目e)表示。为弥补word与item之间的语义鸿沟,本模型采用了Mutual Information Maximization technique(简称MIM),使用MIM相互地增强成对信号的数据表示。给定两个变量X,Y,那么MI可以被定义为:
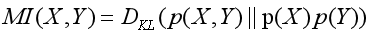 (3)
(3)
其中,DKL(P|Q )用于度量同一概率空间两个概率分布P、Q之间的距离。也就是说 DKL为 X和Y 联合分布和边缘分布点积之间的KL散度。互信息的准确数值通常很难计算得到,通常转化为计算其下界,通过抬高互信息下界值来间接使得互信息最大化:
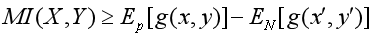 (4)
(4)
其中Ep[ ]和EN分别代表正样本对(共现word-item对)和负样本对(随机word-item对)的得分期望,g( )是二元分类函数。
对于对话中的entity-word对,通过矩阵转换使其表示更接近:
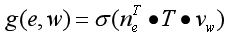 (5)
(5)
其中,ne和vw是已经学习到的对entity e和word w节点表示,T∈RdE×dW用于对齐语义空概念的转换矩阵。将公式(5)带入公式(4)可以得到目标损失函数,并通过优化算法使损失最小化。
为了提高性能降低影响度,本模型引入了super token——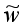 ,假设他能够表示它能够代表上下文单词的整体语义。使用g( )函数建模实体与super token之间的关系,利用自注意力机制学习super token的表示:
,假设他能够表示它能够代表上下文单词的整体语义。使用g( )函数建模实体与super token之间的关系,利用自注意力机制学习super token的表示:
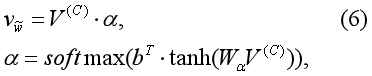
V(C)是会话中所有上下文单词的嵌入矩阵,α是反应每个单词权重的注意向量,Wα和b是参数矩阵和学习向量。
4.3 KG-enhanced Recommender Module
本节考虑如何在CRS中生成一组推荐item。假设之前的交互记录是不存在的。我们只能利用对话数据来推断用户的偏好。
首先,我们收集对话c中出现的所有单词。通过一个简单的查找操作,我们可以得到4.2节中通过图神经网络学习到的词或项的嵌入。我们将单词嵌入连接到矩阵V(C)中。类似地,我们可以通过组合项的嵌入得到项嵌入矩阵N(C)。利用公式6,学习每个单词向量v(C)和单个项目n(C)。利用 gate mechanism 推导用户u的偏好表示pu:
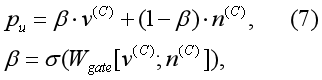
已知用户偏好,计算给用户推荐item i的概率:
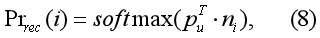
利用公式(8)对item排序后推荐给用户,使用交叉熵损失函数学习参数:
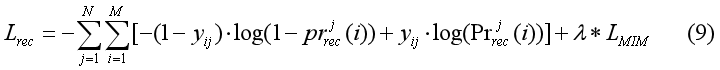
j为对话索引编号,i为item索引编号,LMIN为Mutual Information Maximization loss,λ为加权参数矩阵。
4.4 KG-enhanced Response Generation Module
本节主要考虑在CRS中如何生成一个回复。采用Transformer来构建一个encoder-decoder架构。encoder遵循标准的Transformer结构,采用KG-enhanced 解码。在自注意力子层后,我们使用了两个基于知识图谱的注意力层融合两个知识图谱的信息:
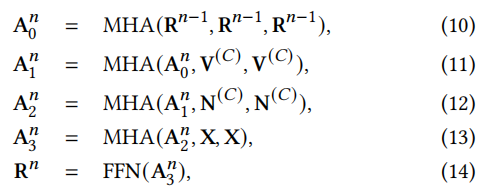
其中MHA(Q,K,V)是the multi-head attention function,FFN(x)是一个前反馈的全连接层,由一个带有ReLU激活层的线性变换组成。X为编码器输出的嵌入矩阵,V(𝐶)和N(𝐶)是一段对话中单词和项目的KG-enhanced的表示矩阵𝑐。
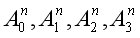
分别是self-attention、ConceptNet内嵌的cross-attention、DBpedia内嵌的cross-attention和encoder output的cross-attention。Rn
是来自第n层解码器的嵌入矩阵。
与标准的变压器解码器相比,我们在Eq. 11和12中增加了两个步骤。这个想法可以用一个转换链来描述:
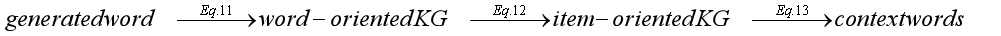
给定预测的子序列𝑦1,···,𝑦𝑖∀1,生成𝑦𝑖作为下一个令牌的概率为:
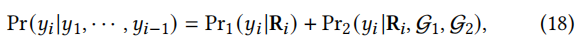
其中,Pr1(·)是将解码器输出Ri(式14)作为输入,作为词汇表上的softmax函数实现的生成概率,Pr2(·)是遵循标准复制机制在两个KGs节点上实现的复制概率,G1、G2表示我们使用的两个KGs。
回复生成模块的交叉损失函数如下:
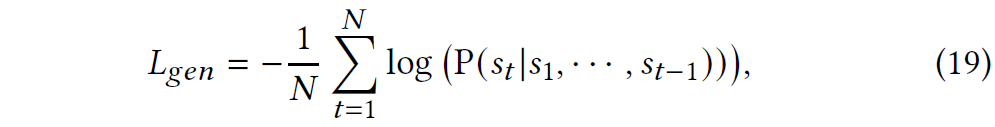
数据集:the REcommendations through DIALog (REDIAL) dataset,本数据集是通过Amazon Mechanical Turk (AMT)构建的。数据集按8:1:1的比例分割为训练集、验证集和测试集。
Baselines:从推荐模型和对话模型进行对比。
评价指标:采用不同的指标评价推荐任务和对话任务。采用Recall@k(k=1,10,50)和冷启动。
实验安排:采用pytorch安排实验,模型代码:https://github.com/RUCAIBox/KGSF。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号