综合实践
综合实践:NEZHA: Efficient Domain-Independent Differential Testing
一、前言
-
NEZHA是一个高效的、独立于领域的差异测试工具。
-
引入了δ-多样性,有效地指导差异测试的输入生成过程。
-
NEZHA能够在复杂的现实世界软件(如SSL/TLS库、PDF查看器和ClamAV恶意软件检测器)中发现之前未知的语义差异和安全漏洞
二、原理
- 假设A和B是两个不同的程序具有类似功能:验证输入文件的版本号是否有效。结果为0表示有效版本号,结果为负数(-1或-2)表示错误版本号。NEZHA采用以种子输入语料库开头,对语料库中的每个输入应用突变,每次为进一步的突变选择表现最佳的输入。NEZHA建立在这种差异多样性的概念之上,利用两个不同的δ-多样性黑盒引擎和灰色引擎。

2.1灰盒指导
如果程序内部设备可以得知的,就可以为每个输入从测试程序收集运行时详细的执行信息。
假设初始测试文件语料库,即种子语料库由三个输入文件组成,版本号分别为7,0和1 (I0 ={7,0,1})。我们从I0中随机抽取一个输入来开始我们的测试。
-
假设选择了v=7,输入 checkVer_A和checkVer_B中。由图1流程图可得程序A和程序B执行时分别访问的唯一边序列为{A1}和{B3, B2}。对于A和B,覆盖的边缘数量分别为1和2,而在两个程序中实现的覆盖范围是1 + 2 = 3。朝着有利于增加覆盖范围的输入进行突变,即往先前未出现的边缘突变,推动输入生成过程。可知v=7增加了代码覆盖率,所以被添加到将用于下一代的语料库中:I1 ={7}。
-
在第二阶段的测试中,选择从当前种子语料库种选择剩下的输入A和B中,假设选择v = 0,程序A和程序B的边缘分别为{A3,A2}和{B1},之前未出现过。因此选择进一步突变,下一代语料库变为:I1 = {7,0}。
-
选择输入v=1。程序A和程序B的边缘分别为{A1}和{B1},A1和B1边都被再次访问过,这种输入并没有增加覆盖率,因此v=1没有被添加到I1中,也不会被考虑为未来的突变。
但是,输入v=1,通过一个单一的增量突变,可以被转换为揭示程序A和程序B之间的差异的输入。这个例子表明,简单地最大化边缘覆盖通常会错过可能触发语义错误的输入。相比之下,如果我们在过去的迭代中使用路径元组来跟踪访问多样性,则输入 v=1将调用路径元组<{A1},{B1}>,作为一对组合,这是以前从未见过的,不会被丢弃。因此,使用路径δ-多样性状态,而不是代码覆盖,在v=1的结果被考虑为进一步的突变。
2.2黑盒指导
如果程序设备或二进制重写是不可行的选项,即程序内部设备不可见,则采用黑盒指导。主要是观察被测程序的输出寻找以前未曾出现的模式。
假设输出被传递到NEZHA是例程checkVer_A和checkVer_B返回的值。如果输入0,7和1传递给程序A和B,NEZHA将使用到目前为止看到的所有唯一输出元组更新其内部状态{<-1,-1>,<-2,-2>,<-1,-2>},任何新的输入会导致之前没有看到的元组,都将被考虑为将来的突变,否则它将被丢弃。例如,对于前面提到的输出元组集合,输入2将产生元组<0,-2>,将被考虑为未来的突变,但输入9导致<-1,-2>,已经存在,就会被丢弃。
三、研究方法
3.1 核心算法
NEZHA的核心引擎:查找n代以后所有应用程序的差异。在每次测试中,NEZHA检查不同的输入是否导致测试程序中未曾出现的相对执行模式。其算法描述如下:
1)对一组应用程序A执行固定代数(n)的测试。
2)从一组初始种子随机选择i,然后对i进行突变。
3)将其与A中的每个程序进行测试。
4)每个应用程序的记录执行路径和输出被添加到当前生成期间观察到的总路径和输出的集合中。
5)如果NEZHA确定在该输入执行期间观察到新的执行模式,则它将相应的输入添加到输入语料库,其将用于产生下一代语料库。
6)如果测试应用程序的输出存在差异,NEZHA会将相应的输入添加到总差异集合中。是否在每一代中观察到差异取决于测试程序的输出:如果至少一个应用程序拒绝输入,并且至少一个其他应用程序接受它,则记录差异。即他们输入相同在一组应用程序A中输出不同,则记为差异。
3.2 灰盒δ-多样性
1)粗略的路径δ-多样性:给定一组程序P在输入i下执行,设PC p,i为路径基数元组<|pathp1,i|, |pathp2,i|,…,|pathp|p|.i|>。每个PCp,i表示在输入i情况下,每个程序访问边总数。在整个测试中,从初始输入语料库i开始,所获得的总体的粗略路径δ-多样性是包含所有上述元组的集合的基数。尽管上述提供了语义上更丰富的执行表示,但与总边缘覆盖相比,它构成了(实际)执行路径的粗略近似。如果要考虑具体地访问了哪些边缘,则可以实现更精细的执行表示。
2)更精细的路径δ-多样性:路径pathp,i,保存了每个程序pk∈P在输入i下执行时所访问的所有边。设置path_setp,i,由pathp,i的所有唯一边组成,因此path_setp,i不包含重复边,而只包含在执行过程中至少被访问过一次的边。给定一组程序P在输入i下的精细的路径δ-多样性是:PDp,i=<path_setp1,i, path_setp2,i,…,path_setp|p|,i>,PDp,i充当了所有测试程序中输入i执行的“指纹”,并封装了应用程序执行路径中的相对差异。对于整个测试来说,从初始输入语料库I开始,得到的精细的路径多样性为包含所有上述元组的集合的基数。
3)举例说明:An, Bn分别表示A和B 的边,假设给定的某个输入导致了A和B的执行路径分别为<A1,A2,A1>和
3.3 黑盒δ-多样性
输出δ-多样性:假设P是一个程序,给定输入i,生成输出Op,i。将程序P的输出多样性定义为元组,只执行一个输入i,ODP,i = <op1,i, op2,i, ..., op|p|,i>。在从输入语料库I开始,输出集跟踪在P中所有程序执行输入i时观察到的惟一输出元组的数量。
四、设计与实验过程
4.1设计
NEZHA的架构如下图所示,由两个主要组件组成:核心引擎和运行组件。运行时组件为NEZHA在δ-多样性指导下收集所有必要的信息,并将其传递给核心引擎。核心引擎通过突变生成新的输入,并根据其δ-多样性指导更新输入语料库。其中仪器模块为灰盒指导测试时,收集每个测试输入的执行路径上的信息。
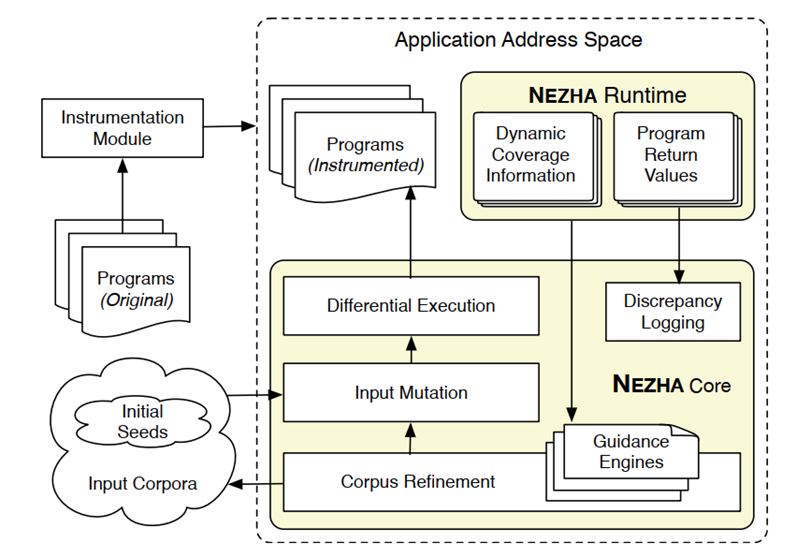
4.2实验过程
NEZHA如何使用输入以及各个组件如何互操作的示例。其步骤如下:
1)从语料库中选择一个输入开始。
2)修改输入,通过LLVMFuzzerTestOneInput将其分发给被测试的程序。
3)通过调用NEZHA_TestStart为每个被调用的应用程序初始化它所有的记账数据结构。
4)调用被测试的特定于程序的功能。
5)对临时记账数据进行初始化。
6)指定的API调用被发送回NEZHA引擎,提供在NEZHA库之间传递输出值和路径执行信息的接口
7)使用的δ-diversity决定是否将输入添加到语料库中以进行进一步测试。
8)如果是,将输入添加到语料库中。
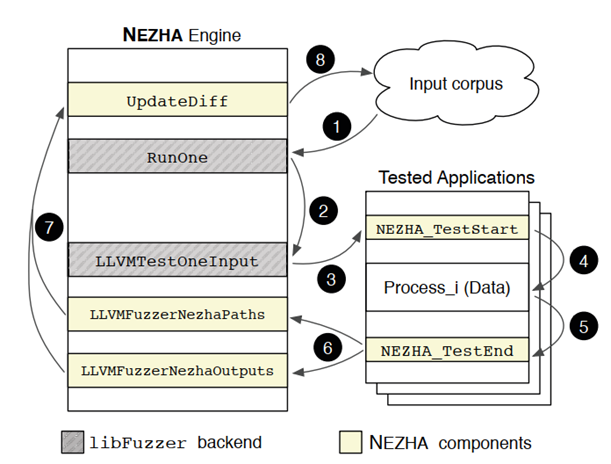
4.3 实验复现
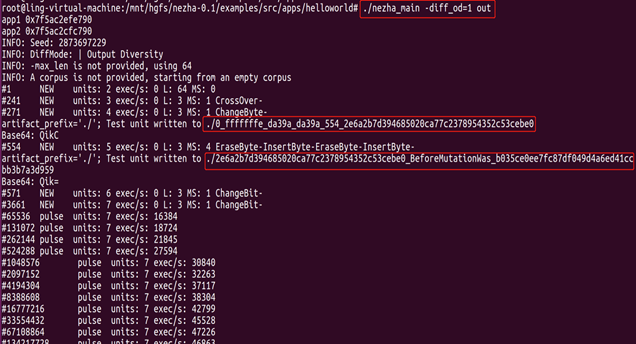
- 使用黑盒输出δ-多样性测试简单实例中的A和B,如下图所示,下划线分隔的前两个数字是返回值用于此输入,接下来的两个数字是各自的前缀用于覆盖每个应用程序的输入的模糊散列。最后一个散列是输入本身的散列。用这个哈希,我们可以看到输入之前的突变触发了差异,即 “2e6a2b7d394685020ca77c2378954352c53cebe0”突变前的哈希为 “b035ce0ee7fc87df049d4a6ed41ccbb3b7a3d95”。大约五百多个测试输入之后,就会发现差异。
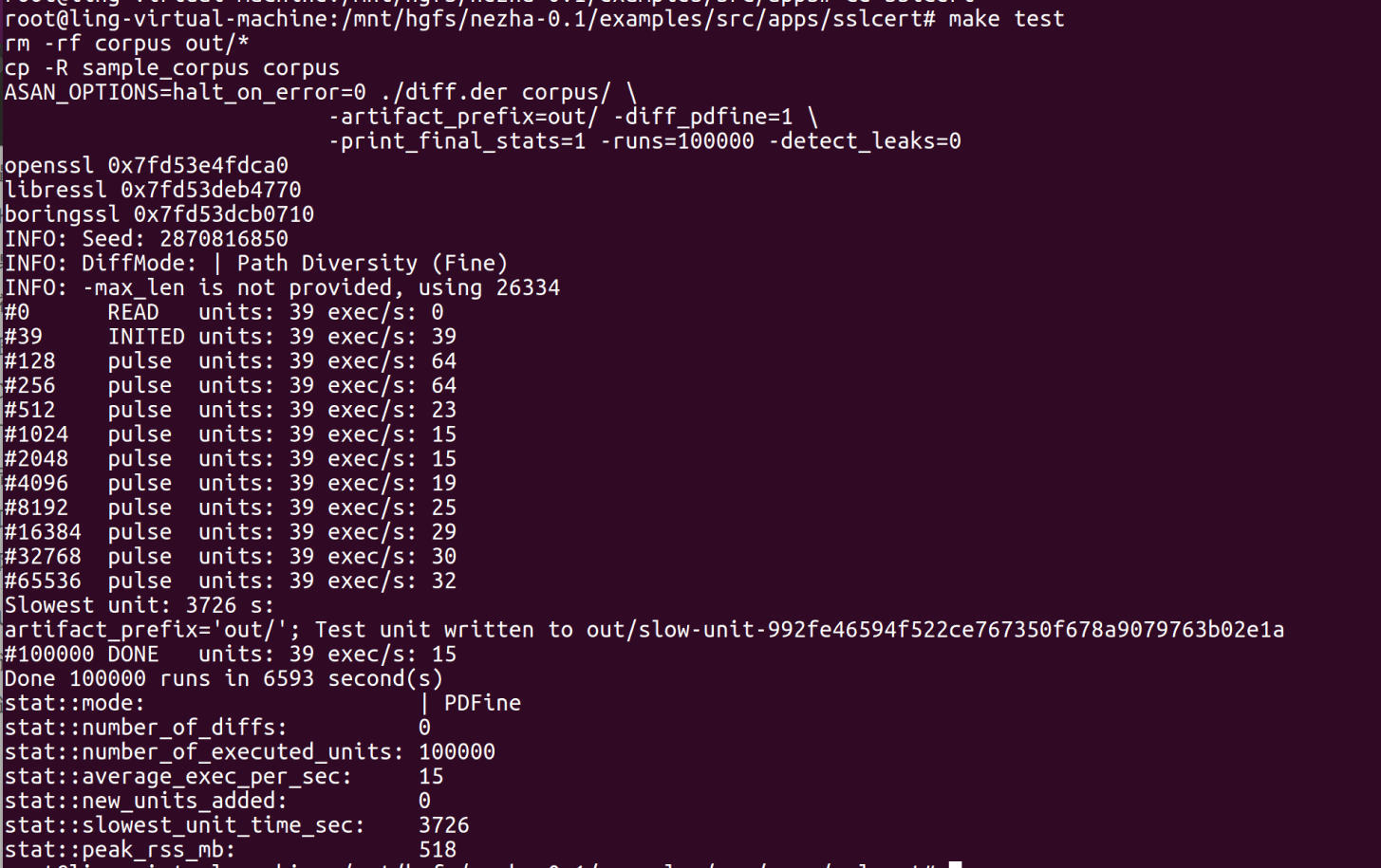
- 比较三个SSL库的差别,使用灰盒测试的更精细的δ-多样性测试,会生成许多证书测试元组,将结果输出到out文件夹中。
五、评估
对NEZHA的有效性进行了评估,一方面是在安全关键的、真实世界的软件中发现差异,另一方面是在与其他不同的测试工具相比较的核心引擎效率方面。实验主要进行了以下操作:
1)通过不同地测试六种主要的SSL库、文件格式解析器和PDF查看器来评估NEZHA。
2)将NEZHA与两种领域特定的差异测试(即Frankencerts和Mucerts引擎)进行了比较,
3)通两种最先进的领域不可知突变fuzzers(AFL和libFuzzer)进行比较。
上述实验证明:
- NEZHA在主要的SSL库中发现了778个验证差异和8个内存错误,效率较高。
- NEZHA报告的差异分别是Frankencerts和Mucerts的52倍和27倍。
- 平均而言,NEZHA比AFL和libFuzzer分别高出6倍和3.5倍。
六、漏洞发现
6.1 ClamAV文件格式验证错误
存在这些漏洞允许攻击者通过向特制文件中注入恶意软件来对ClamAV发起规避攻击。
- ELF软件错误处理格式不正确的头文件。根据ELF规范,ELF头文件包含e_ident[EI_CLASS]字段,该字段指定将编译为运行ELF文件的机器的类型(32位或64位)。在解析ELF二进制文件时,当在e_ident[EI_CLASS]中遇到非法值时,ClamAV与二进制文件不同。如图10所示,ClamAV将配置了非法值的ELF二进制文件视为无效格式(CL_EFORMAT),并且不扫描相应的文件,但ELF二进制文件实际上可以成功执行。
而在Linux内核的ELF加载程序在加载二进制文件时没有验证这个字段。因此,带有这样一个被破坏的ELF头的恶意软件可以逃避ClamAV的检测,同时保留其在主机操作系统中执行的能力。
- XZ软件中字典大小字段处理不当。根据XZ规范,存档中的LZMA2解压算法可以使用从6264kB到4GB不等的字典大小。字典大小因文件而异,并存储在文件的XZ头中。在解析这个字典大小字段时,ClamAV不同于XZ Utils,XZ Utils严格遵守规范,并根据允许的字典大小分配缓冲区。但是ClamAV包含了一个额外的对字典大小的检查,这与规范不符。对于大于182MB的字典,它无法解析归档文件。因此,在解析包含恶意软件的归档文件时,ClamAV不会将该文件视为归档文件,因此会跳过对已压缩的恶意软件的扫描,即对ClamAV进行规避。
6.2 证书验证差异
- LibreSSL:时间字段类型的错误解析,针对X.509证书的RFC标准将时间字段限制为两种形式
- UTCTime :YYMMDDHHMMSSZ(13个字符)
- GeneralizedTime :YYYYMMDDHHMMSSZ(15个字符)
- LibreSSL忽略ASN.1时间格式标签,根据字段的长度确定格式,并推断时间格式类型基于字段的长度
- 当ASN.1 GeneralizedTime类型的时间字段被精心设计为与UTCTime具有相同的长度时,LibreSSL将GeneralizedTime视为UTCTime。
- 201201010101Z, GeneralizedTime解释为Jan 1 01:01:00 2012 GMT, UTCTime解释为:Dec 1 01:01:01 2020 GMT
- 因此,LibreSSL可能错误地将有效证书视为无效证书;也可能错误地接受过期的证书。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号