redis 缓存淘汰
redis 最大运行内存
redis 最大运行内存可以是多少呢,这个主要看 redis.conf 配置中的maxmemory <bytes>选项,设定最大运行内存的单位是字节。只有当我们的 redis 内存占用达到这个阈值时,才会开启缓存淘汰。
- 在 64 位机器上,maxmemory 的默认值是 0。表示不限制内存大小使用,也就是说,redis 不会对可用内存大小进行检查,直到 redis 因内存不足而崩溃也无作为。
- 在 32 位机器上,maxmemory 的默认值是 3G。因为 32 位的机器最大只支持 4GB 的内存,最大使用 3G 内存是比较合理的,这样可用避免内存使用过大,导致 redis 崩溃。
查看当前 redis 内存使用情况
config get maxmemory查看最大可使用内存是多少,64位机器默认为0info memory查看当前 redis 使用的内存情况
生产上内存设置:一般推荐 redis 可使用内存为最大物理内存的四分之三
缓存淘汰策划
大体上分为 不进行数据淘汰,和 进行数据淘汰 两大部分。
不进行数据淘汰
noeviction(默认的内存淘汰策略)就是在内存满了的时候,不淘汰任何数据,并且客户端发送的写请求命令,会被拒绝处理,并返回错误。但是如果是单纯对 redis 读取数据,或者删除数据的请求,还是能正常工作。
进行数据淘汰
又可以细分为两大部分,一部分是对设置了过期时间的数据进行淘汰,另一部分是在所有数据范围内进行淘汰。
在设置了过期时间的数据进行淘汰的策略有:
- volatile-random:随机淘汰键值对。
- volatile-ttl:优先淘汰更早过期的键值对,就是优先淘汰剩余时间(TTL)最短的。
- volatile-lru: 淘汰最久未访问的键值对
- volatile-lfu: 淘汰那些最近最少使用的键值对
在所有数据范围进行淘汰的策略有:
- allkeys-ramdom: 对所有键值对进行随机淘汰
- allkeys-lru: 对最久未使用的键值对进行淘汰
- allkeys-lfu: 对访问次数最少的键值对进行淘汰
其中 lru,和 lfu,lru 主要是针对时间,lfu 针对的是次数。
查看当前 redis 使用的内存淘汰策略,config get maxmemory-policy 命令:
127.0.0.1:6379> CONFIG GET maxmemory-policy
1) "maxmemory-policy"
2) "noeviction"可以看出当前 redis 使用的是默认不淘汰数据的策略,不对任意数据进行淘汰,但不能执行新的写入命令。
缓存淘汰实现
其中,lru 和 lfu 是用的最多的两种缓存淘汰策略,主要介绍下这两种策略的具体实现。
lru 和 lfu 在传统中的实现
lru 一般都是基于链表结构的,新元素插入或者旧元素被访问时,旧会插入到头部,当链表数量达到上限后,就会从尾部删除元素。lfu 一般是用 map 来存储 key 以及访问频率 frequency count。在 map 数量达到上限后,会按访问频率进行排序,然后删除频率最低的那个元素。
lru 和 lfu 在 redis 中的实现
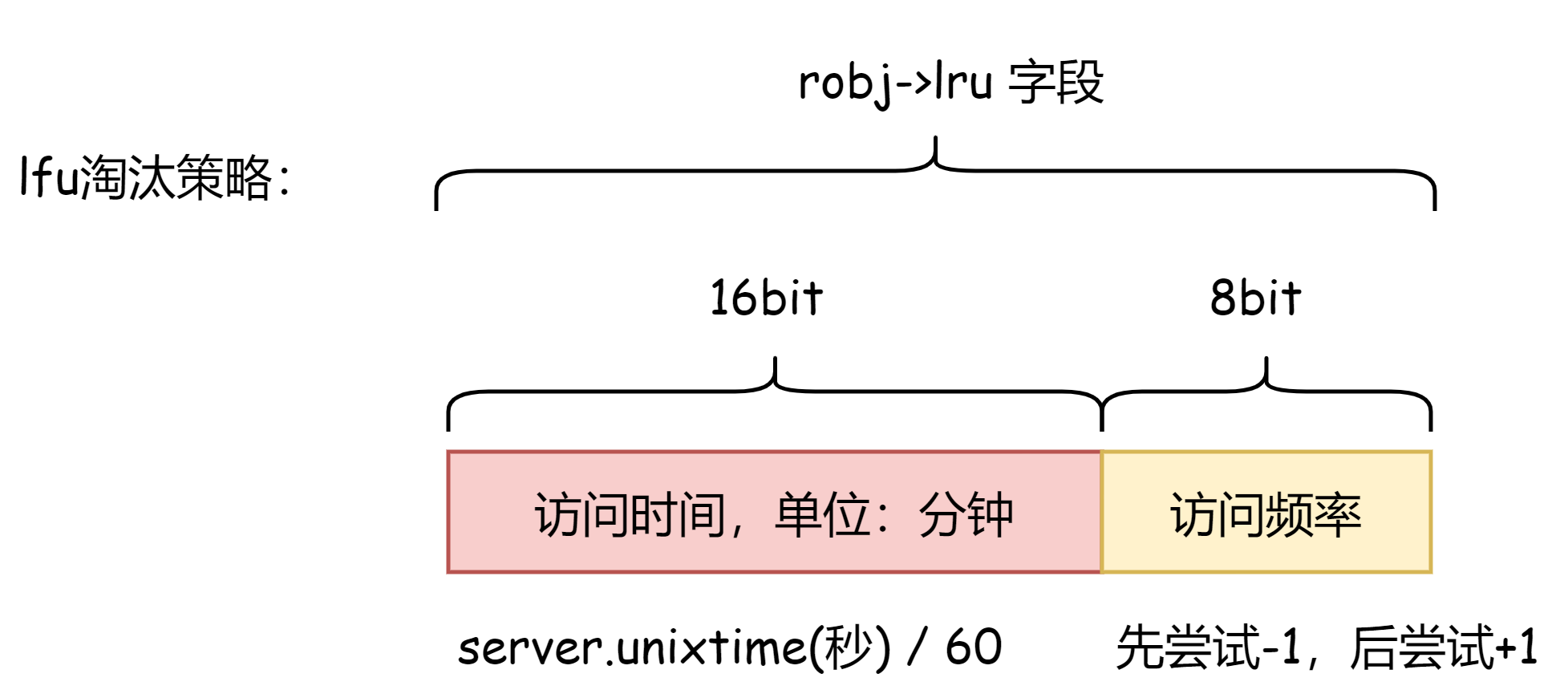
redis 每个值对象都有一个 lru 字段,占24个字节,如果是使用 lru 策略,那么这个值存的是当前时间,单位为秒(每194天溢出一次)。
如果采用的是 lfu 策略,那么字段又会细分为两部分,高16个字节存储时间,单位为分钟(每 45 天溢出一次),低8位存储访问次数(即访问频率),最大值 255。

lru 字段更新
每当我们去访问 key 的时候,都会去查找这个 key 对应的值 robj 对象,然后更新这个对象的 robj->lru 字段,如果是使用 lru 策略的话,那么就只需要简单的更新为当前时间就可以了。
先额外补充下:
一般情况下,获取当前时间戳,会调用系统函数 gettimeofday(),本身这个系统调用也是非常快的,但是在高并发,高 QPS 的情况下,每次都要系统调用来获取时间戳,那么这个时间消耗就被放大很多了。所以,redis 用 redisServer.lruclock 字段来缓存了系统时间戳作为 LRU 时钟。也就是说,我们在访问 key,更新值对象 robj->lru 时间字段时,是用redisServer.lruclock 的,而不是通过系统调用来更新。
这个是一个很好的优化思路,在对系统时间精度要求不是特么高,不需要太精确的地方,我们可以在应用层,通过某个字段来缓存系统时间戳,然后在其他地方,想要使用时间戳的时候,直接读取这个字段就好了,而不用系统调用来获取时间戳。在 redis 中,这种优化思路,还应用到 日志打印,是否进行持久化等地方。
robj *lookupKey(redisDb *db, robj *key, int flags) {
...
robj *val = NULL;
...
if (val) {
...
if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
updateLFU(val);
} else {
val->lru = LRU_CLOCK();
}
}
...
}
unsigned int LRU_CLOCK(void) {
unsigned int lruclock;
...
atomicGet(server.lruclock,lruclock);
...
return lruclock;
}如果是使用 lfu 淘汰策略,则是调用 updateLFU() 来更新值对象 obj->lru 字段。
void updateLFU(robj *val) {
unsigned long counter = LFUDecrAndReturn(val); // 对低8位访问次数进行衰减
counter = LFULogIncr(counter); // 对低8位访问次数进行+1
val->lru = (LFUGetTimeInMinutes()<<8) | counter; // 更新lru字段,当前分钟时间+访问次数
}如果一个 key 长时间没被访问,那么是会对这个 key 的访问次数进行衰减操作的(即count-1),即根据时间流逝越多,那么就会衰减越多,默认一分钟衰减1。然后,这个 count 次数也不是随着每次访问 key 的时候,都会 +1 的,而是有一定几率触发 +1 操作。
// 获取当前时间(单位:分钟,而且只有低16位)
// 这个虽然不使用系统调用来获取时间戳,但用 unixtime 来获取分钟级别,还是可以做到比较比较准确的
// 这也是一个不错的优化思路
unsigned long LFUGetTimeInMinutes(void) {
return (server.unixtime/60) & 65535;
}
// 计算当前时间与上一次时间差(单位:分钟)
unsigned long LFUTimeElapsed(unsigned long ldt) {
unsigned long now = LFUGetTimeInMinutes();
if (now >= ldt) return now-ldt;
return 65535-ldt+now;
}
// 对 count 尝试衰减
unsigned long LFUDecrAndReturn(robj *o) {
unsigned long ldt = o->lru >> 8; // 获取高16位
unsigned long counter = o->lru & 255; // 获取低8位
// server.lfu_decay_time 默认为1,也就是相差几分钟,count 就减几,最多减到0
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
}
// 对 count 尝试进行+1
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255; // 如果已经加到最大值了,直接返回;低8位,最大值为255
double r = (double)rand()/RAND_MAX; // 随机一个小数
double baseval = counter - LFU_INIT_VAL; // 以 count - 5 做为基数
if (baseval < 0) baseval = 0;
// 求反比例函数,如果当前的 counter 很大了,那么这次能+1的概率就会越小,当然也受 lfu_log_factor 因素影响
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
return counter;
}可以看到,在 lfu 策略下,robj->lru字段记录分钟时间的作用,只会影响 count 访问频率,对其进行衰减操作,如果不做衰减,那么只要某个 key 访问频率达很高,接近255,那么这个 key 在后面一段很长的时间内,即使不再被访问了,那么也很难被淘汰了。
在后面介绍中,真正进行数据淘汰时,是根据 count 大小排序进行淘汰的,count 值越小,访问频率越低,越优先被淘汰。
小结:
lru 和 lfu 淘汰策略,都是针对 robj->lru 字段进行操作的,这两种策略是互斥的,在 redis 运行的时候,只能使用其中一种,所以说,robj->lru 字段会根据不同的策略,有不同的含义,以及不同的处理方式。

执行淘汰逻辑
redis 会在执行命令前,先检查当前内存使用,是否达到了最大值,并且没法淘汰数据,如果是的话,再看下请求的命令是否是写,或者修改操作的,如果是,那么就会返回一个 OOM 的错误信息。
思路:
只要当前使用内存超过了最大配置内存,就会根据淘汰策略,先从过期的字段或者从所有数据的字典中,随机选择一部分 key 做为样本(默认挑选5个key),放到一个数组中。然后对样本 key 进行排序,具体是按 lru 最久访问时间,或是 lfu 访问频率,或是 ttl 离现在最短的时间等不同的淘汰规则进行排序(采用插入排序),然后,删除队尾最优的那个 key。删除后,再检查下内存是否小于最大配置内存,如果小于,那么就跳出循环。否则继续执行上面重复步骤。在每淘汰16个 key 的时候,还会判断一下执行时间有没有超时,默认是 500 微妙。如果超时了,会开启一个定时器去定时执行淘汰逻辑,然后,中断本次执行。
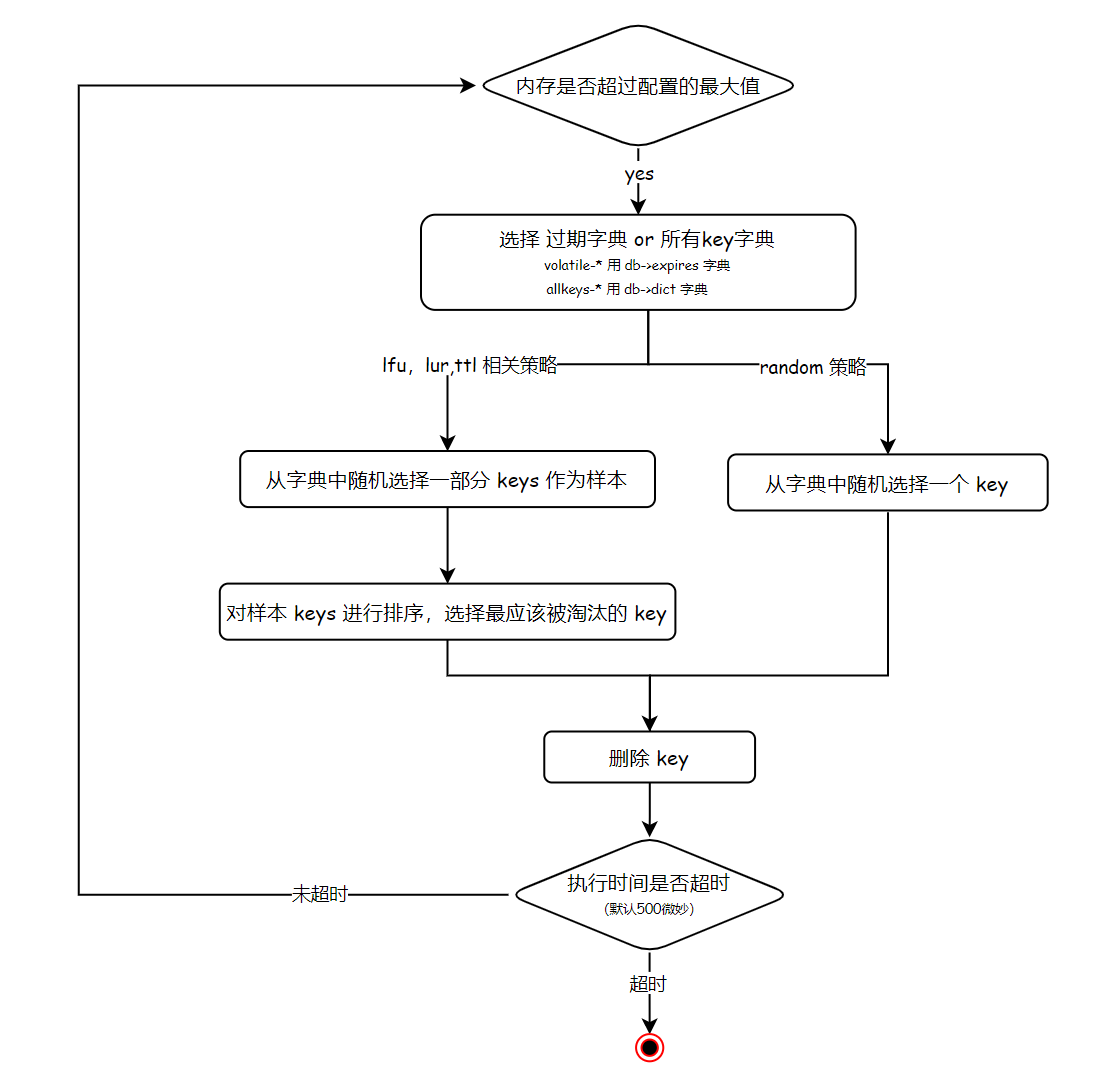
相关代码主要在 evict.c 文件的 performEvictions() 函数中。
小结
和传统的 lru,lfu 实现相比,redis 为了尽可能减少内存空间的使用,不采用额外的链表或者字典来存储每个 key 的访问时间,或访问频率。而是在真正内存满了之后,才随机挑选一部分 key 放到一个固定长度数组中,进行排序,筛选出最应该被淘汰的 key。这样能节省内存空间占用,也不用每次访问数据的时候,移动链表。
参考:
https://xiaolincoding.com/redis/module/strategy.html#内存淘汰策略

 浙公网安备 33010602011771号
浙公网安备 33010602011771号