lua5.3 函数调用实现
首先,我们需要考虑下函数调用前,我们需要做些哪些准备工作。调用时,如何切换到它对应的函数环境中,调用完后,又如何切换回来。
函数调用前准备
我们之前有介绍过函数闭包,lua 函数能像其他值(数值、字符串)一样,可以被存放在变量中,也可以存放在表中,可以作为函数的参数,还可以作为函数的返回值。(在lua中,简称为第一类值),我的理解,lua代码中的函数,就是对应着底层的函数闭包对象,而函数闭包对象,自然具有和 table,string 等其他对象一样的性质,可以当作值传来传去。
现在回答第一个问题,在发生函数调用前,需要准备好新函数(函数闭包对象)地址,参数列表,保存虚拟机执行当前函数指令的 savedpc(新函数调用完后,我们需要通过 savedpc 继续执行当前函数剩余的指令)。
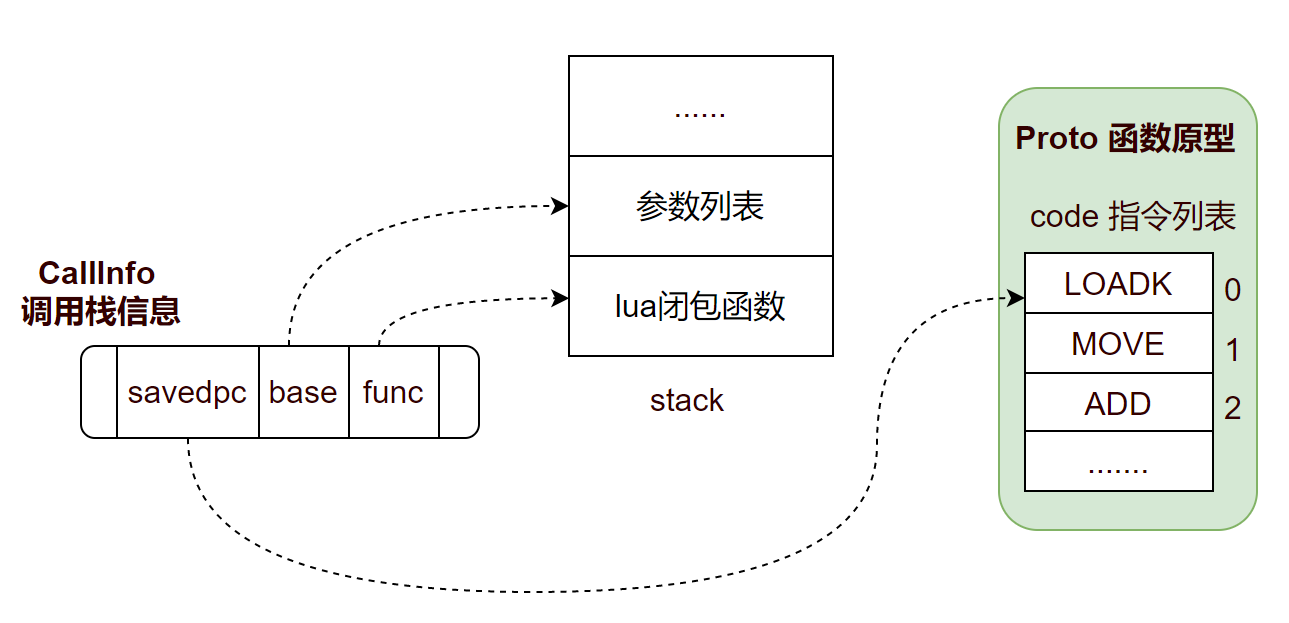
在 lua 源码中,使用的是 CallInfo 这个结构体,来存储函数调用栈信息。
typedef struct CallInfo {
StkId func; /* function index in the stack */
StkId top; /* top for this function */
struct CallInfo *previous, *next; /* dynamic call link */
union {
struct { /* only for Lua functions */
StkId base; /* base for this function */
const Instruction *savedpc;
} l;
struct { /* only for C functions */
lua_KFunction k; /* continuation in case of yields */
ptrdiff_t old_errfunc;
lua_KContext ctx; /* context info. in case of yields */
} c;
} u;
ptrdiff_t extra;
short nresults; /* expected number of results from this function */
unsigned short callstatus;
} CallInfo;重要字段说明:
| func | 指向 Proto 函数原型 |
| top | 函数的栈顶位置 |
| base | 局部变量起始地址 |
| savedpc | 记录当前函数接下来要执行的指令位置 |
| nresults | 函数返回值个数 |
函数调用前,准备好一个新的 CallInfo 调用栈对象,设置好字段值,其中 savedpc,base,func 字段作用如下:
函数调用中
函数调用比较简单,其实就是执行函数原型里的指令数组( Proto->code),执行里面的一条条指令。如果是执行 OP_CALL 指令,函数调用,又会重复上图的步骤。
比如,在执行 f1() 函数过程中,有函数调用 f2(),即执行到 CALL指令,f1() -> f2() 最终效果如下:

在 f1 执行到 CALL 指令时,savedpc 保存的是即将要执行下一条指令的位置。只有这样,在 f2 调用完,我们才可以在 f1 中接着执行 f2 返回后的代码。通过上图,我们看出,CallInfo 之间采用双向链表数据结构,在当前函数调用完后,通过 CallInfo.previous 字段来切回到上一个 CallInfo,我们才能够接着执行 CALL 后续指令。可以看下 ldo.c,lvm.c 源码文件中的 luaD_precall,luaV_execute 实现。
函数调用后
在执行完函数后,如果有返回值,则需要把返回值写入到上一个函数栈帧中,具体是怎么做的呢。
在函数返回的时候,会执行一条 OP_RETURN 指令,这条指令就会对返回值做一些处理。还记得 CallInfo 结构体里有一个 nresults 字段吗,nresults 表示期望有多少个返回值。比如,local a, b, c = f1()希望在 f1 调用后,能返回3个值,分别赋给变量 a,b,c。nresults 为几,其实是在编译解析阶段就确定好的(不包括可变参数 ... 那种),有几个变量需要有返回值,就希望函数返回几个。但最终函数能返回多少个值,却是由函数自身决定的,返回值多了,会被截断,少了,会填充 nil。
比如有下面一段代码,f1 只返回变量 a,c,中间 b 不需要返回,也就是说,返回值不是在栈中连续空间的。其中 a,b,c 在栈中的相对偏移地址为 0,1,2,这个时候,lua 是怎么正确返回 a,c 的值呢。
local function f1( )
local a = 1
local b = 2
local c = 3
return a, c
end
local m1, m2, m3 = f1()其实实现原理也很简单,分两种情况考虑,如果返回值只有一个,OP_RETURN 指令执行的时候,只需要到栈中指定的位置,去拿值就可以了。如果超过1个返回值,则需要把这些值重新 push 到栈顶,此时 OP_RETURN 根据 nresults 个数去栈顶拿返回值,那么这些返回值肯定就是连续的。
我们再用 f1() 调用 f2() 函数举例:
local function f2(arg1, arg2)
return 1, 2
end
local function f1(arg1, arg2)
local a, b = f2("a", "b")
-- ...
end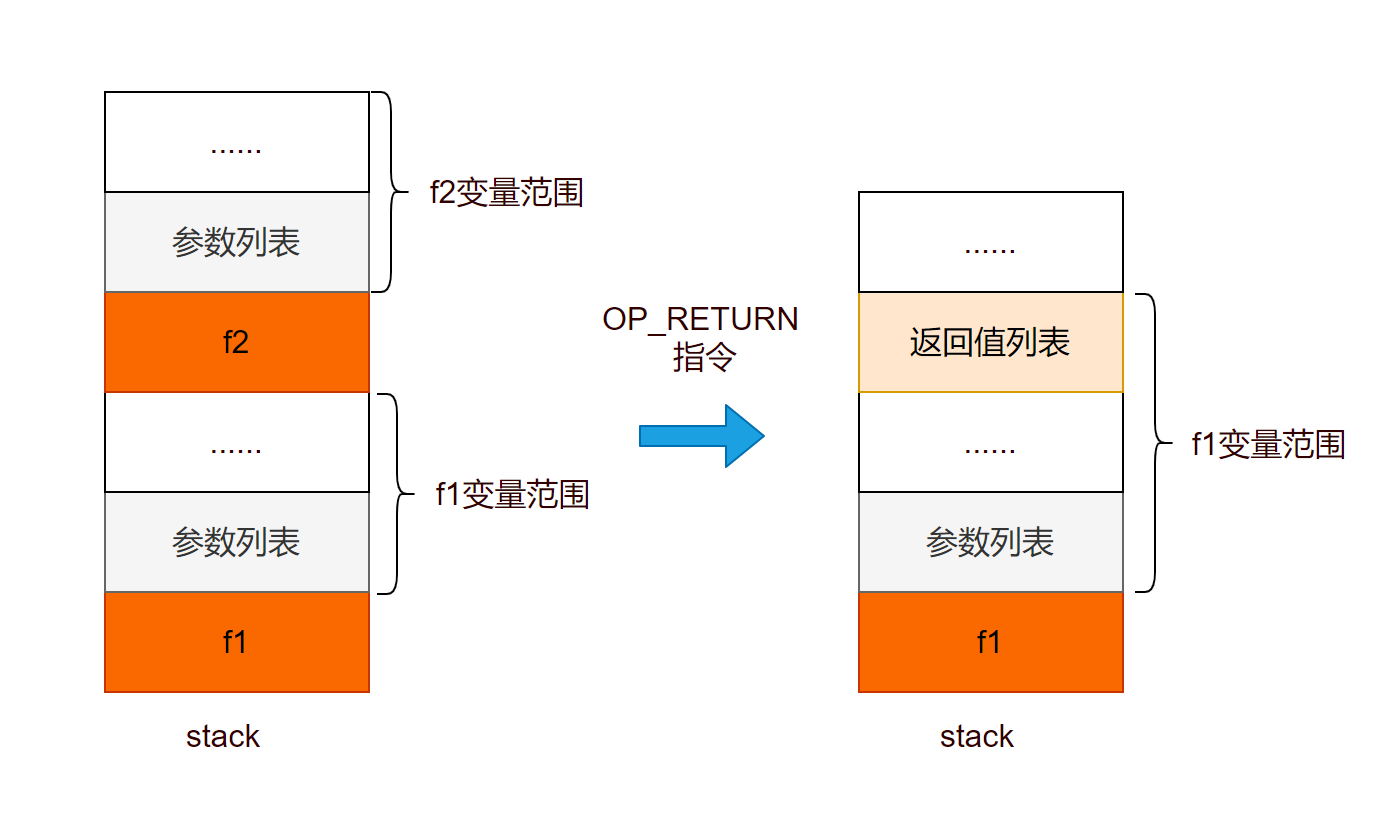
我们可以看到,栈中 f2 位置,被返回值覆盖了,最终变成 f1 函数局部变量里的一部分,具体可以看看 luaD_poscall 实现。
CALL (OP_CALL)指令实现
下面我们再细说下 call 指令实现。
先举个例子,看看函数调用时,对应的指令有哪些。
local function f1(a, b, c)
local d = -11
print(a, b, c, d)
end
f1(1, 2, 3)
-- 结果: 1 2 3 -11接着用 luac -l aaa.lua 看下生成的指令列表,下面只截取其中一部分:
main <aaa.lua:0,0> (7 instructions at 0000000000af8520)
0+ params, 5 slots, 1 upvalue, 1 local, 3 constants, 1 function
1 [4] CLOSURE 0 0 ; 0000000000af86d0
2 [6] MOVE 1 0
3 [6] LOADK 2 -1 ; 1
4 [6] LOADK 3 -2 ; 2
5 [6] LOADK 4 -3 ; 3
6 [6] CALL 1 4 1
7 [6] RETURN 0 1main <aaa.lua:0,0> 表示当前文件执行的指令列表。它其实也是一个匿名函数,由 lua 内部调用。[4] CLOSURE 0 0 表示在文件的第4行,生成一个闭包函数指令,并且将闭包对象放到栈中偏移 L->ci->base 对应的 0 号位置。第[6]行 lua 代码中,对应的指令有6条,发生函数调用的时候,指令MOVE 1 0 需要把函数闭包对象 push 到栈顶,然后 LOADK将所需要的参数从常量表中 push 到栈上,最后 CALL 执行函数调用。这说明,在函数调用前,我们需要准备好函数闭包对象,以及参数列表。
在第[6]行准备好函数闭包,以及参数列表后,执行 CALL 指令。我们在 lopcodes.h 文件查看 CALL 指令介绍:
OP_CALL,/* A B C R(A), ... ,R(A+C-2) := R(A)(R(A+1), ... ,R(A+B-1)) */CALL 指令作用是调用函数,同时返回结果值,相关参数介绍如下:
- 参数A:被调用函数(函数闭包对象)在栈中的地址。
- 参数B:函数参数数量。有两种情况:
- 为0时,表示参数从 A+1位置开始,即 ci->base 直到 L->top 位置,都做为函数的参数,因为参数有可能是另一个函数调用的返回值,在不知道返回值个数时,只能告诉编译器参数从 A+1 开始,到 L->top 之间的值都做为参数。比如,
f2(f1()),f2的参数数量由f1的返回值决定,是可变的; - 大于0时,表示函数参数的数量为 B-1 。
- 为0时,表示参数从 A+1位置开始,即 ci->base 直到 L->top 位置,都做为函数的参数,因为参数有可能是另一个函数调用的返回值,在不知道返回值个数时,只能告诉编译器参数从 A+1 开始,到 L->top 之间的值都做为参数。比如,
- 参数C:函数返回值个数。也有两种情况:
- 为0时,表示有可变数量的值返回,比如
f2(f1())中,f1返回值就是可变数量的; - 大于0时,表示返回值数量为 C-1。
- 为0时,表示有可变数量的值返回,比如
在介绍 lua 函数局部变量时,有提过,函数的参数也属于局部变量的一种,虽然它们没有声明为 local,但和 local 变量一样,都是存放在栈上的。上面代码,执行 f1(1,2,3)调用时的堆栈示意图如下:

: 成员函数调用
我们平时用 lua 模拟面向对象实现,使用 self 来表示这个对象。现在就来看看它是如何实现的。
编译阶段
在定义一个函数时,解析到函数名,会先检测是否有用冒号:,如果有,就会默认创建一个 self 局部变量new_localvarliteral(ls, "self");
static int funcname (LexState *ls, expdesc *v) {
/* funcname -> NAME {fieldsel} [':' NAME] */
...
if (ls->t.token == ':') {
ismethod = 1;
fieldsel(ls, v);
}
return ismethod;
}
static void funcstat (LexState *ls, int line) {
/* funcstat -> FUNCTION funcname body */
int ismethod;
expdesc v, b;
luaX_next(ls); /* skip FUNCTION */
ismethod = funcname(ls, &v);
body(ls, &b, ismethod, line);
luaK_storevar(ls->fs, &v, &b);
luaK_fixline(ls->fs, line); /* definition "happens" in the first line */
}
static void body (LexState *ls, expdesc *e, int ismethod, int line) {
/* body -> '(' parlist ')' block END */
...
checknext(ls, '(');
if (ismethod) {
new_localvarliteral(ls, "self"); /* create 'self' parameter 默认创建一个 self 局部变量*/
adjustlocalvars(ls, 1);
}
...
}如果解析到有使用成员函数时,比如,foo:bar(),就会生成一条 self 指令。
OP_SELF,/* A B C R(A+1) := R(B); R(A) := R(B)[RK(C)] */- 参数A:将这个待调用模块(有可能是table,或者Udata)值放到 R(A+1)处,待调用的成员函数放到 R(A) 处。
- 参数B:待调用模块。
- 参数C:待用用的函数名。
self 指令的作用,其实就是为了在函数调用前,准备好模块,放到栈上,并用 "self" 变量名来指向模块对象。
例如:
local t = {}
function t:f1(a, b)
print(self.name, a, b)
end
t.name = "zhangsan"
t:f1(1, 2)luac -l -l 查看截取第[8]行代码对应的指令:
5 [8] SELF 1 0 -1 ; "f1"
6 [8] LOADK 3 -4 ; 1
7 [8] LOADK 4 -5 ; 2
8 [8] CALL 1 4 1执行阶段
看看 self 指令执行对应的源码:
vmcase(OP_SELF) {
const TValue *aux;
StkId rb = RB(i); // 获取模块
TValue *rc = RKC(i); // 获取模块中的闭包名
TString *key = tsvalue(rc); /* key must be a string */
setobjs2s(L, ra + 1, rb); // 将模块放到 ra+1 处
if (luaV_fastget(L, rb, key, aux, luaH_getstr)) { // 查找模块里的闭包函数,将其放到 ra 处
setobj2s(L, ra, aux);
}
else Protect(luaV_finishget(L, rb, rc, ra, aux));
vmbreak;
}按照 SELF 指令介绍,例子中对应的伪代码:
stack[ci->base + 0] = {} // local t = {}
// t:f1() 对应的 SELF 伪代码:
stack[ci->base + 2] = stack[ci->base + 0] // base+2 处存放 t 这个表对象
stack[ci->base + 1] = t.f1 // base+1处存放 f1 闭包 
f1 成员函数对应的指令列表如下,其中 locals 局部变量那块,就有 self 变量,虽然我们没有定义过 self 变量,但使用 : 符合,在函数解析阶段时,系统会默认创建 self 变量。

self 指令,以及在函数中,self 变量的自动创建,是我们在 lua 语言中能实现面向对象编程的基础。
函数尾调用
在 Lua 中,如果一个函数的最后一个动作是返回另一个函数的调用结果,我们就说它进行了尾调用。
尾调用的特点是可以利用尾递归消除,这意味着在尾调用的过程中,不需要保留当前函数的状态,因为当前函数即将返回,其栈空间可以被重用。用在一些比较复杂的递归函数调用时,非常高效。
编译阶段,在解析 return 语句时,有下面一个判断,解析 return 语句时,如果返回值只有一个,且是函数调用。那么就会生成一条 OP_TAILCALL 尾调用指令。
static void retstat (LexState *ls) {
/* stat -> RETURN [explist] [';'] */
...
// return 后是函数调用,且只有一个返回值
if (e.k == VCALL && nret == 1) { /* tail call? */
SET_OPCODE(getinstruction(fs,&e), OP_TAILCALL);
lua_assert(GETARG_A(getinstruction(fs,&e)) == fs->nactvar);
}
...
}在运行阶段,执行 OP_TAILCALL 指令时,会将复用当前函数的调用栈信息 CallInfo 这个结构体对象,就不再新创建一个 CallInfo 对象,且栈中的局部变量会被尾部调用的函数使用覆盖。
我们举个例子,来看看尾调用的好处:
local function f1(a)
if a < 0 then
return a
end
local r = f1(a - 1)
return r
end
local start = os.time()
f1(100000000)
print(os.time() - start)
--[[
运行结果:
stack traceback:
.\aaa.lua:6: in upvalue 'f'
.\aaa.lua:6: in upvalue 'f'
...
.\aaa.lua:6: in upvalue 'f'
.\aaa.lua:6: in local 'f'
.\aaa.lua:11: in main chunk
[C]: in ?
]]
我们发现如果,函数调用太深, 栈溢出了。如果我们改造下,如下:
local function f1(a)
if a < 0 then
return a
end
return f1(a - 1)
end
local start = os.time()
f1(100000000)
print(os.time() - start)
--[[
运行结果:
2
]]我们在 f1 函数中改用尾调用后,发现没有报错了,且仅用2s左右。这说明,调用次数再多,也就是消耗 cpu 时间而已,栈不会因为函数调用过深而导致溢出。
可变参数![]()

对于可变参数,我们平时写 lua 代码,基本都会用到,那么它底层是如何实现的呢。
在解析函数参数列表时,发现有 ... 时,则 Proto.is_vararg 标记为1,表明当前函数原型有使用到可变参数。源码如下:
static void parlist (LexState *ls) {
/* parlist -> [ param { ',' param } ] */
...
case TK_DOTS: { /* param -> '...' 可变参数 */
luaX_next(ls);
f->is_vararg = 1; /* declared vararg */
break;
}
...
}在运行阶段,根据函数调用,实际给的个数来调整最终可变参数的结果,代码如下:
static StkId adjust_varargs (lua_State *L, Proto *p, int actual) {
int i;
int nfixargs = p->numparams; // 非可变参数个数,即指定参数名的变量个数
StkId base, fixed;
/* move fixed parameters to final position */
fixed = L->top - actual; /* first fixed argument */
base = L->top; /* final position of first argument */
// 将有指定参数名的变量值,移动到栈顶,并将原来位置值nil
for (i = 0; i < nfixargs && i < actual; i++) {
setobjs2s(L, L->top++, fixed + i);
setnilvalue(fixed + i); /* erase original copy (for GC) */
}
// 如果有指定参数名的值个数不足,填充 nil
for (; i < nfixargs; i++)
setnilvalue(L->top++); /* complete missing arguments */
return base;
}上面的代码,可能不是很好理解。我们可以简单举个例子来说明下。
local function f1(a, ...)
print(a, ...)
end
local a, b, c = 1, 2, 3
f1(a, b, c)在定义 f1 函数时,参数 a 是指定接收函数调用时的第一个值,... 表示多出1个值的部分作为可变参数。直观上看,参数 a = 1,可变参数 ... = 2,3。
我们接着看看 f1 调用时,栈的情况:

从中,我们发现被指定的参数 a 被移动到栈顶了,原先所在的位置被改成 nil,而且 ci->base 的起始位置也改成了从参数 a 开始。可变参数被放到了 ci->base 的下面了。
从中,我们就可以理解了在函数体里,如果想使用可变参数 ... 时,那么只需从 ci->base 处开始往下查找,公式如下:
// 可变参数个数
n = (ci->base - ci->func) - cl->p->numparams - 1;
// 可变参数起始位置
ci->base - n 就像上面例子的第 2 行代码 print(a, ...),再将可变参数 2,3 push 到栈顶,作为 print 的参数一部分,完成 print 打印。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号