lua ebpf性能监控
在做一个通用的 lua 性能监控工具,不嵌入代码,目前了解到的,比较好的方式是使用 ebpf 。
chatgpt 对 ebpf 介绍:
eBPF是一种允许用户在 Linux 内核中注入自定义代码的技术,eBPF全称为 extended Berkeley Packet Filter,它提供了一种轻量级且安全的方式来在内核中执行用户定义的程序,以实现复杂的网络分析、性能优化、安全加固等功能。
在使用 ebpf 上也遇到不少坑,比如 for 循环限制,必须是有限次数循环,不能是不确定的。对指针的读取使用,必须先判断指针对象是否为 NULL,才用使用,整数要做范围检测,还有就是栈大小,不能超过512 B 等等很多意想不到的限制。

思路
lua 性能工具先在用户空间获取目标进程 pid(可以通过 ps 命令获取),然后读取 /proc/<pid>/maps 内容,获取目标文件路径,读取目标文件的 elf .eh_frame 部分,将其所有静态 loc 地址,转成运行时的虚拟地址,然后存到一个 bpf array 数组容器中,让内核态 bpf 程序能够访问到数组容器,然后进行 c 函数堆栈回溯。
在内核空间,利用 bpf 技术,主要获取目标程序的 rip,rsp,rbp 寄存器值,然后通过用户空间传过来的 array 数组( loc 虚拟地址 ),根据 .eh_frame 规则来进行栈回溯。.eh_frame 栈回溯可以看我之前写的这一篇 c语言 栈回溯 博客。因为 lua 虚拟机指令主要是在 luaV_execute 函数中执行的,当我们回溯 c 堆栈,发现有 luaV_execute 函数调用时,就尝试获取它的参数 lua_State *L。L 具体在哪个寄存器使用,可以通过查看目标程序对应的汇编代码,然后读取那个对应的寄存器值即可。
在拿到 lua_State *L 线程对象后,我们就可以通过遍历 L->ci 链表来进行 lua 函数堆栈回溯。我们收集 lua 闭包对应的 Proto 函数起始行号,结束行号,以及所在的文件名这三个主要信息。最后,放到一个 bpf map 容器中,同 c 堆栈一起返回给用户空间。到了用户空间,对 c 和 lua 堆栈进行合并输出。
c 和 lua 堆栈合并输出
我们知道在 lua 中, 一个函数对应一个 ci(CallInfo 函数栈帧对象),如果在 lua 中调用 c 函数,这个 c 函数也必定会有一个 ci 对应。比如, f1 -> f2 -> c函数 -> f3 形成类似这样的调用链:
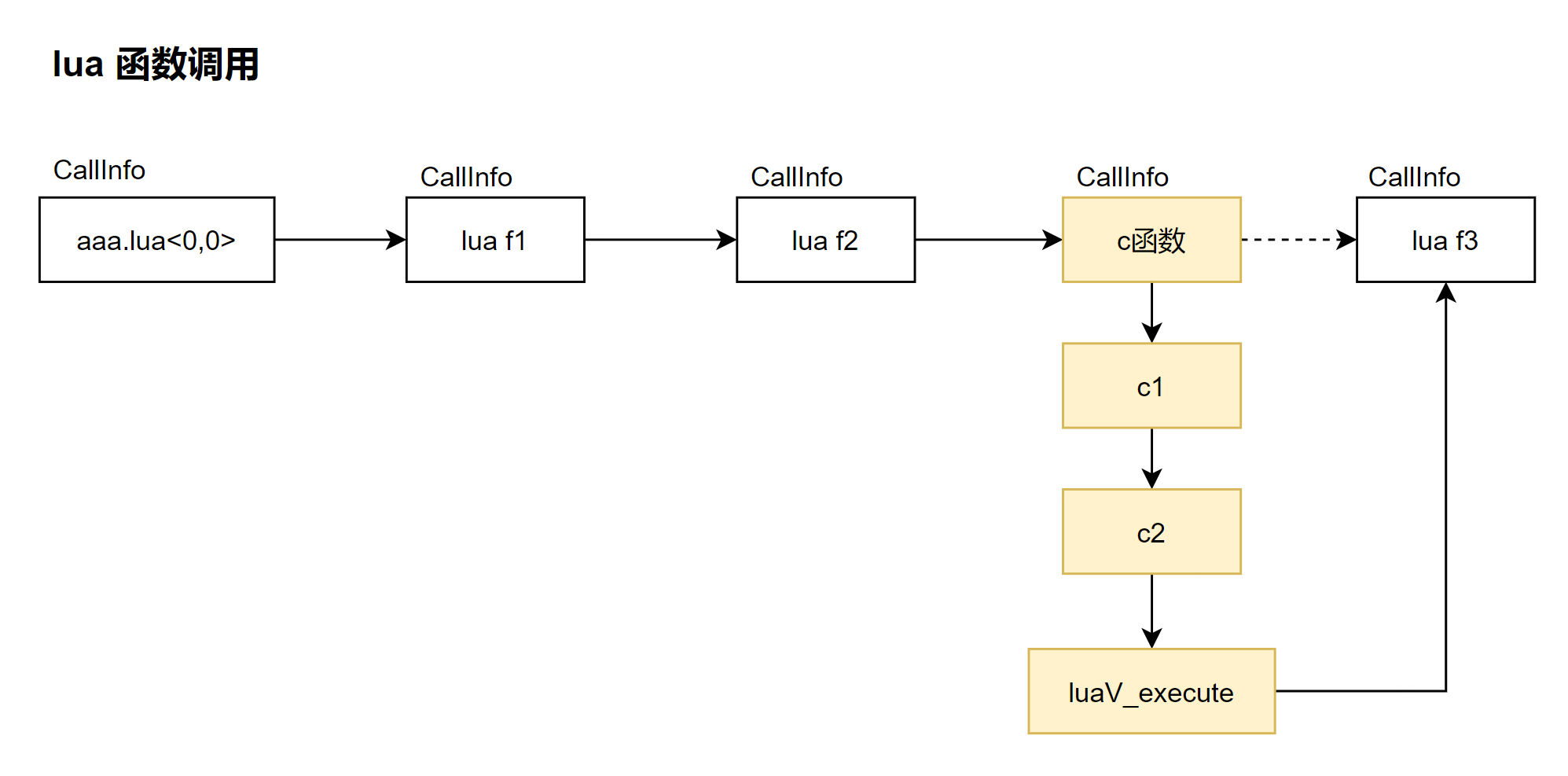
从 c 函数进入 lua 函数,肯定会有 luaV_execute 调用,因为 lua 代码都是在 luaV_execute 虚拟机下执行的,就比如上的 lua f3 函数。
我们通过一个例子,看看调试过程 c 堆栈情况,下面是用源码调试一段 lua 代码过程,为了能实现上面 f1 -> f2 -> c函数 -> f3的模拟,aaa.lua 文件只有 f3 一处 if 调用。而 if 对应的比较指令是 OP_LT, 所以,我们可以很方便的在 luaV_execute 中的 OP_LT加断点。看到左边的 c 函数调用链。(以下调试是在 lua5.3 且编译时加上 -g 得出的完整调用链,gcc 加上 -O2 有可能会进行函数合并优化)。

我们从上图看到,有两次 luaV_execute 调用,认真调试,发现第1次是执行整个 aaa.lua 文件时,第2次是在发生在15行,调用 table.sort 触发对应的 c 函数 sort 调用,而 sort 函数最终又会执行 aaa.lua 中的 f3 函数。
通过观察总结规律,lua 调 c,c 又调 lua 的,我们可以在 lua 堆栈数组中用 c 函数地址来做隔开,如下图:
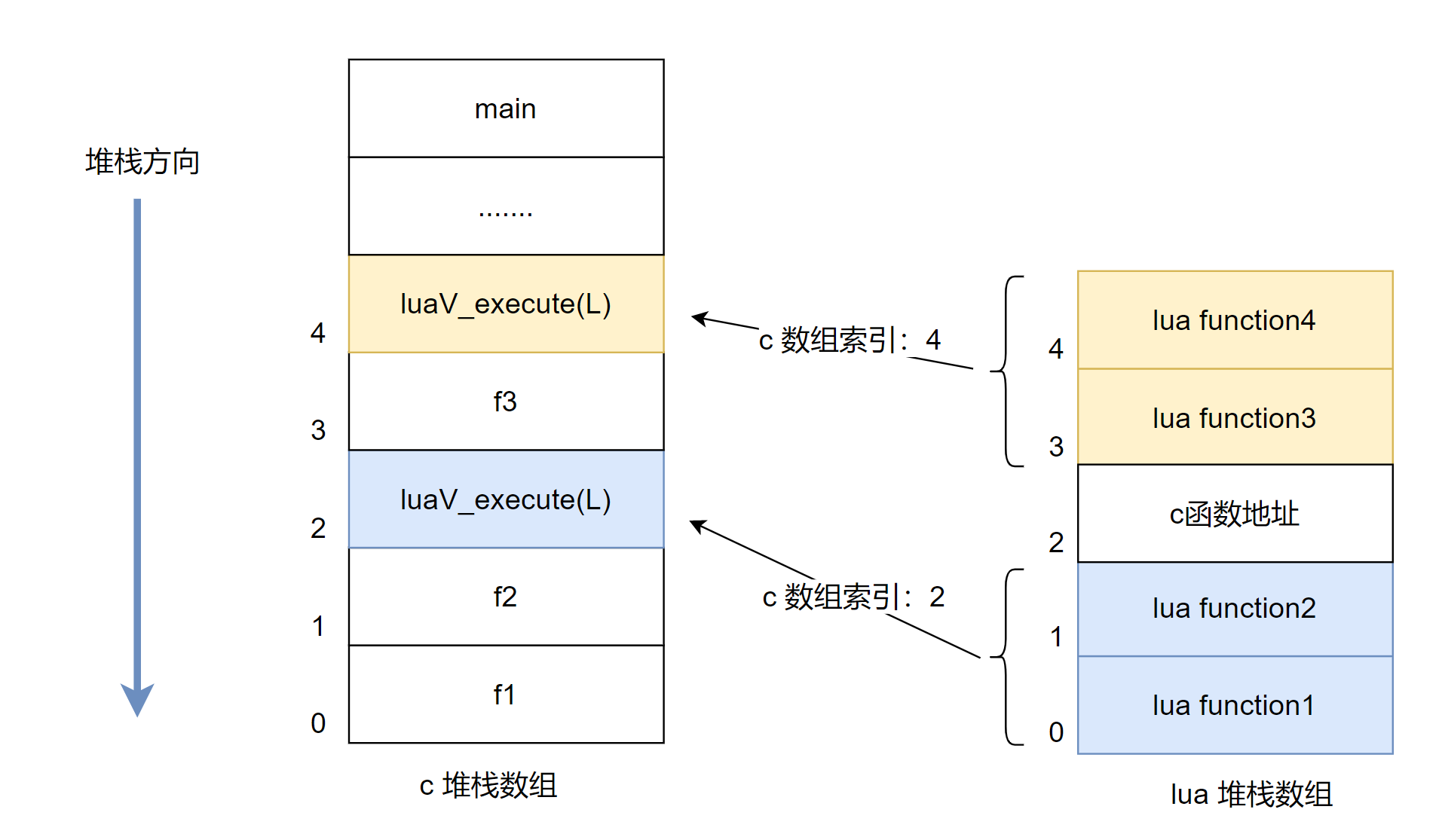
注意,我们在内核空间 bpf 收集到的 c 和 lua 堆栈顺序都是从上往下收集的,比如函数调用链:main->f3->f2->f1,我们收集到的顺序反过来的:array(f1, f2, f3, main)。我们打印到文件的顺序也是从下标0开始的,正好是我们需要的顺序:
索引 函数名
0 f1
1 f2
2 f3
3 main在输出 lua 和 c 的混合堆栈信息时,先遍历 c 堆栈数组打印,当发现有 luaV_execute 函数时,就去遍历 lua 堆栈数组,找到 lua 数组中索引是 2 的 lua function 打印输出,当遇到 索引2,函数地址为 c 函数时,中断打印,回到 c 堆栈这边接着继续打印 c 函数名。
下图是我做的性能工具采集到的原始 c 和 lua 堆栈,c 堆栈有2个 luaV_execute,lua 堆栈中间有个c函数地址,我们就可以用来区分哪些 lua 函数对应哪个 luaV_execute。<aaa.lua:0,0>、<aaa.lua:21,23>、<aaa.lua:12,19> 对应第9行的 luaV_execute,<aaa.lua:1,10> 对应第2行的luaV_execute。
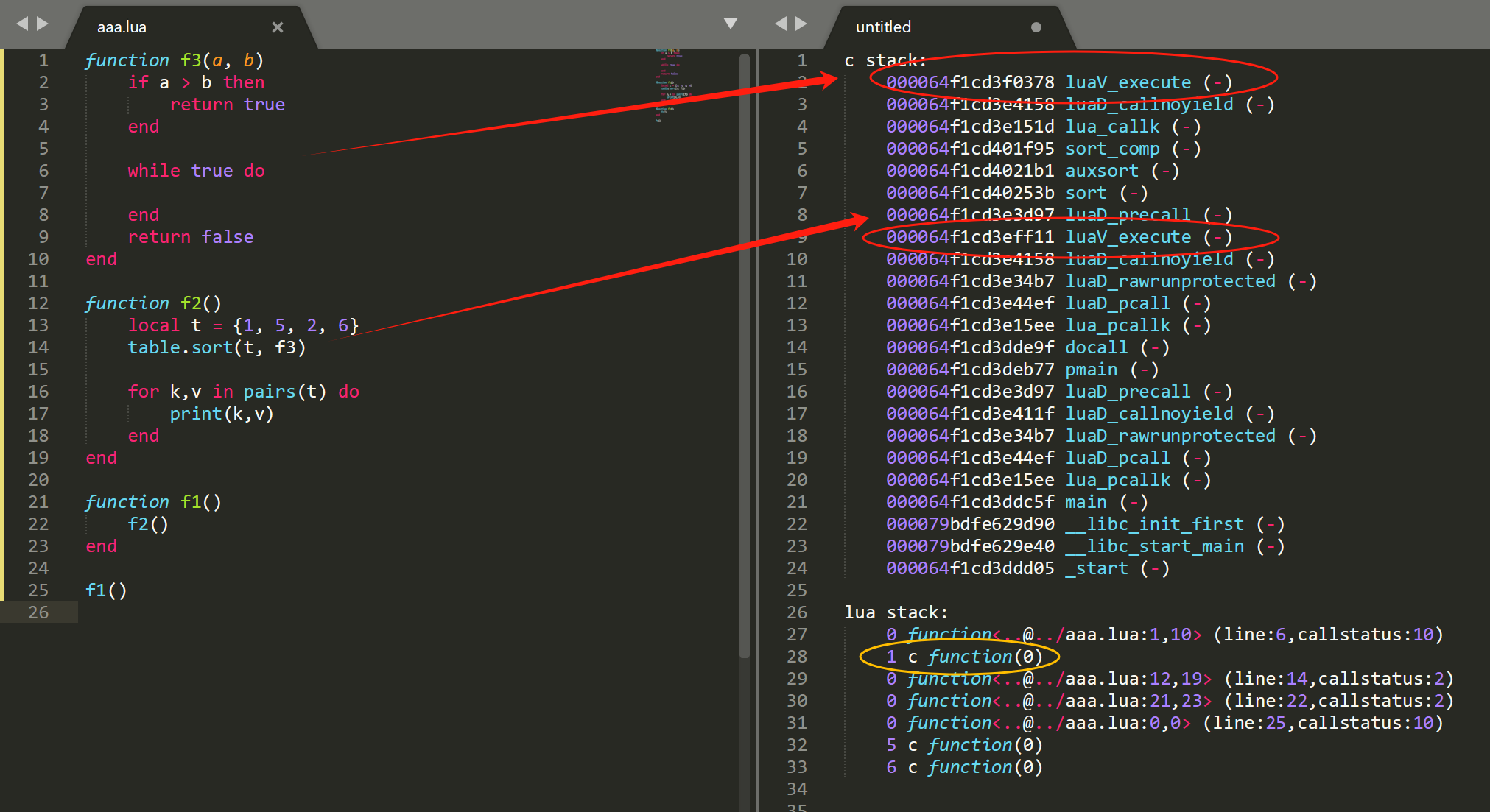
合并后,输出的结果如下,这样就和在 vscode 调试的最终结果吻合了。

元方法导致的合并问题

这乍一看好像没啥问题,但实际测试过程中,如下面的例子,发现有用到 lua 元方法调用的情况下,就不一样了,不能根据 一个 luaV_execute 对应一段 lua 函数调用,中间用 c 函数来隔开,因为元方法是 lua 内置的 (__add,__sub,__call等)。元方法触发调用时,没有一个 CallInfo 对应。在 luaV_execute 执行指令,比如加法指令 OP_ADD 时,如果发现执行加法的两个数,有一个是 table 类型的,就会进入到 799行,去执行 luaT_trybinTM函数,检测是否有 __add 元方法,如果有,就执行 __add 对应的函数。而 __add 指向的函数又是 lua 函数,会发生一次 luaV_execute 调用,因为 lua 函数始终要在 luaV_execute 虚拟机里才能执行。

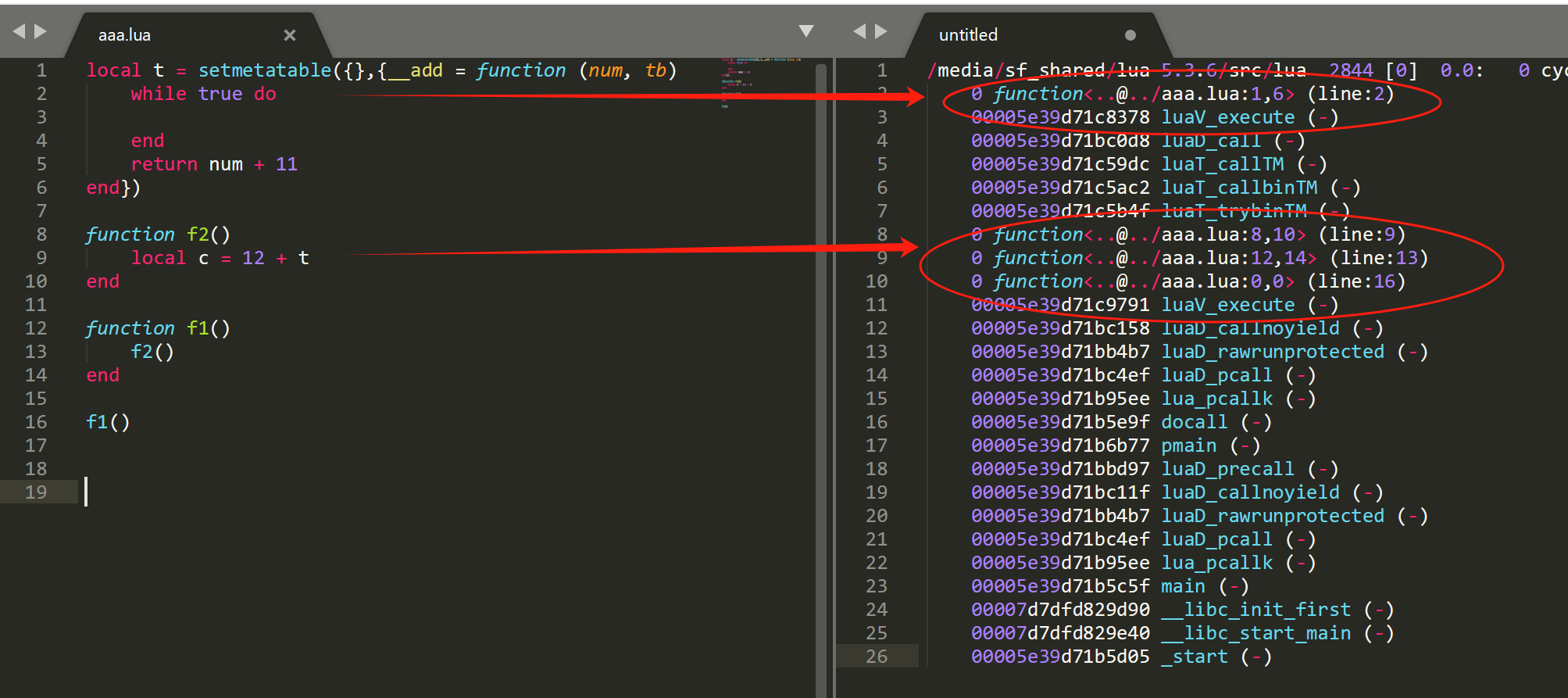
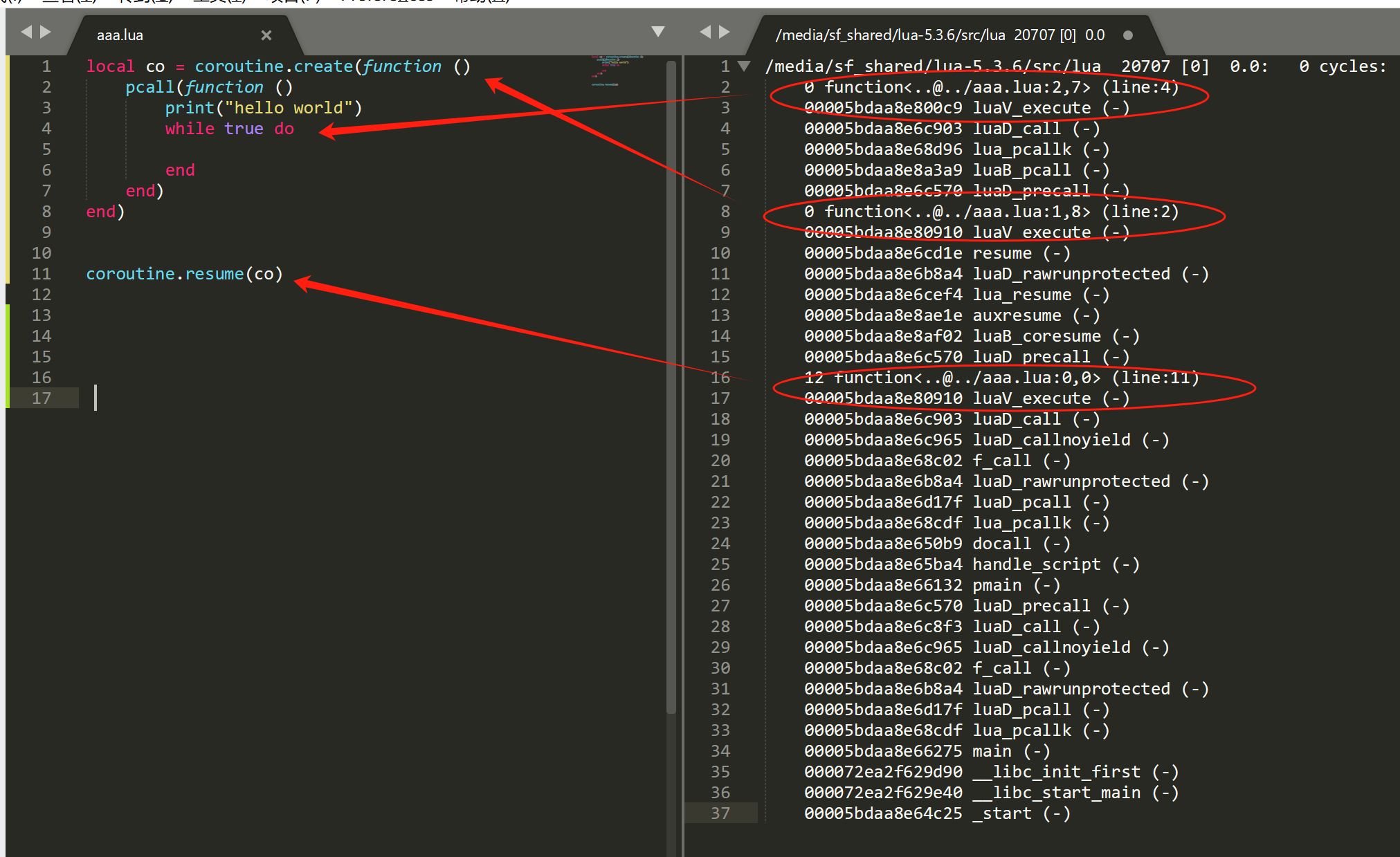
下面是我用性能功能获取到原始的 c 和 lua(根据 CallInfo 链表获取) 堆栈结果。从 lua 堆栈结果可以看出, f2 函数内执行的 12 + t 并没有产生新的 CallInfo 对象,即 __add 没有 CallInfo,直接从 luaV_execute进入到 luaT_trybinTM 调用,但 __add 指向的 lua 匿名函数,是会产生一个新的 CallInfo 的,然后进入到 luaV_execute 执行 lua 1~6 行的代码。

上面有两个 luaV_execute 调用,遇到这个情况,并不知道哪几个 lua 函数对应哪个 luaV_execute ,我们只能另想他法去做合并了,幸运的是,在luaV_execute执行 lua 指令前,会先给 CallInfo 调用栈帧对象设置一个状态 CIST_FRESH = 8,我们可以用这个标记来做分界线,哪些 CallInfo 对应哪个luaV_execute。在看看上图 lua 堆栈打印的 callstatus 中,我们发现只有 (line:2,callstatus:10) 和 (line:16,callstatus:10) 是带CIST_FRESH,因为 10二进制是 1010,8的二进制是 1000,第 4 位是1,所以包含CIST_FRESH标记。这样我们就可以知道,<aaa.lua:0,0>、<aaa.lua:12,14>、<aaa.lua:8,10> 是对应第 7 行的 luaV_execute 的,<aaa.lua:1,6> 是对应第 2 行的 luaV_execute 。
最终的合并结果如下图:
多线程合并
我们创建一个子线程 co,看看堆栈是怎么样的:

同样使用性能工具获取原始 c 和 lua 函数堆栈,观察发现 lua 栈,lua 函数栈之间,都有一个或多个 c 函数 CallInfo,可以使用最开始介绍第一种方式,用 c 函数地址来做合并分割的依据。
最终堆栈合并如下:
总结为如下图:

在实践过程中,发现如果是 yield 挂起子线程,再到 resume 恢复子线程执行的话,lua 和 c 合并输出堆栈会有些问题。
我们先看看下面的例子,看看从第一次启动 resume 和 yield 到 resume 后,lua 打印的堆栈:

我们发现 yield 前后两次 debug.traceback() 打印,并没有什么堆栈上的区别,看着都是从 pcall 调用而来,但实际上,其实2次的 resume 到 debug.traceback(),真实的函数调用链并不包含 pcall。为什么这么说呢,我们可以通过 vscode 断点调试看看,为了调试方便,我把第2处的 debug 打印,改成 while 死循环, while 对应的指令码为 JMP(通过 luac -l aaa.lua 查看文件对应的指令列表),我们可以在 luaV_execute 中的 OP_JMP 部分加断点,看看真实的 c 函数调用链。

用 vscode 断点调试看到,下面蓝框部分,证明已经执行到 while 循环处。接着主要看看左边的 c 堆栈打印,我们发现 lua 在第2次 resume 到 while 之间,并没有 pcall 对应的 luaB_pcall 身影,这是为什么呢。

现在来公布下答案,主要是因为第一次 yield 调用时,会执行 longjmp,回到 resume 处,导致 pcall 对应的 c 函数 luaB_pcall 堆栈已经被破坏了,后面再次执行 resume 时,只能通过 unroll 函数来执行 yield 后半部分 lua 代码了(关于 lua 多协程实现,可以看另一篇博客)。
而我们最开始给的例子,print("hello world 2")后调用 debug.traceback(),堆栈为啥又会有 pcall 的身影呢,这是因为有 CallInfo 构成的链表存在。
我们知道每个 lua 函数,或者 lua 发起 c 函数调用,都会有一个 CallInfo 与之对应,此时,CallInfo 就保存有 pcall 对应的 luaB_pcall 函数地址信息。虽然 longjmp 会破坏 c 函数堆栈,但却不会影响到子线程 CallInfo 链表。所以,我们通过 debug.traceback 回溯的其实是 CallInfo 链表。
下面是性能工具采集到的原始 lua 和 c 堆栈:

我们看到,lua CallInfo 构造的链表有7个 CallInfo对象,通过看 line:xx 知道对应右边 lua 代码中的哪一行。c 函数我没收集真实函数地址,所以这里略有不足。后面有机会再加下把。不过,我们采集到的 c 堆栈和上面 vscode 调试的一致,接下来就是合并 lua 了。
在合并 lua 堆栈时,从上往下合并的, 第一个 <aaa.lua:3,13> 应该合并到第2行的 luaV_execute 上面。<aaa.lua:2,14> 这个对应的 pcall CallInfo,应该要剔除掉,因为之前说过 ,resume 恢复 yield 挂起部分代码,是找不到 pcall 对应的函数了。那我们去掉的依据是什么呢。
我的做法,还是按照 lua - c - lua 原则,先遍历 c 堆栈数组,遇到第一个 luaV_execute 时,就去查找 lua 堆栈数组,先输出 <aaa.lua:3,13>,发现下一个是 c 函数地址,终止遍历,回到 c 堆栈数组,接着输出,当再次发现第2个 luaV_execute 时,此时,lua 堆栈数组按记忆上次遍历中断下标,应该遍历到 35 行的 <aaa.lua:2,14>,但这个 luaV_execute 和 第1个 luaV_execute 的 lua_State 线程对象是不同,我们在 bpf 收集 lua 堆栈时,知道 <aaa.lua:3,13> 和 <aaa.lua:2,14> 都是属于第一个 luaV_execute(lua_State *L)的,子线程 L 的对应的 CallInfo,不属于第2个 luaV_execute(lua_State *L)。所以要剔除掉 <aaa.lua:2,14>,然后接着遍历,往后查找 lua 堆栈,当找到 <aaa.lua:0,0> 时,就可以输出了,做为第2个 luaV_execute 的 lua 函数展开。
最终合并结果如下:

这样,resume 就和 lua 堆栈对应上了。
之前没发现这个 pcall 应该剔除的时候,输出的堆栈是长下面这样子的(错误情况):

错误堆栈合并
到了这里,就万事大吉了吗,然而并不是,我们先看下面一个例子,右边是采集到的正确堆栈情况:

但在多采集几次过后,发现会出现下面的情况: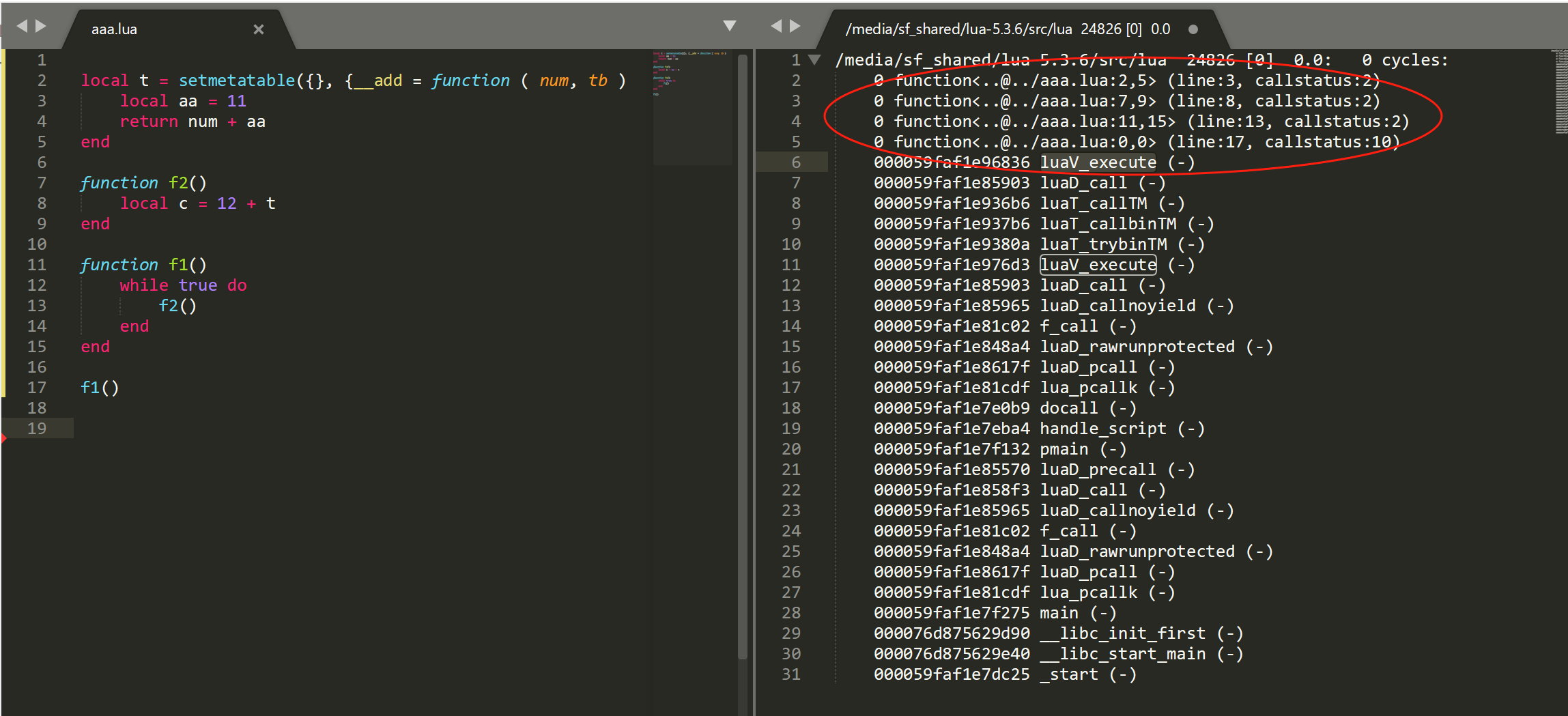
lua 全部堆栈合并到第1个 luaV_execute 中了,而第2个 luaV_execute 没有合并到任何的 lua 堆栈,为啥会出现这种情况呢。
因为我们在 bpf 内核空间采集的堆栈都是目标程序运行时的某一个时刻的,这样就不确定目标程序会运行到哪一行代码。我们之前提到过元方法调用是没有对应的 CallInfo 的,这样就导致没有一个 分界线,不知道哪些 lua 堆栈对应到哪个 luaV_execute上。你可能会问,__add 指向的匿名函数<aaa.lua:2,5> 在 luaV_execute 里执行指令前,不是会设置 CallInfo.callstatus 状态为 CIST_FRESH 吗,用 callstatus 不能区分吗,答案是能,但是,如果还没来得及设置呢。也就是说,上面的 lua 堆栈 0 function<..@../aaa.lua:2,5> (line:3, callstatus:2)callstatus 状态不是 10,我们就不知道它是不是做为第1个 luaV_execute 的分界线了,只有在遇到 0 function<..@../aaa.lua:0,0> (line:17, callstatus:10)这个时候,状态才是10,才能做为分界线的依据。所以,在这种先拿到最新的 CallInfo,但目标程序又还没进入到 luaV_execute 的情况下,导致后一个 luaV_execute 没有多余的 lua 堆栈可合,就算有,也是错误的。
还有另一种情况,我们看看下面采集到堆栈合并:

这次合并明显也是错误的,因为在右边的 lua 代码中,执行 8 行代码,对应的 luaV_execute 应该是第2个 luaV_execute 才对,因为第1个 luaV_execute 对应的代码只能是 __add 元方法指向的匿名函数 <aaa.lua:2,5>。
为啥会出现这种情况呢,同样是因为在 bpf 内核空间采集的堆栈,对应采集的那一刻,目标程序运行到哪一行 c 代码是不确定的。我们发现有 luaD_poscall 和 moveresults 函数调用,这两个函数主要是完成对应 OP_RETURN 指令的。也就不难猜测,此时采集到的堆栈,L->ci 指向前一个 ci 了,只是还停留在第1个luaV_execute函数中,还没来得及退出。
此时,如果 luaD_poscall 执行完 L->ci = ci->previous;代码,但还没退出luaV_execute 的话,就有可能出现这种情况了。
所以,在 luaV_execute 进入前,或者进入后,执行 OP_RETURN 指令,都有可能存在一些堆栈合并错误的情况,目前还没想到有什么好一点的解决方法。或许还有其他合并错误的情况没发现,但目前比较明显的就这两种情况了。
不过这种错误合并情况也是小概率发生,并不影响主体,当然,我们也可以提供选项,只输出 lua 堆栈信息。在了解 eh_frame 堆栈回溯,ebpf 技术,lua 函数实现等原理后,做个通用的,不嵌入目标程序的 lua 堆栈分析工具并不难。此外,我们还可以这个工具,对 lua 程序出现的死循环,或者热点函数进行及时发现。
lua 堆栈函数名
做性能分析,要获取到原函数位置对应的函数名才是有意义的,比如 :
local f1 = function ()
print(debug.traceback())
end
local a1 = f1
local b1 = f1
a1()
b1()
--[[
输出结果:
D:\download\lua-5.3.6>lua aaa.lua
stack traceback:
aaa.lua:4: in local 'a1'
aaa.lua:9: in main chunk
[C]: in ?
stack traceback:
aaa.lua:4: in local 'b1'
aaa.lua:10: in main chunk
[C]: in ?
]]对于 a1,b1两个变量引用 f1 函数,虽然当前是通过 a1(),b1() 间接调用 f1,通过 debug.traceback() 打印堆栈有 a1,b1 没错,但如果是做性能分析,它们是两次不同的调用的。
因为性能分析,我们收集的是每个函数调用时对应的函数名字符串,函数堆栈打印,是用函数名来表示,比如上面的 "main->a1',"main->b1",我们通过函数名字符串采集到的就是两次不同的调用,但实际上,其实a1,b1指向同一个函数调用。所以最终应该用 "main->f1" 记录调用次数为2才对,而不是"main->a1","main->b1" 各一次。但 f1 是一个变量,最终也有可能指向其他地方。在 lua 中,所有的函数都是匿名函数,可以赋值给任意变量,我们可以用一个变量来存储函数的引用。性能分析函数调用次数,就不正确了,所以目前为了准确定位是哪个匿名函数被调用,只输出函数所在的文件名,以及对应的起始行号,和结束行号,还有额外的调用函数时,所在的行号信息。
下面是我采集的一个 lua 很出名的服务端框架 skynet 堆栈火焰图。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号