视图、事务、触发器、存储过程、数据库设计三大范式
一、视图
1、什么是视图
将SQL语句的查询结果称之为一张虚拟表,我们将这张虚拟表 可以称之为 视图。视图就是虚拟表。
2、为什么用视图
将多张表拼接起来,做成视图,方便于后期的直接查询。节省拼接表的时间消耗。
3、如何使用视图
create view teacher2course as select * from teacher inner join course on teacher.tid = course.teacher_id;
注意: 在硬盘中,视图只有表结构文件, 没有表数据文件
视图通常是用于查询,尽量不要修改视图中的数据。
删除视图语句:drop view teacher2course;
开发过程中会不会去使用视图?
二、触发器:
在满足对某张表数据的增删改查的情况下,达到某个条件时自动触发的功能称之为触发器。
1. 在你对表进行增删改查的时候,支持你定义的触发器。
2.增前、增后,改前,改后,删前,删后
3.创建触发器完整语句:create trigger 触发器的名字 before/after insert/update/delete on 表名 for each row
begin
sql语句。。。
end
4.触发器命名规律:
tri_before_insert_t1 表示 插入之前触发 触发器
5.为何要用触发器?
触发器专门针对我们对某一张表数据增insert、删delete、改update的行为,这类行为一旦执行 就会触发触发器的执行,即自动运行另外一段sql代码
# 案例 CREATE TABLE cmd ( id INT PRIMARY KEY auto_increment, USER CHAR (32), priv CHAR (10), cmd CHAR (64), sub_time datetime, #提交时间 success enum ('yes', 'no') #0代表执行失败 ); CREATE TABLE errlog ( id INT PRIMARY KEY auto_increment, err_cmd CHAR (64), err_time datetime ); delimiter $$ # 将mysql默认的结束符由;换成$$ create trigger tri_after_insert_cmd after insert on cmd for each row begin if NEW.success = 'no' then # 新记录都会被MySQL封装成NEW对象 insert into errlog(err_cmd,err_time) values(NEW.cmd,NEW.sub_time); end if; end $$ delimiter ; # 结束之后记得再改回来,不然后面结束符就都是$$了
三、修改cmd中 sql语句的结束符
sql语句默认的是以 分号结束。
delimiter $$ # 表示 将mysql默认的结束符由;换成$$
delimiter ; # 表示 结束之后改回来,不然后面结束符就都是$$
四、事务:
保证数据操作的安全性,一致性,如果事务中有操作失败了,整体就算失败,要么同时成功,要么同时失败。支持回滚操作,一旦数据操作不符合预期,可以回滚到上一个状态
开启事务:start transaction (pycharm中开启事务操作)
回滚:rollback
确认:commit
1.事务的四大特性ABCD
原子性(atomicity):
一致性(consistency):事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
隔离性(isolation):一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性(durability):持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
2.事务的作用:
保证了对数据操作的数据安全性
案例:用交行的卡操作建行ATM机给工商的账户转钱
3.如何使用事务?
create table user( id int primary key auto_increment, name char(32), balance int ); insert into user(name,balance) values ('wsb',1000), ('egon',1000), ('ysb',1000); start transaction; # 修改数据之前先开启事务操作 # 修改操作 update user set balance=900 where name='wsb'; #买支付100元 update user set balance=1010 where name='egon'; #中介拿走10元 update user set balance=1090 where name='ysb'; #卖家拿到90元 rollback; # 回滚到上一个状态 commit;
# 开启事务之后,只要没有执行commit操作,数据其实都没有真正刷新到硬盘 # 开启事务检测操作是否完整,不完整主动回滚到上一个状态,如果完整就应该执行commit操作
五、存储过程
是指自定义函数:内部封装了一系列的sql语句,让不会mysql操作的人也能够通过调用该存储过程来操作数据库
1、创建存储过程的语法结构:
delimiter $$
create procedure 存储过程的名字(
形参1,
形参2,
形参3
)
begin
sql语句;
end$$
delimiter ;
创建存储过程
delimiter $$ create procedure p1( in m int, # in表示这个参数必须只能是传入不能被返回出去 in n int, out res int # out表示这个参数可以被返回出去,还有一个inout表示即可以传入也可以被返回出去 ) begin select tname from teacher where tid > m and tid < n; set res=0; end $$ delimiter ;
\G表示优化表的格式。\C表示 删除sql语句
select * from mysql.user\G; # 小知识点补充,当一张表的字段特别多记录也很多的情况下,终端下显示出来会出现显示错乱的问题
2、如何使用存储过程
大前提:存储过程在哪个库 下面创建的,只能在对应的库 下面才能使用
01、使用方法一、直接在MySQL中调用 # 1
set @res=10 # res的值是用来判断存储过程是否被执行成功的依据,所以需要先定义一个变量@res存储10 call p1(2,4,10); # 报错 call p1(2,4,@res); select @res; # 查看结果,执行成功,因为 @res变量值发生了变化。由10 变成了 0
02、使用方法二、在python程序中调用
import pymysql conn = pymysql.connect( user = 'root', password = '123456', host = '127.0.0.1', port = 3306, db = 'day36_1', charset = 'utf8', autocommit = True ) cursor_obj = conn.cursor(pymysql.cursors.DictCursor) res = cursor_obj.callproc('p1',(1,6,10)) # callproc() 表示调用 存储过程。 print(cursor.fetchall())
cursor.execute('select @_p1_2')
print(cursor.fetchall())
""" 内部自动用变量存储 @_p1_0=1 @_p1_1=6 @_p1_2=10; 规律:@_存储过程的名字_索引 = 值 """
六、函数
指的是:mysql的内置函数,只能在sql语句中使用
例子:
CREATE TABLE blog ( id INT PRIMARY KEY auto_increment, NAME CHAR (32), sub_time datetime ); INSERT INTO blog (NAME, sub_time) VALUES ('第1篇','2015-03-01 11:31:21'), ('第2篇','2015-03-11 16:31:21'), ('第3篇','2016-07-01 10:21:31'), ('第4篇','2016-07-22 09:23:21'), ('第5篇','2016-07-23 10:11:11'), ('第6篇','2016-07-25 11:21:31'), ('第7篇','2017-03-01 15:33:21'), ('第8篇','2017-03-01 17:32:21'), ('第9篇','2017-03-01 18:31:21'); select date_format(sub_time,'%Y-%m'),count(id) from blog group by date_format(sub_time,'%Y-%m');
七、流程控制
1、if 条件语句
01、 if....then...
02、elseif
03、else
04、end if
# if条件语句 delimiter // CREATE PROCEDURE proc_if () BEGIN declare i int default 0; if i = 1 THEN SELECT 1; ELSEIF i = 2 THEN SELECT 2; ELSE SELECT 7; END IF; END // delimiter ;
2、while 循环
while...end while
# while循环 delimiter // CREATE PROCEDURE proc_while () BEGIN DECLARE num INT ; SET num = 0 ; WHILE num < 10 DO SELECT num ; SET num = num + 1 ; END WHILE ; END // delimiter ;
八、索引与慢查询优化
primary key : 约束条件:非空且唯一
unique key: 约束条件:唯一
index key: 没有约束条件:只会帮你加速查询
1.什么是索引?
索引:类似于书的目录,在MYSQL中也叫做 键,是存储引擎用于快速找到记录的一种数据结构。
2.为什么有索引?
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新 操作很少出现性能问题。我们遇到最多,最容易出现问题的还是一些复杂的查询操作。为了加快数据的查询。
3.索引的优点缺点
索引虽然能够加速数据的查询,但不是建的索引越多越好。
因为在插入或者修改数据的时候,索引反而会降低速度(索引的反复销毁与)
进程池,比如开了20个进程,当一个进程服务客户端到死,才会返回到进程池。开完20个进程后,可以一直使用,不用反复开。
要想永久保存数据,就要把数据读到硬盘上。内存是临时存储,关机后,数据就消失了。
4.索引的数据结构
01、树
树状图是一种数据结构。
02、B+树
是通过二叉查找树,再由平衡二叉树,B树演化而来。
索引的字段尽可能的小。因为IO次数取决于B+树的高度H (这是主键是ID的原因)
索引的最左匹配特性。谁在最左边,先搜索谁。但是若缺失一个,则会降低搜索效率。
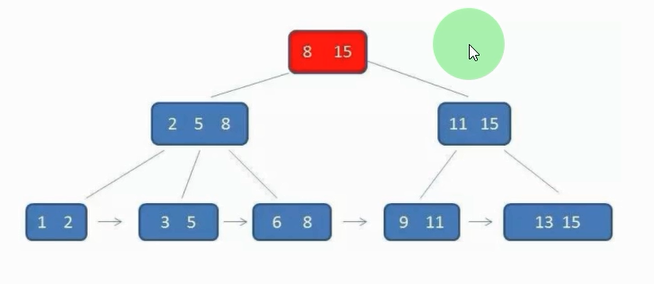
5.索引的种类
注意 myisam在建表的时候对应到硬盘有几个文件(三个)
聚集索引:就是主键(primary key)
辅助索引(unique,index):给主键意以为的字段建立的索引,就是辅助索引
覆盖索引:只在辅助索引的叶子节点中就已经找到了所有我们想要的数据
select name from userinfo where name='jason'
非覆盖索引:虽然查询的时候命中了索引字段name,但是要查的是age字段,所以还需要利用主键才去查找
select age from user where name='jason';
九、慢查询优化的基本步骤
十、数据库设计的三种范式
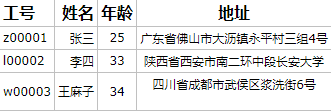
第一范式(1NF)
数据表中的每一个字段都必须是不可拆分的最小单元,确保每一个字段的原子性。
不符合第一范式:因为地址字段 可以再分
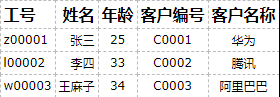
第二范式(2NF)
首先必须满足1NF,然后表中的所有字段,都必须完全依赖于主键,而不能有任何一列与主键没有关系,确保一张表只描述一件事情。
不符合第二范式:因为客户编号和客户名称并不依赖于工号这个主键。要拆
第三范式(3NF)
在满足2NF的基础上,表中的每一个字段只与主键直接相关而不是间接相关,即表中的每一个字段只能直接依赖于主键。
不符合第三范式:因为 “部门电话” 依赖于 “所在部门”, 而 “所在部门” 依赖于 “工号” 这种传递依赖关系, “部门电话” 字段并不直接依赖于工号这个主键。要拆
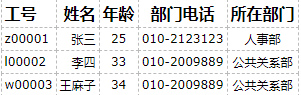
总结:
第一范式:表中的每一个字段能不能再细分。(字段原子性)
第二范式:表能不能拆分成互相独立的多个表。(每个表至描述一种东西)
第三范式:已经分成的多个表如果有关联,那么在一张表中只能存在另外一张关联表的主键。(通过外键来查询信息)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号