GIL全局解释器锁、协程、TCP服务端并发
一、gevent 模块
1、monkey 猴子补丁
monkey.patch_all() # 监听所有的任务是否有IO操作
2、spawn 是一个方法函数 #spawn是Greenlet类中的spawn方法。def spawn(cls, *args, **kwargs):
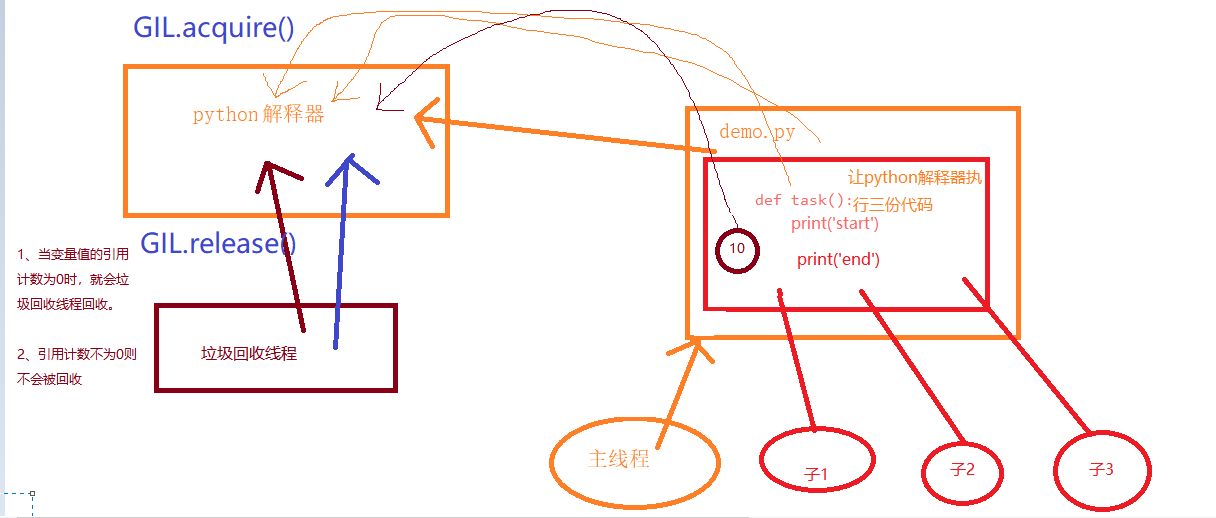
一、GIL全局解释器锁(python解释器自带的):本质是一把互斥锁,保证解释器级的数据安全
在Cpython解释器中,因为Cpython的内存管理不是线程安全。同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势。
gc:表示的是 垃圾回收机制 (import gc)

GIL全局解释器锁的优缺点:
1.优点:保证数据的安全
2.缺点:单个进程下,开启多个线程,牺牲执行效率,无法实现并行,只能实现并发。
例子:GIL全局解释器锁是python解释器自带的,当没有IO时,同一个进程下开启的多线程,同一时刻只能有一个线程执行。多个线程是 串行。一个线程抢到 python解释器权限锁后,执行完后,释放锁,然后另一个线程再使用。这时进程间的数据是共享的。
from threading import Thread n = 100 def task(): global n m = n n = m - 1 if __name__ == '__main__': list1 = [] for line in range(10): t = Thread(target=task) t.start() list1.append(t) for t in list1: t.join() print(n) #90
例子:GIL全局解释器锁是python解释器自带的,当遇到IO时,同一个进程下开启的多线程,多个线程是并发。一个线程抢到 python解释器权限锁后,遇到IO后,释放锁,然后另一个线程再使用,遇到IO后,释放锁。。。。
from threading import Thread import time n = 100 def task(): global n m = n time.sleep(2) n = m - 1 if __name__ == '__main__': list1 = [] for line in range(10): t = Thread(target=task) t.start() list1.append(t) for t in list1: t.join() print(n) #99
二、多进程与多线程的应用
1.多进程:计算密集型
2.多线程:IO密集型
3、IO密集型任务,每个任务4s
01、单核: 开启多线程比多进程节省资源。
02、多核:多线程: - 开启4个子线程: 16s
多核:多进程:开启4个进程: 16s + 申请开启资源消耗的时间
4、计算密集型任务,每个任务4s
01、单核:开启线程比进程节省资源。
02、多核:多线程:开启4个子线程: 16s
多核:多进程: 开启多个进程: 4s
例子:计算密集型:多进程
IO密集型:多线程


import time from multiprocessing import Process def task1(): i = 10 for line in range(10000000): i += 1 def task2(): time.sleep(3) if __name__ == '__main__': # 测试多进程: start_time = time.time() list1 = [] for line in range(6): p = Process(target=task1) # 计算密集型 p.start() list1.append(p) for p in list1: p.join() end_time = time.time() print(f'计算密集型消耗时间: {end_time - start_time}') start_time = time.time() list1 = [] for line in range(6): p = Process(target=task2) # IO密集型 p.start() list1.append(p) for p in list1: p.join() end_time = time.time() print(f'IO密集型消耗时间: {end_time - start_time}') # 结果: # 计算密集型消耗时间: 4.038231134414673 # IO密集型消耗时间: 4.3572492599487305 import time from threading import Thread def task1(): i = 10 for line in range(10000000): i += 1 def task2(): time.sleep(3) if __name__ == '__main__': # 测试多线程: start_time = time.time() list1 = [] for line in range(6): t = Thread(target=task1) # 计算密集型 t.start() list1.append(t) for t in list1: t.join() end_time = time.time() print(f'计算密集型消耗时间: {end_time - start_time}') start_time = time.time() list1 = [] for line in range(6): t = Thread(target=task2) # IO密集型 t.start() list1.append(t) for t in list1: t.join() end_time = time.time() print(f'IO密集型消耗时间: {end_time - start_time}') 结果: 计算密集型消耗时间: 4.509257555007935 IO密集型消耗时间: 3.001171827316284
三、协程:
1.什么是协程
进程是资源单位
线程是执行单位
协程是单线程下实现并发,协程不是任何单位,只是一个程序员YY出来的东西。
协程的目的:
手动实现 "遇到IO切换 + 保存状态" 去欺骗操作系统,让操作系统误以为没有IO操作,将CPU的执行权限给你。
在IO密集型的情况下,使用协程能提高最高效率。
例子1、协程实现方法一:
patch_all() 是一个函数方法
spawn() 是类下的一个函数,里面有 start 属性了。所以可以不用写 对象.start 了
from gevent import monkey # 猴子补丁 monkey.patch_all() # 监听所有的任务是否有IO操作 from gevent import spawn # spawn(任务) import time def task1(): print('start from task1...') time.sleep(1) print('end from task1...') def task2(): print('start from task2...') time.sleep(3) print('end from task2...') def task3(): print('start from task3...') time.sleep(5) print('end from task3...') if __name__ == '__main__': start_time = time.time() sp1 = spawn(task1) sp2 = spawn(task2) sp3 = spawn(task3) sp1.start() sp2.start() sp3.start() sp1.join() sp2.join() sp3.join() end_time = time.time() print(f'消耗时间: {end_time - start_time}') 结果: start from task1... start from task2... start from task3... end from task1... end from task2... end from task3... 消耗时间: 5.010286569595337 # 因为是多线程,异步(同时)提交任务。并发执行。 Process finished with exit code 0
例子2、协程实现方法二:
from gevent import monkey # 猴子补丁 monkey.patch_all() # 监听所有的任务是否有IO操作 from gevent import spawn # spawn(任务) from gevent import joinall import time def task1(): print('start from task1...') time.sleep(1) print('end from task1...') def task2(): print('start from task2...') time.sleep(3) print('end from task2...') def task3(): print('start from task3...') time.sleep(5) print('end from task3...') if __name__ == '__main__': start_time = time.time() sp1 = spawn(task1) sp2 = spawn(task2) sp3 = spawn(task3) joinall([sp1, sp2, sp3]) end_time = time.time() print(f'消耗时间: {end_time - start_time}') 结果: start from task1... start from task2... start from task3... end from task1... end from task2... end from task3... 消耗时间: 5.011286497116089 Process finished with exit code 0
四、TCP服务端多线程并发
client 文件 import socket client = socket.socket() client.connect(('127.0.0.1', 9000)) print('Client is run....') while True: msg = input('客户端>>:').encode('utf-8') client.send(msg) data = client.recv(1024) # 接收数据 print(data)
server 文件 import socket from concurrent.futures import ThreadPoolExecutor server = socket.socket() server.bind(('127.0.0.1', 9000)) server.listen(5) def run(conn): # 封装成一个函数 while True: try: data = conn.recv(1024) # 接收数据 if len(data) == 0: break print(data.decode('utf-8')) conn.send('111'.encode('utf-8')) except Exception as e: break conn.close() if __name__ == '__main__': print('Server is run....') pool = ThreadPoolExecutor(50) # 线程池 while True: conn, addr = server.accept() # 反复产生通道 print(addr) pool.submit(run, conn) # 产生线程。
注意:submit() 是一个对象


 浙公网安备 33010602011771号
浙公网安备 33010602011771号