损失函数与梯度下降
什么是损失函数
- 损失函数(Loss Function)也称代价函数(Cost Function),用来度量预测值与实际值之间的差异
- 公式:
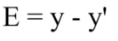
其中E即使损失函数,y表示真实值,y'表示预测值,损失函数即使预测值与实际值之间的差
损失函数的作用
- 度量决策函数内f(x)和实际值之间的差异
- 作为模型性能参考。损失数值越小,说明预测输出和实际结果(也称期望输出)之间的差值就越小,也就说明我们构建的模型越好。学习的过程,就是不断通过训练数据进行预测,不断调整预测输出与实际输出差异,使得损失值最小的过程
常用损失函数
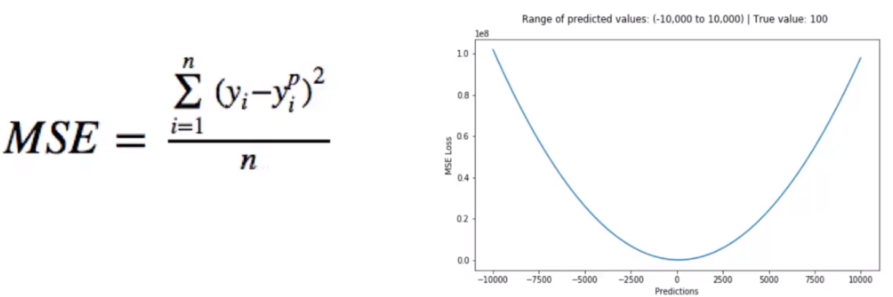
- 均方误差(Mean square error)损失函数。均方误差是回归问题或连续问题常用的损失函数,它是预测值与目标值之间差值的平方和,其公式和图像如下:
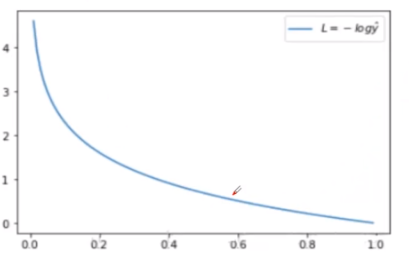
- 交叉熵(Cross Entrioy)。交叉熵是Shannon信息论中的一个重要概念,主要用于度量两个概率分布间的差异性信息,在机器学习中用来作为分类问题的损失函数。假设有两个概率分布,tk(真实概率)和yk(预测概率),其交叉熵函数公式及图形如下:
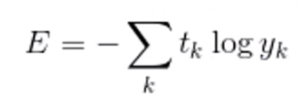
梯度下降
什么是梯度
- 梯度(gradient)是一个向量(矢量,有方向),表示某一个函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大。损失函数沿梯度相反方向收敛最快(即能最快找到极值点)。当梯度向量为零(或接近于0),说明损失函数到达一个极小值点,模型准确度达到一个极大值点。
- 通过损失函数,我们将“寻找最优参数”问题,转换为了“寻找损失函数最小值”问题。寻找步骤:
1.损失是否足够小?如果不是,计算损失函数的梯度。
2.按梯度的反方向走一小步,以缩小损失。
3.循环到1
这种按照负梯度不停地调整函数权值的过程就叫做“梯度下降法”。通过这样的方法,改变每个神经元与其他神经元的连接权重及自身的搁置,让损失函数的值下降的更快,进而将值收敛到损失函数的某个极小值。
导数
梯度下降算法会依赖于导数和偏导数
导数定义:所谓导数,就是用来分析函数“变化率”的一种度量。导数越大变化率越大,导数越小变化率越小,其公式为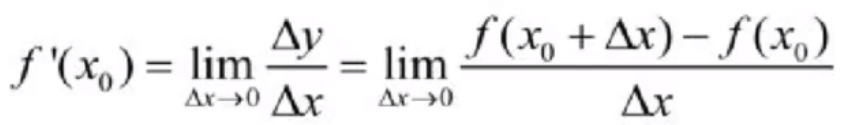
- 导数的含义:反应变化的剧烈程度(变化率)

偏导数
“偏导”的英文本意是“partial derivatives”(表示局部导数)。对于多维变量函数而言,当球某个变量的导数时,就是把其他变量视为常量,然后对整个函数求其导数(相比于全部变量,这里只求一个变量,即为“局部”)例:
学习率
- 如果在梯度下降过程中,每次都按照相同的步幅收敛,则可能错过极值点(下图左),所以每次在之前的步幅减小一定比率,这个比率称之为“学习率”(下图右)

梯度递减训练法则
- 神经网络中的权值参数是非常多的,因此针对损失函数E的权值向量的梯度如以下公式所示:
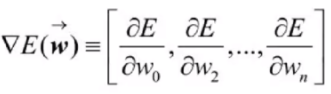
等式左侧表示损失函数E的梯度,它本身也是一个向量,它的多个维度分别由损失函数E对多个权值参数Wi求偏导所得。当梯度被解释为权值空间中的一个向量时,它就确定了E陡峭上升的方向,那么梯度递减的训练法则就如下所示:

梯度下降算法
- 批量梯度下降:批量梯度下降法(Batch Gradient Descent,BGD)是最原始的形式,它是指在每一次迭代时使用所有样本来进行梯度的更新,
- 优点
- 一次迭代是对所有样本进行计算,此时利用矩阵进行操作,实现了并行。
- 由全数据集去确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。当目标函数为凸函数时,BGD一定能够得到全局最优。
- 缺点
- 当样本数目m很大时,每迭代一步都需要对所有样本进行计算,训练过程会很慢。
- 优点
- 随机梯度下降:随机梯度下降法(Stochastic Gradient Descent,SGD)每次迭代使用一个样本对参数进行更新,使得训练速度加快。
- 优点
- 由于不是在全部训练数据上的损失函数,而是在每轮迭代中,随机优化某一条训练数据上的损失函数,这样每一轮参数的更新速度大大加快
- 缺点:
- 准确度下降。由于即使
- 优点
- 小批量梯度下降:小批量梯度下降(Mini-Batch Grradient Descent,MBGD)是对批量梯度下降以及随机梯度下降的一个折中方法、其思想是:每次迭代使用指定个(batch_size)样本来对参数进行更新。
- 优点:
- 通过矩阵运算,每次在一个batch上优化神经网络参数并不会比单个数据慢太多。
- 每次使用一个batch可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的结果。
- 缺点:
- batch_size的不当选择可能会带来一些问题
- 优点:
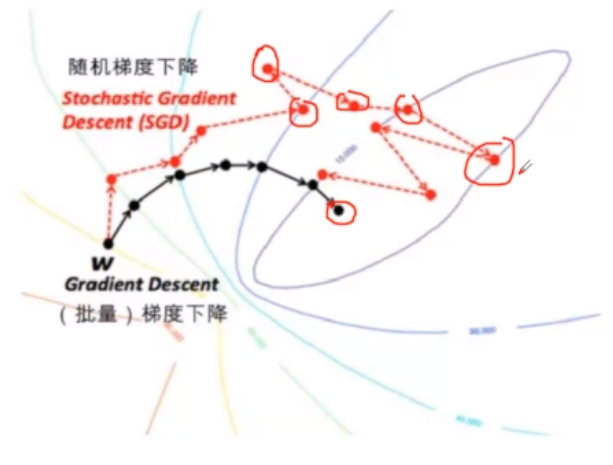
几种梯度下降算法收敛比较
- 批量梯度下降稳健地向着最低的前进的
- 随机梯度下降震荡明显,当总体上向最低点逼近
- 小批量梯度下降位于两者之间
小结
本章节介绍了损失函数与梯度下降概念与算法
- 损失函数用户度量预测值与期望值之间的差异,根据该差异值进行参数调整
- 梯度下降用于以最快速度、最少的步骤快速找到损失函数的极小值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号