微博热搜数据
------主题式网络主题式网络爬虫设计方案------
1.爬虫名称:爬取微博热搜
2.爬虫爬取的内容:爬取微博热搜数据。 数据特征分析:各数据分布紧密联系。
3.网络爬虫设计方案概述:
实现思路:通过访问网页源代码使用xpath正则表达爬取数据,对数据进行保存数据,再对数据进行清洗和处理,数据分析与可视化处理。
技术难点:在编程的过程中,若中间部分出现错误,可能导致整个代码需要重新修改。数据实时更新,会导致部分上传的图形不一致。
------主题页面的结构特征分析------
1.主题页面的结构和特征分析:爬取数据都分布在标签'div.cc-cd-cb nano has-scrollbar'里面,标题标签为'span.t',热度标签为'span.e'。
2.Htmls页面解析:

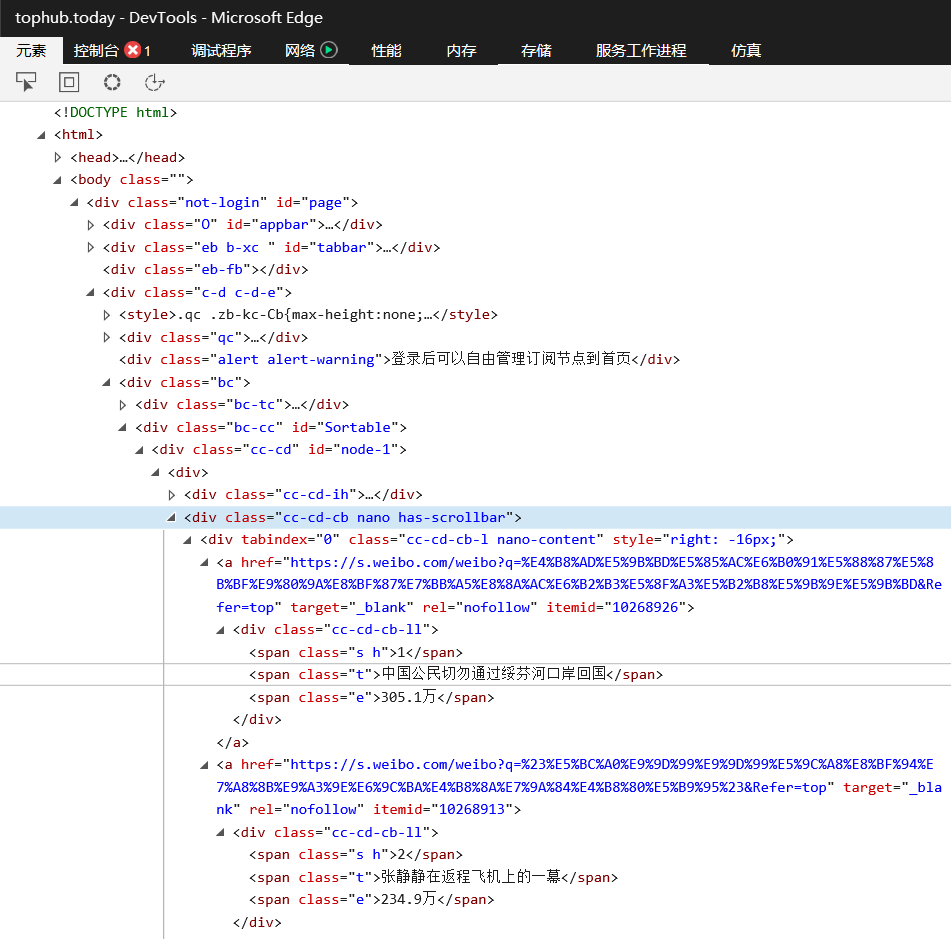
3.节点(标签)查找方法与遍历方法:通过xpath遍历标签。利用xpath正则表达查找。
------网络爬虫程序设计------
import requests from lxml import etree import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib from scipy.optimize import leastsq import scipy.stats as sts import seaborn as sns url = "https://tophub.today/" headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'} html = requests.get(url,headers = headers) html = html.content.decode('utf-8') html = etree.HTML(html) div = html.xpath("//div[@id='node-1']/div") for a in div: titles = a.xpath(".//span[@class='t']/text()") numbers = a.xpath(".//span[@class='e']/text()") b = [] for i in range(25): b.append([i+1,titles[i],numbers[i][:-1]]) file = pd.DataFrame(b,columns = ['排名','今日热搜','热度(单位为万)']) print(file) file.to_csv('微博热搜榜热度数据.csv')


2.对数据进行清洗和处理:
df = pd.DataFrame(pd.read_csv('微博热搜榜热度数据.csv')) df.head()

df.drop('今日热搜', axis=1, inplace=True) df.head()

df.isnull().sum()
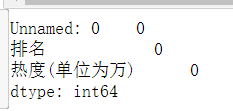
df[df.isnull().values==True]

df.describe()

3.数据分析与可视化:
df.corr()

sns.lmplot(x='排名',y='热度(单位为万)',data=df)

def one(): file_path = "'微博热搜榜热度数据.csv'" x = df['排名'] y = df['热度(单位为万)'] plt.xlabel('排名') plt.ylabel('热度(单位为万)') plt.bar(x,y) plt.title("绘制排名与热度条形图") plt.show() one()

def two(): x = df['排名'] y = df['热度(单位为万)'] plt.xlabel('排名') plt.ylabel('热度(单位为万)') plt.plot(x,y) plt.scatter(x,y) plt.title("绘制排名与热度折线图") plt.show() two()

def three(): x = df['排名'] y = df['热度(单位为万)'] plt.xlabel('排名') plt.ylabel('热度(单位为万)') plt.scatter(x,y,color="red",label=u"热度分布数据",linewidth=2) plt.title("绘制排名与热度散点图") plt.legend() plt.show() three()

4.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程:
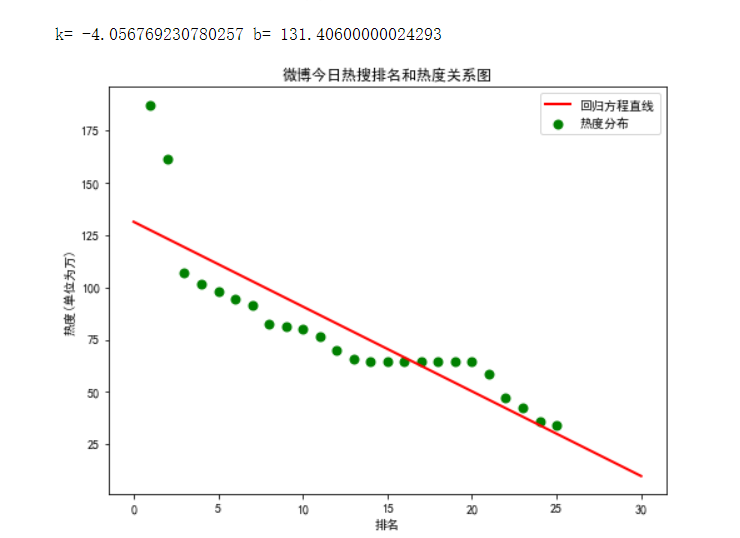
一元一次回归方程:
def main(): colnames = ["排名","今日热搜","number"] #由于运行存在问题,用number表示'热度(单位为万)' f = pd.read_csv('微博热搜榜热度数据.csv',skiprows=1,names=colnames) X = f.排名 Y = f.number def func(p,x): k,b = p return k*x+b def error_func(p,x,y): return func(p,x)-y p0 = [1,20] Para = leastsq(error_func,p0,args = (X,Y)) k,b = Para[0] print("k=",k,"b=",b) plt.figure(figsize=(8,6)) plt.scatter(X,Y,color="green",label=u"热度分布",linewidth=2) x=np.linspace(0,30,25) y=k*x+b plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2) plt.title("微博今日热搜排名和热度关系图") plt.xlabel('排名') plt.ylabel('热度(单位为万)') plt.legend() plt.show() main()
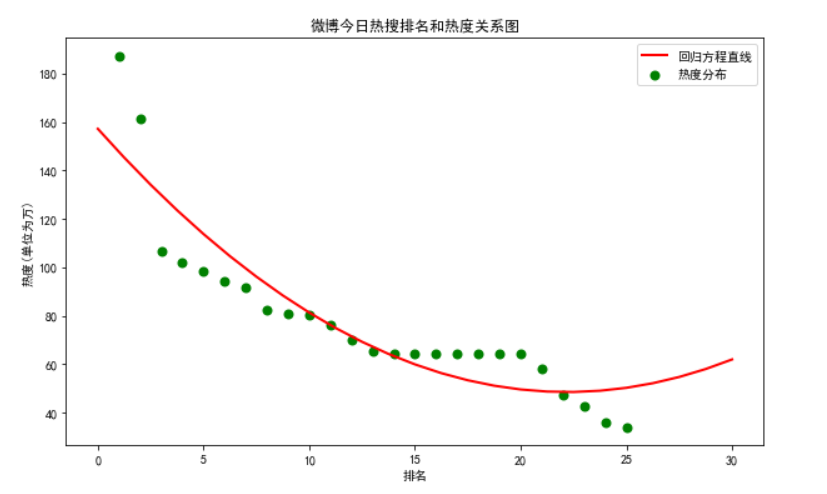
一元二次回归方程:
def four(): colnames = ["排名","今日热搜","number"] #由于运行存在问题,用number表示'热度(单位为万)' f = pd.read_csv('微博热搜榜热度数据.csv',engine='python',skiprows=1,names=colnames) X = f.排名 Y = f.number def func(p,x): a,b,c=p return a*x*x+b*x+c def error_func(p,x,y): return func(p,x)-y p0=[0,0,0] Para=leastsq(error_func,p0,args=(X,Y)) a,b,c=Para[0] plt.figure(figsize=(10,6)) plt.scatter(X,Y,color="green",label=u"热度分布",linewidth=2) x=np.linspace(0,30,25) y=a*x*x+b*x+c plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2) plt.title("微博今日热搜排名和热度关系图") plt.xlabel('排名') plt.ylabel('热度(单位为万)') plt.legend() plt.show() four()
5.完整代码:
1 import requests 2 from lxml import etree 3 import pandas as pd 4 import numpy as np 5 import matplotlib.pyplot as plt 6 import matplotlib 7 from scipy.optimize import leastsq 8 import scipy.stats as sts 9 import seaborn as sns 10 11 12 url = "https://tophub.today/" 13 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'} 14 html = requests.get(url,headers = headers)#发送get请求 15 #print(html.text)#获取源代码 16 17 18 19 html = html.content.decode('utf-8')#配置编码 20 html = etree.HTML(html)#构建一个xpath解析对象 21 22 div = html.xpath("//div[@id='node-1']/div") 23 for a in div:#遍历标签 24 titles = a.xpath(".//span[@class='t']/text()")#xpath正则表达 25 numbers = a.xpath(".//span[@class='e']/text()")#xpath正则表达 26 27 28 29 b = []#创建一个空列表 30 for i in range(25): 31 b.append([i+1,titles[i],numbers[i][:-1]])#拷贝前25组数据 32 file = pd.DataFrame(b,columns = ['排名','今日热搜','热度(单位为万)']) 33 #print(file) 34 35 file.to_csv('微博热搜榜热度数据.csv',encoding = 'gbk')#保存文件,数据持久化 36 37 38 #读取csv文件 39 df = pd.DataFrame(pd.read_csv("微博热搜榜热度数据.csv",engine='python')) 40 df.head() 41 42 43 #删除无效列与行 44 df.drop('今日热搜', axis=1, inplace=True) 45 df.head() 46 47 48 #空值处理 49 df.isnull().sum()#返回0,表示没有空值 50 51 52 #缺失值处理 53 df[df.isnull().values==True]#返回无缺失值 54 55 56 57 #用describe()命令显示描述性统计指标 58 df.describe() 59 60 #用corr()显示各数据间的相关系数 61 df.corr() 62 63 64 plt.rcParams['font.sans-serif'] = ['SimHei'] 65 66 plt.rcParams['axes.unicode_minus'] = False 67 68 69 #用seabron.lmplot()方法,建立排名和热度(单位为万)之间的线性关系 70 sns.lmplot(x='排名',y='热度(单位为万)',data=df) 71 72 73 74 #绘制排名与热度条形图 75 def one(): 76 file_path = "'微博热搜榜热度数据.csv'" 77 x = df['排名'] 78 y = df['热度(单位为万)'] 79 plt.xlabel('排名') 80 plt.ylabel('热度(单位为万)') 81 plt.bar(x,y) 82 plt.title("绘制排名与热度条形图") 83 plt.show() 84 one() 85 86 87 88 #绘制排名与热度折线图 89 def two(): 90 x = df['排名'] 91 y = df['热度(单位为万)'] 92 plt.xlabel('排名') 93 plt.ylabel('热度(单位为万)') 94 plt.plot(x,y) 95 plt.scatter(x,y) 96 plt.title("绘制排名与热度折线图") 97 plt.show() 98 two() 99 100 101 #绘制排名与热度散点图 102 def three(): 103 x = df['排名'] 104 y = df['热度(单位为万)'] 105 plt.xlabel('排名') 106 plt.ylabel('热度(单位为万)') 107 plt.scatter(x,y,color="red",label=u"热度分布数据",linewidth=2) 108 plt.title("绘制排名与热度散点图") 109 plt.legend() 110 plt.show() 111 three() 112 113 114 #绘制一元一次方程 115 def main(): 116 colnames = ["排名","今日热搜","number"] #由于运行存在问题,用number表示'热度(单位为万)' 117 f = pd.read_csv('微博热搜榜热度数据.csv',engine='python',skiprows=1,names=colnames) 118 X = f.排名 119 Y = f.number 120 121 122 def func(p,x): 123 k,b = p 124 return k*x+b 125 126 127 def error_func(p,x,y): 128 return func(p,x)-y 129 p0 = [1,20] 130 Para = leastsq(error_func,p0,args = (X,Y)) 131 k,b = Para[0] 132 133 print("k=",k,"b=",b) 134 135 plt.figure(figsize=(8,6)) 136 plt.scatter(X,Y,color="green",label=u"热度分布",linewidth=2) 137 x=np.linspace(0,30,25) 138 y=k*x+b 139 140 plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2) 141 plt.title("微博今日热搜排名和热度关系图") 142 plt.xlabel('排名') 143 plt.ylabel('热度(单位为万)') 144 plt.legend() 145 plt.show() 146 main() 147 148 149 #绘制一元二次方程 150 def four(): 151 152 colnames = ["排名","今日热搜","number"] #由于运行存在问题,用number表示'热度(单位为万)' 153 f = pd.read_csv('微博热搜榜热度数据.csv',engine='python',skiprows=1,names=colnames) 154 X = f.排名 155 Y = f.number 156 157 def func(p,x): 158 a,b,c=p 159 return a*x*x+b*x+c 160 161 def error_func(p,x,y): 162 return func(p,x)-y 163 164 p0=[0,0,0] 165 Para=leastsq(error_func,p0,args=(X,Y)) 166 a,b,c=Para[0] 167 plt.figure(figsize=(10,6)) 168 plt.scatter(X,Y,color="green",label=u"热度分布",linewidth=2) 169 170 x=np.linspace(0,30,25) 171 y=a*x*x+b*x+c 172 173 plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2) 174 plt.title("微博今日热搜排名和热度关系图") 175 plt.xlabel('排名') 176 plt.ylabel('热度(单位为万)') 177 plt.legend() 178 plt.show() 179 180 four()
总结:通过方程图可以更直观的看出热搜与热度之间的关系

 浙公网安备 33010602011771号
浙公网安备 33010602011771号