
Java Stream 从零到一
概述
Stream代表的是任意Java对象的序列。
怎么理解「序列」?
可以和
List做个对比。List存储的每个元素都是已经存储在内存中的某个Java对象;而Stream输出的元素可能并没有预先存储在内存中,而是实时计算出来的。因此,Stream是一种「惰性计算」。由于Stream中的元素是实时计算出来的,所以可以把它理解成它「存储」无限的元素。
Stream的特点:
-
可以「存储」有限个或无限个元素。这里的「存储」是带引号的。
-
Stream可以转换为另一个Stream,而非修改其本身。 -
惰性计算:一个
Stream转为另一个Stream时,实际上只存储了转换规则,并没有任何计算发生。真正的计算发生在最后结果的获取。createNaturalStream() .map(BigInteger::multiply) .limit(100) .forEach(System.out::println);
不可变的集合
基本概念
不可变的集合是指一旦创建后,集合中的元素不能被添加、删除、或修改的集合。不可变集合的一些使用场景如下:
- 如果某个数据不能被修改,把它防御性地拷贝到不可变集合中是一个很好的实践。
- 当集合对象被不可信的库调用时,不可变形式是安全的。
创建不可变集合
在 Java 中,java.util.Collections.unmodifiableCollection() 方法可以将一个普通的集合转换为不可变集合。此外,在 List、Set、Map 接口中,都存在静态的 of 方法,可以获取一个不可变的集合。这样创建出来的集合不能添加、不能修改、不能删除。
.of静态方法 Java8 不能用
Java 8 中,一般采用这样的方法来创建一个不可变的集合:
List<String> immutableList = Collections.unmodifiableList(Arrays.asList("A", "B", "C"));
Set<String> immutableSet = Collections.unmodifiableSet(new HashSet<>(Arrays.asList("A", "B", "C")));
Map<String, Integer> immutableMap = Collections.unmodifiableMap(new HashMap<String, Integer>() {{
put("A", 1);
put("B", 2);
put("C", 3);
}});
[!IMPORTANT]
Arrays.asList()和List.of()
List.of()是一个静态工厂方法,返回的是一个不可变的列表,这个列表不是由数组支持的,而是一个实现了List接口的独立对象。使用List.of()返回的列表,不能添加、删除或替换其中的元素。
Arrays.asList()返回的是一个 固定大小 的列表,它是java.util.Arrays的一个静态方法,这个列表是由数组支持的,所以他的元素可以直接通过数组的索引来访问。Arrays.asList()方法返回的列表,大小是固定的,如果尝试添加或删除元素,会抛出UnsupportedOperationException异常,因为底层数组的大小是固定的。(但是 IDEA 调.add方法不会有任何提示,因此要注意):List<String> list = Arrays.asList("a", "b", "c"); list.set(1, "z"); // 这是允许的,替换了索引为1的元素 System.out.println(list); list.add("d"); // 这将抛出 UnsupportedOperationException list.remove("a"); // // 这也将抛出 UnsupportedOperationException[a, z, c] Exception in thread "main" java.lang.UnsupportedOperationException at java.util.AbstractList.add(AbstractList.java:148) at java.util.AbstractList.add(AbstractList.java:108) at org.example.Main.main(Main.java:11)
创建Stream
Stream.of()
最简单的方式是直接使用Stream.of()静态方法,传入可变参数。不过这种方式比较没卵用。
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
Stream<String> stream = Stream.of("A", "B", "C", "D");
...
}
}
基于数组或Collection
直接基于数组或者Collection来创建Stream,这样Stream的元素就直接持有数组或者Collection的元素了。
import java.util.*;
import java.util.stream.*;
public class Main {
public static void main(String[] args) {
Stream<String> stream1 = Array.stream(new String[] {"H", "A", "L", "O"});
Stream<String> stream2 = List.of("D", "O", "G").stream();
...
}
}
- 将数组变为
Stream:使用Arrays.stream()方法。 - 将
Collection变为Stream:直接调用.stream()方法即可。
关于Primitives
Java泛型不支持Primitives,所以Stream<int>是非法的。但是用Stream<Integer>会频繁装箱拆箱,降低了效率。故Java直接提供了IntStream、LongStream、DoubleStream来直接使用primitive的Stream,其使用方法没有太大差别。
// 将int[] 数组变为IntStream
IntStream is = Arrays.stream(new int[]{1, 2, 3});
// 将Stream<String>转换为LongStream
LongStream ls = List.of("1", "2", "3").stream().mapToLong(Long::parseLong);
Stream的操作
Stream中有两种不同类型的操作:
-
Intermediate Operations
Intermediate Operations 可以将多个方法连接成一串,它具有如下的特点:
- 方法总是串联在一起;
- Intermediate Operations 可以将一个stream转换为另一个stream;
- Intermediate Operations 有「筛选」的概念,可以用一种方法筛选数据并在处理之后传递给下一个方法
-
Terminate Operations
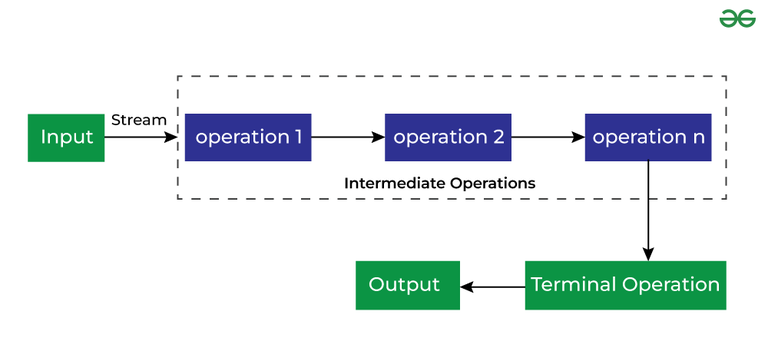
Intermediate Operations
使用 map()
map()操作把Stream的每个元素都应用一遍目标函数并输出结果。
Stream<Integer> s = Stream.of(1, 2, 3, 4, 5);
Stream<Integer> s2 = s.map(n -> n * n); // 1, 4, 9, 16, 25
List.of(" Apple ", " pear ", "ORAMGE", " BaNaNa ")
.stream()
.map(String::trim) // 去空格
.map(String::toLowerCase) // 变小写
.forEach(System.out::println); // 打印
使用 filter()
filter()操作对Stream的每个元素进行测试,如果不满足条件就直接pass掉。
IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9)
.filter(n -> n % 2 != 0) // 选择奇数,过滤掉偶数
.forEach(System.out::println);
使用 sorted()
用.sorted()方法即可。如果需要自定义排序方法,在其中传入指定的Comparator即可。
Syntax:
Stream<T> sorted()
Stream<T> sorted(Comparator<? super T> comparator)
Example:
List<String> list = List.of("Orange", "apple", "Banana")
.stream()
.sorted(String::compareToIgnoreCase)
.collect(Collectors.toList());
使用 flatMap()
flatMap()是把Stream的每个元素映射为Stream,然后合并成一个新的Stream。
Syntax:
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper)
Example:
Stream<List<Integer>> s = Stream.of(
Arrays.asList(1, 2, 3),
Arrays.asList(4, 5, 6),
Arrays.asList(7, 8, 9));
Stream<Integer> i = s.flatMap(list -> list.stream());
i.forEach(System.out::print);
Output:
123456789
使用 distinct()
移除重复元素
Syntax:
Stream<T> distinct()
使用 peek()
对每个元素执行操作,而不修改流。它返回一个由此流的元素组成的流,当从结果流中消耗元素时,还会对每个元素执行提供的操作。
Syntax:
Stream<T> peek(Consumer<? super T> action)
使用例
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
public class StreamIntermediateOperationsExample {
public static void main(String[] args) {
// List of lists of names
List<List<String>> listOfLists = Arrays.asList(
Arrays.asList("Reflection", "Collection", "Stream"),
Arrays.asList("Structure", "State", "Flow"),
Arrays.asList("Sorting", "Mapping", "Reduction", "Stream")
);
// Create a set to hold intermediate results
Set<String> intermediateResults = new HashSet<>();
// Stream pipeline demonstrating various intermediate operations
List<String> result = listOfLists.stream()
.flatMap(List::stream) // Flatten the list of lists into a single stream
.filter(s -> s.startsWith("S")) // Filter elements starting with "S"
.map(String::toUpperCase) // Transform each element to uppercase
.distinct() // Remove duplicate elements
.sorted() // Sort elements
.peek(s -> intermediateResults.add(s)) // Perform an action (add to set) on each element
.collect(Collectors.toList()); // Collect the final result into a list
// Print the intermediate results
System.out.println("Intermediate Results:");
intermediateResults.forEach(System.out::println);
// Print the final result
System.out.println("Final Result:");
result.forEach(System.out::println);
}
}
输出:
Intermediate Results:
STRUCTURE
STREAM
STATE
SORTING
Final Result:
SORTING
STATE
STREAM
STRUCTURE
Terminate Operations
使用 toArray()
将流转为 Array,只需要调用toArray()方法,并传入数组的构造方法即可。
Example:
List<String> list = List.of("Apple", "Banana", "Orange");
String[] array = list.stream().toArray(String[]::new);
使用 collect()
collect 方法用于返回对流执行的中间操作的结果。
Syntax:
<R, A> R collect(Collector<? super T, A, R> collector)
使用示例:用预定义的 collector 来执行一些 reduction 任务:
// Accumulate names into a List
List<String> list = people.stream()
.map(Person::getName)
.collect(Collectors.toList());
// Accumulate names into a TreeSet
Set<String> set = people.stream()
.map(Person::getName)
.collect(Collectors.toCollection(TreeSet::new));
// Convert elements to strings and concatenate them, separated by commas
String joined = things.stream()
.map(Object::toString)
.collect(Collectors.joining(", "));
// Compute sum of salaries of employee
int total = employees.stream()
.collect(Collectors.summingInt(Employee::getSalary)));
// Group employees by department
Map<Department, List<Employee>> byDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment));
// Compute sum of salaries by department
Map<Department, Integer> totalByDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment,
Collectors.summingInt(Employee::getSalary)));
// Partition students into passing and failing
Map<Boolean, List<Student>> passingFailing = students.stream()
.collect(Collectors.partitioningBy(s -> s.getGrade() >= PASS_THRESHOLD));
Collectors
Collectors是Collector接口的实现类,它实现了许多实用的缩减操作(reduction operations,在函数式编程中称为「折叠(fold)」),比如把 stream 的元素按某种 collection类型(List, Set...)输出、根据不同的标准求和等。
缩减操作(reduction operations) - 也称为「折叠(fold)」,获取了一系列的输入元素,并通过重复应用一些操作将它们组合成单个汇总的结果。如:
Collectors.toList()- 将 stream 中的元素收集到一个列表中。List<String> words = Arrays.asList("Java", "8", "Stream", "API"); List<String> filteredWords = words.stream() .filter(word -> word.length() > 3) .collect(Collectors.toList()); System.out.println(filteredWords); // 输出: [Java, Stream, API]
Collectors.toSet()- 将 stream 中的元素收集到一个集合中,自动去除重复元素。Set<Integer> numbers = Stream.of(1, 2, 2, 3, 3, 3, 4) .collect(Collectors.toSet()); System.out.println(numbers); // 输出: [1, 2, 3, 4]
Collectors.groupingBy- 根据某个属性或函数,将 stream 中的元素分组到一个映射中。Map<Boolean, List<String>> groupedByEmpty = words.stream() .collect(Collectors.groupingBy(String::isEmpty)); System.out.println(groupedByEmpty); // 输出: {false=[Java, 8, Stream, API], true=[]}
Collectors.summingInt()- 对 stream 中的整数进行求和。int sum = IntStream.range(1, 6) .collect(Collectors.summingInt(i -> i)); System.out.println(sum); // 输出: 15
Collectors.joining()- 将 stream 中的字符串元素连接成一个字符串。String concatenated = words.stream() .collect(Collectors.joining("-")); System.out.println(concatenated); // 输出: Java-8-Stream-API
Collectors.averagingInt()- 计算流中整数的平均值。double average = IntStream.range(1, 6) .collect(Collectors.averagingInt(i -> i)); System.out.println(average); // 输出: 3.5
实际开发过程中遇到的一些特殊点,见下
使用 forEach()
forEach 方法用于循环访问流的每个元素。
Syntax:
void forEach(Consumer<? super T> action)
Consumer
使用 reduce()
reduce()操作把Stream的所有元素按照聚合函数聚合成一个结果。reduce() 方法的参数为 BinaryOperator 类型。
Syntax:
T reduce(T identity, BinaryOperator<T> accumulator)
/**
* identity - An initial value of type T.
* accumulator: A function that combines two values of type T.
*/
Optional<T> reduce(BinaryOperator<T> accumulator)
注意两种传参的返回值类型不同
以下是一些使用 reduce() 的例子:
-
Example 1: 获取最长的 string
List<String> words = Arrays.asList("Zhangsan", "Lisi", "Wangwu", "Zhaoliu", "Michael Jackson"); Optional<String> longestString = words.stream() .reduce((word1, word2) -> word1.length() > word2.length() ? word1 : word2); longestString.ifPresent(System.out::println); -
Example 2: 用指定分隔符拼接 string
String[] array = {"Michael", "Jackson", "Pop", "Singer"}; Optional<String> combinedString = Arrays.stream(array) .reduce((str1, str2) -> str1 + "-" + str2); combinedString.ifPresent(System.out::println); // 输出:Michael-Jackson-Pop-Singer -
Example 3: 求和
int sum = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9) .reduce(0, (acc, n) -> acc + n); // 初始化结果值为0,然后对每个元素依次调用函数 System.out.println(sum); // 45 -
Example 4: 求一定范围内的整数的积
int product = IntStream.range(2, 8) .reduce((num1, num2) -> num1 * num2) .orElse(-1); // Provides -1 if the stream is empty System.out.println("The product is : " + product);
使用 count()
返回该条流当前元素个数。
Syntax:
long count()
使用 findFirst()
返回流的第一个元素(如果存在)。
Syntax:
Optional<T> findFirst()
使用 allMatch()
检查流的 所有 元素是否与给定的predicate匹配。
Syntax:
boolean allMatch(Predicate<? super T> predicate)
使用 anyMatch()
检查流的 任何 元素是否与给定的 predicate 匹配。
Syntax:
boolean anyMatch(Predicate<? super T> predicate)
使用例
import java.util.*;
import java.util.stream.Collectors;
public class StreamTerminalOperationsExample {
public static void main(String[] args) {
// Sample data
List<String> names = Arrays.asList(
"Reflection", "Collection", "Stream",
"Structure", "Sorting", "State"
);
// forEach: Print each name
System.out.println("forEach:");
names.stream().forEach(System.out::println);
// collect: Collect names starting with 'S' into a list
List<String> sNames = names.stream()
.filter(name -> name.startsWith("S"))
.collect(Collectors.toList());
System.out.println("\ncollect (names starting with 'S'):");
sNames.forEach(System.out::println);
// reduce: Concatenate all names into a single string
String concatenatedNames = names.stream().reduce(
"",
(partialString, element) -> partialString + " " + element
);
System.out.println("\nreduce (concatenated names):");
System.out.println(concatenatedNames.trim());
// count: Count the number of names
long count = names.stream().count();
System.out.println("\ncount:");
System.out.println(count);
// findFirst: Find the first name
Optional<String> firstName = names.stream().findFirst();
System.out.println("\nfindFirst:");
firstName.ifPresent(System.out::println);
// allMatch: Check if all names start with 'S'
boolean allStartWithS = names.stream().allMatch(
name -> name.startsWith("S")
);
System.out.println("\nallMatch (all start with 'S'):");
System.out.println(allStartWithS);
// anyMatch: Check if any name starts with 'S'
boolean anyStartWithS = names.stream().anyMatch(
name -> name.startsWith("S")
);
System.out.println("\nanyMatch (any start with 'S'):");
System.out.println(anyStartWithS);
}
}
输出:
collect (names starting with 'S'):
Stream
Structure
reduce (concatenated names):
Reflection Collection Stream Structure
count:
4
findFirst:
Reflection
allMatch (all start with 'S'):
false
anyMatch (any start with 'S'):
true
开发过程中的特殊使用记录
输出为Map
为了将一个流转换为 Map 并输出,可以调用 .collect() 方法,并在里面传入 Collectors.toMap(),在 toMap() 方法中传入逻辑来指定 Map 的 key 和 value。
使用 Collectors.toMap() 时,我们需要提供两个函数:一个用于从流中的元素提取键(Key Mapper),另一个用于从流中的元素中提取值(Value Mapper)。此外,如果 Map 中的键可能会重复,我们还可以提供一个合并函数(Merge Function),用来定义当键冲突时如何处理。
示例1
举例如下:
public class Main {
public static void main(String[] args) {
Stream<String> stream = Stream.of("APPL:Apple", "MSFT:Microsoft");
Map<String, String> map = stream
.collect(Collectors.toMap(
// 把元素s映射为key:
s -> s.substring(0, s.indexOf(':')),
// 把元素s映射为value:
s -> s.substring(s.indexOf(':') + 1)));
System.out.println(map);
}
}
输出:
{MSFT=Microsoft, APPL=Apple}
示例2
import lombok.Data;
public class Main {
public static void main(String[] args) {
List<Person> people = Arrays.asList(
new Person("Alice", 23),
new Person("Bob", 30),
new Person("Charlie", 23)
);
Map<String, Person> peopleMap = people.stream().collect(Collectors.toMap(
Person::getName, // Key Mapper: 使用Person的name作为键
Function.identity(), // Value Mapper: 使用Person对象本身作为值
(existing, replacement) -> existing // Merge Function: 如果键冲突,保留现有的
));
System.out.println(peopleMap);
}
}
@Data
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
输出:
{Bob=Person(name=Bob, age=30), Alice=Person(name=Alice, age=23), Charlie=Person(name=Charlie, age=23)}
分组输出
分组输出使用Collectors.groupingBy()。groupingBy 方法的第一个参数是一个分类函数,它定义了分组的依据;第二个参数是一个下游收集器,它定义了如何处理每个组中的元素。如果不提供下游收集器,那么默认情况下,每个组将被收集到一个列表中。
示例1
public class Main {
public static void main(String[] args) {
List<String> list = Arrays.asList("Apple", "Banana", "Blackberry", "Coconut", "Avocado", "Cherry", "Apricots");
Map<String, List<String>> groups = list.stream()
.collect(Collectors.groupingBy(s -> s.substring(0, 1), Collectors.toList()));
System.out.println(groups);
}
}
在上面的例子中,向 groupingBy 方法中提供的分组的 key 是s -> s.substring(0, 1),表示只要首字母相同的String分到一组,第二个是分组的value,这里直接使用Collectors.toList(),表示输出为List,上述代码运行结果如下:
{A=[Apple, Avocado, Apricots], B=[Banana, Blackberry], C=[Coconut, Cherry]}
示例2
package org.example;
import lombok.Data;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class GroupingByExample {
public static void main(String[] args) {
List<Student> students = Arrays.asList(
new Student("John", "Math", "Class1"),
new Student("Alice", "Math", "Class2"),
new Student("Bob", "Science", "Class1"),
new Student("Charlie", "Math", "Class1")
);
Map<Map<String, String>, List<Student>> groupedStudents = students.stream()
.collect(Collectors.groupingBy(
item -> Collections.unmodifiableMap(new HashMap<String, String>() {{
put("subject", item.getSubject());
put("class", item.getClassroom());
}})
));
groupedStudents.forEach((key, value) -> {
System.out.println("Key: " + key + ", Value: " + value);
});
}
}
@Data
class Student {
private String name;
private String subject;
private String classroom;
Student(String name, String subject, String classroom) {
this.name = name;
this.subject = subject;
this.classroom = classroom;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + "'" +
", subject='" + subject + "'" +
", classroom='" + classroom + "'" +
"}";
}
}
输出:
Key: {subject=Science, class=Class1}, Value: [Student{name='Bob', subject='Science', classroom='Class1'}]
Key: {subject=Math, class=Class1}, Value: [Student{name='John', subject='Math', classroom='Class1'}, Student{name='Charlie', subject='Math', classroom='Class1'}]
Key: {subject=Math, class=Class2}, Value: [Student{name='Alice', subject='Math', classroom='Class2'}]
在这个例子中,我们根据 subject和 classroom来分组学生。每个分组的键是一个包含这两个属性的 Map。
注意点:
- 不可变Map:使用
Collections.unmodifiableMap来创建一个不可变的Map。这是重要的,因为groupingBy要求分组键的hashCode和equals方法必须被正确实现,而不可变对象通常更容易确保这一点。- 性能:创建一个匿名内部类来构建
Map可能会影响性能,因为每次调用 lambda 表达式时都会创建一个新的Map实例。如果性能是一个问题,可以考虑重用相同的Map实例或使用其他方式来生成键。- 线程安全:由于
groupingBy方法可能会在并行流上使用,确保你的分组键是线程安全的。使用不可变对象是一个好方法。- hashCode和equals:确保你的分组键正确实现了
hashCode和equals方法。对于Map作为键,Java 的HashMap已经为你做了这些,但如果你使用自定义对象,你需要自己实现这些方法。- 分组键的冲突:如果两个不同的
Map实例根据hashCode和equals方法被认为是相等的,它们将被分到同一组。确保你的键设计能够正确地反映你想要的分组逻辑。- 空值处理:在创建
Map时,确保没有null值,因为null值可能会影响hashCode和equals的行为。
其他操作
去重
直接用.distint()方法即可。
List.of("A", "B", "A", "C", "B", "D")
.stream()
.distinct()
.collect(Collectors.toList()); // [A, B, C, D]
截取
用limit()和skip()配合。skip()用于跳过当前Stream的前N个元素,limit()用于截取当前Stream最多前N个元素。
List.of("A", "B", "C", "D", "E", "F")
.stream()
.skip(2) // 跳过A, B
.limit(3) // 截取C, D, E
.collect(Collectors.toList()); // [C, D, E]
合并
使用.concat()方法即可。
Stream<String> s1 = List.of("A", "B", "C").stream();
Stream<String> s2 = List.of("D", "E").stream();
// 合并
Stream<String> s = Stream.concat(s1, s2);
System.out.println(s.collect(Collectors.toList())); // [A, B, C, D, E]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号