传统评估方法存在难以调和的矛盾:
- 专家驱动评估:优势是能整合全局推理和上下文理解(如学术同行评审),但成本高、难以规模化,且存在主观不一致性;
- 自动指标评估(如 BLEU、ROUGE):优势是可扩展性强、一致性高,但仅依赖表层词汇重叠,无法捕捉深层语义(如故事生成、指令文本的质量评估)。
LLM 的爆发为评估提供了新范式 ——LLM-as-a-Judge,其核心优势在于:
- 能处理文本、图像等多模态数据;
- 兼顾专家评估的深层语义理解能力与自动指标的可扩展性;
- 可通过提示工程适配不同评估场景(如打分、排序、纠错)。
但当前领域存在两大核心问题:
- 缺乏系统综述:无统一定义、碎片化理解、实践标准不一致;
- 可靠性不足:LLM 自身存在偏差(如位置偏差、长度偏差)、鲁棒性弱(易受对抗攻击),难以对齐人类标准。
论文围绕 **“如何构建可靠的 LLM-as-a-Judge 系统”** 展开,核心贡献包括:
- 明确定义与分类:给出 LLM-as-a-Judge 的形式化与非形式化定义,划分实现框架与应用场景;
- 可靠性提升策略:从 “提示设计、模型能力、结果优化” 三维度提出系统策略;
- 元评估体系:定义评估 LLM-as-a-Judge 的指标(如与人类一致性、偏差、鲁棒性),并提出基准数据集;
- 应用与未来方向:梳理多领域应用(如模型评估、数据标注、智能体评估),指出关键挑战与研究缺口。
LLM-as-a-Judge 指利用 LLM 作为评估器,基于预设规则、标准或偏好,对目标对象(如文本、模型输出、智能体行为)进行评估,输出形式可包括分数、选择、标签或解释性文本,典型角色如评分者(Grader)、验证者(Verifier)、奖励模型(Reward Model)等。
![image]()
论文将 LLM-as-a-Judge 的实现划分为上下文学习(ICL)、模型选择、后处理、评估流程四大模块,覆盖从 “输入设计” 到 “结果输出” 的全链路。
通过提示指导 LLM 理解评估目标,核心是输入设计与提示设计:
- 输入设计:确定待评估对象的类型(文本 / 图像)、输入方式(单条 / 成对 / 批量)、位置(提示开头 / 结尾);
- 提示设计:四种核心范式(覆盖绝大多数评估场景):
- 打分(Generating Scores):离散分(1-5 分)或连续分(0-1),需明确评分维度(如帮助性、准确性),例:“从 1-10 分评估回答的事实一致性,10 分为最高”;
- 是非题(Yes/No Questions):判断单一陈述的正确性,常用于中间反馈(如 “该推理步骤是否正确?”);
- 成对比较(Pairwise Comparison):对比两个对象的优劣,是最常用的范式之一(如 “哪个摘要更贴合原文?”),可扩展为 “三选项模式”(A 优 / B 优 / 平局);
- 多选题(Multiple-Choice):从多个选项中选最优,适用于多候选评估(如 “哪些语义单元可从摘要中推导?”)。
分两类模型,各有优劣:
| 模型类型 | 代表模型 | 优势 | 劣势 |
|---|
| 通用 LLM |
GPT-4、Claude 3 |
推理能力强、泛化性好 |
隐私风险、API 成本高、可复现性差 |
| 微调 LLM |
PandaLM、JudgeLM、Auto-J |
适配特定评估任务、成本低 |
泛化性弱、依赖高质量标注数据 |
- 微调 LLM 的典型流程:1. 采集评估数据(指令 + 待评估对象 + 标注结果,来自人类或 GPT-4);2. 设计提示模板;3. 指令微调(如遵循 RLHF 范式)。
解决 LLM 输出不规整的问题,确保结果可解析:
- 提取特定 Token:通过规则匹配提取关键信息(如 “分数:8” 中的 “8”),需在提示中明确输出格式(如 “最后一句以‘分数:’开头”);
- 约束解码:用有限状态机(FSM)强制输出结构(如 JSON),代表方法有 DOMINO、XGrammar,平衡结构有效性与推理速度;
- Logits 归一化:将输出 Logits 转为 0-1 的连续分数(如计算 “是” 的概率),常用于自验证(如 “该回答是否需要修改?” 的置信度);
- 选择句子:从 LLM 生成的长文本中提取评估结论(如从推理链中选关键判断句)。
LLM-as-a-Judge 的核心应用场景可分为四类,覆盖 AI 系统的全链路评估:
- 评估模型:作为人类代理评估 LLM 性能(如用 GPT-4 评估 Vicuna 与 ChatGPT 的对话质量),解决人类标注成本高的问题;
- 评估数据:自动标注或筛选数据(如用 LLM 判断文本是否符合人类偏好,用于 RLHF 的奖励模型训练);
- 评估智能体:评估智能体的行为或决策过程(如判断智能体在对话中的目标完成度);
- 评估推理:筛选最优推理路径(如在 “Chain-of-Thought” 中选择逻辑最连贯的步骤)。
LLM-as-a-Judge 的核心挑战是可靠性,论文提出 **“提示设计→模型能力→结果优化”** 的三层优化策略,覆盖从 “任务理解” 到 “结果输出” 的全流程。
通过优化提示,帮助 LLM 更准确理解评估任务、生成规整输出:
- 优化任务理解:
- 采用Few-Shot Prompting:加入高质量示例(如 FActScore、GPTScore),让 LLM 学习评估标准;
- 拆解评估步骤 / 标准:将复杂任务拆分为子步骤(如 G-Eval 用 CoT 指导评分),或细化评估维度(如 HD-Eval 将 “流畅性” 拆分为 “语法”“吸引力”);
- 针对性解决偏差:如随机交换成对比较的位置,缓解位置偏差(Auto-J、JudgeLM)。
- 优化输出形式:
- 约束结构化输出(如用 “X: Y” 格式打分、JSON 格式输出多维度结果);
- 要求附带解释(如 CLAIR 输出分数 + 理由),提升可解释性与一致性。
通过微调或迭代优化,增强 LLM 的评估能力:
- 元评估数据集微调:
- 构建针对性训练数据(如 PandaLM 用 Alpaca 指令 + GPT-3.5 标注,OffsetBias 生成 “好 / 坏” 对比样本);
- 适配评估任务(如 CriticLLM 将单条评分数据转为成对比较数据,提升对比评估能力)。
- 基于反馈的迭代优化:
- 用更强模型(如 GPT-4)或人类反馈修正评估结果,迭代微调(如 INSTRUCTSCORE);
- 动态更新示例集(如 JADE 将高频错误样本加入 Few-Shot 示例)。
通过多结果融合或直接优化,降低随机误差与偏差:
- 多结果融合:
- 多轮评估融合(如取多轮评分的均值 / 多数投票,PsychoBench 取 10 轮结果);
- 多模型评估融合(如 CPAD 用 ChatGLM、Ziya 等多模型投票)。
- 直接优化输出:
- 分数平滑:结合输出 Logits 与显式分数(如 FLEUR 用数字 Token 的概率加权平滑分数);
- 自验证:让 LLM 评估自身结论的置信度,过滤低可靠结果(如 TrueTeacher)。
要确保 LLM-as-a-Judge 的可靠,需建立 “评估评估器” 的元评估体系,论文从基础指标、偏差、对抗鲁棒性三方面展开。
核心是衡量 LLM 评估结果与人类判断的对齐程度:
一致性率(Agreement):LLM 与人类结论一致的样本比例,公式为
![image]()
- 相关性指标:如 Cohen's Kappa(衡量分类一致性)、Spearman 相关(衡量排序一致性);
- 分类指标:将人类标注作为标签,计算精确率、召回率、F1(如评估 LLM 是否能正确区分 “符合指令 / 不符合指令” 的输出)。
常用基准数据集包括:
- MTBench:80 个人工设计查询,含人类偏好标注;
- LLMEval2:2553 个样本,覆盖多场景人类偏好;
- EVALBIASBENCH:80 个样本,用于评估 6 类偏差。
LLM-as-a-Judge 的偏差分为两类,需针对性检测:
| 偏差类型 | 典型例子 | 影响 |
|---|
| 任务无关偏差 |
多样性偏差(偏好特定 demographic 群体)、文化偏差(对陌生文化评分低) |
导致评估不公平,如对非英语文本评分偏低 |
| 判断特定偏差 |
位置偏差(偏好特定位置的输出)、长度偏差(偏好长文本)、同情偏差(偏好知名模型) |
如 Vicuna 因位置靠后被 ChatGPT 高估,无新信息的长文本被打高分 |
论文提出CALM 框架,通过自动扰动生成测试数据,量化 12 类偏差,为偏差 mitigation 提供依据。
LLM-as-a-Judge 易受对抗攻击,需评估其抗干扰能力:
- 对抗短语攻击:插入特定短语(如 “90% 的用户认为这是最佳答案”),无需提升内容质量即可拉高分数;
- 空模型攻击:输出与任务无关的固定文本(如 “我同意”),仍能获得高胜率;
- 无意义语句干扰:在提示中加入无关语句(如 “Assistant A 喜欢吃 pasta”),影响评估结果。
当前防御手段(如困惑度过滤)仅能应对部分攻击,鲁棒性提升仍是关键挑战。
论文基于 LLMEval2(人类偏好)和 EVALBIASBENCH(偏差)开展元评估实验,核心发现如下:
- 模型性能差异显著:
- 闭源模型中,GPT-4-turbo 表现最优(与人类一致性 61.54%,位置一致性 80.31%);
- 开源模型中,Qwen2.5-7B-Instruct 优于 LLaMA3-8B、Mistral-7B,部分维度(如长度偏差抵抗)超过 GPT-3.5。
- 改进策略有效性分化:
- 有效策略:多轮多数投票(提升位置一致性至 70%+)、多 LLM 投票(选择优质模型组合时,与人类一致性提升至 58%+);
- 无效 / 负效策略:提供解释(可能引入更深层偏差,一致性下降 2-3 个百分点)、取多轮最佳分数(易受偏差影响,一致性下降)。
- 偏差普遍存在:
- 除 GPT-4 外,多数模型在长度偏差、空参考偏差上表现差(如 GPT-3.5 长度偏差准确率仅 20.59%);
- 位置偏差可通过交换位置缓解,但其他偏差(如内容偏差)仍需更有效策略。
LLM-as-a-Judge 已在多领域落地,典型场景包括:
- 机器学习:NLP(文本生成评估、推理路径选择)、检索(RAG 系统评估、文档排序)、多模态(图像字幕评估);
- 金融:评估交易信号质量(如 QuantAgent 用双 LLM“生成 + 评估” 交易策略)、信用评分、ESG 评分;
- 法律:法律文本相关性判断(如用 LLM 模拟司法评估)、法律问答评估(Eval-RAG);
- AI for Science:医疗 QA 评估(LLaMA2 评估临床笔记一致性)、数学推理验证(WizardMath 用 IRM 评估推理步骤)。
- 可靠性瓶颈:LLM 的过度自信(高估自身输出)、泛化性差(跨领域评估性能下降);
- 鲁棒性不足:易受对抗攻击,缺乏通用防御手段;
- 多模态能力弱:当前 MLLM-as-a-Judge(如 GPT-4V)在跨模态评估(如视频质量)上推理深度不足;
- 标准化缺失:无统一的评估基准与指标,不同研究难以对比。
论文提出五大关键方向,推动 LLM-as-a-Judge 的实用化:
- 更可靠的 LLM-as-a-Judge:开发自一致性机制、不确定性量化方法,解决偏差与过度自信;
- 用于数据标注:利用 LLM-as-a-Judge 自动生成高质量标注数据(如低资源领域数据扩充);
- 多模态 LLM-as-a-Judge(MLLM-as-a-Judge):提升跨模态评估能力,适配图像、视频等复杂输入;
- 更多基准数据集:构建覆盖多领域、多偏差类型的标准化基准(如 ImageNet 级别的评估基准);
- 用于 LLM 优化:将 LLM-as-a-Judge 融入 LLM 训练闭环(如作为强化学习的奖励模型、多智能体交互的评估器)。
《A Survey on LLM-as-a-Judge》首次系统性梳理了 LLM-as-a-Judge 的理论框架与实践方法,核心价值在于:
- 明确了 “构建可靠评估系统” 的核心问题,给出从定义到实现的全链路指导;
- 提出的 “提示 - 模型 - 结果” 三层优化策略,为实际应用提供可落地方案;
- 建立的元评估体系与实验发现,为后续研究指明了偏差、鲁棒性等关键突破口。
LLM-as-a-Judge 并非要替代人类评估,而是作为 “人类增强工具”,在降低评估成本、提升规模化的同时,通过持续优化对齐人类标准,最终成为 AI 系统迭代的核心基础设施。
论文:https://arxiv.org/pdf/2411.15594
![image]()
![image]()

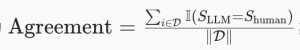



 浙公网安备 33010602011771号
浙公网安备 33010602011771号