

Self-Attention
故事引入
想象你在图书馆找一本编程书籍:
1. 你的需求(Query)是"Python数据科学"
2. 书架标签(Key)显示"机器学习"、"Web开发"等
3. 通过比对需求与标签,你找到最相关(Value)的书籍
这个找书的过程就是注意力机制的生动体现!
核心概念解释
注意力权重:就像找书时要判断哪些书架标签与需求最相关,注意力权重决定了各个元素的重要程度。例如在句子"I like eating apple"中,"eating"与"apple"的关联权重更高。
Query-Key-Value机制
Query:当前需要处理的元素(如当前要翻译的词语)
Key:序列中所有元素的标识
Value:元素的实际表示
多头注意力:就像同时派出多个图书管理员从不同角度找书,每个"头"关注不同的特征维度。例如一个头关注语法结构,另一个头关注语义关系。
自注意力机制的概念
自注意力机制(Self-Attention),也称为内部注意力机制,是一种将单个序列的不同位置关联起来以计算同一序列的表示的注意力机制。这种机制允许模型在处理序列数据时,动态地调整对每个元素的关注程度,从而捕捉序列内部的复杂依赖关系。
自注意力机制的核心在于,它不依赖于外部信息,而是在序列内部元素之间进行信息的交互和整合。这意味着,对于序列中的每个元素,自注意力机制会计算该元素与序列中所有其他元素的相关性,生成一个加权的表示,其中权重反映了元素间的相互关系。

自注意力机制的计算过程可以被分解为几个关键步骤。
(1) 输入序列被映射到查询(Query)、键(Key)和值(Value)三个向量。
(2) 通过计算查询向量与所有键向量之间的点积来获得注意力得分。这些得分随后被缩放并经过Softmax函数进行归一化,以获得每个元素的注意力权重。
(3) 这些权重被用来对值向量进行加权求和,生成最终的输出序列。
Q、K、V的生成
在自注意力(Self-Attention)机制中,查询(Query,简称Q)、键(Key,简称K)和值(Value,简称V)是三个核心的概念,它们共同参与计算以生成序列的加权表示。
查询(Query,Q)
查询向量Q代表了当前元素在序列中的作用,它用于“询问”序列中的其他元素以获取相关信息。在自注意力机制中,每个元素都会生成一个对应的查询向量,该向量用于与序列中的所有键向量进行比较,以确定每个元素的重要性或相关性。
键(Key,K)
键向量K包含了序列中每个元素的特征信息,这些信息将用于与查询向量进行匹配。键向量的主要作用是提供一种机制,使得模型能够识别和比较序列中不同元素之间的关系。在自注意力中,每个元素都会有一个对应的键向量,它与查询向量一起决定了注意力分数。
值(Value,V)
值向量V包含了序列中每个元素的实际信息或特征,这些信息将根据注意力分数被加权求和,以生成最终的输出。值向量代表了序列中每个元素的具体内容,它们是模型最终用于生成输出的原始数据。
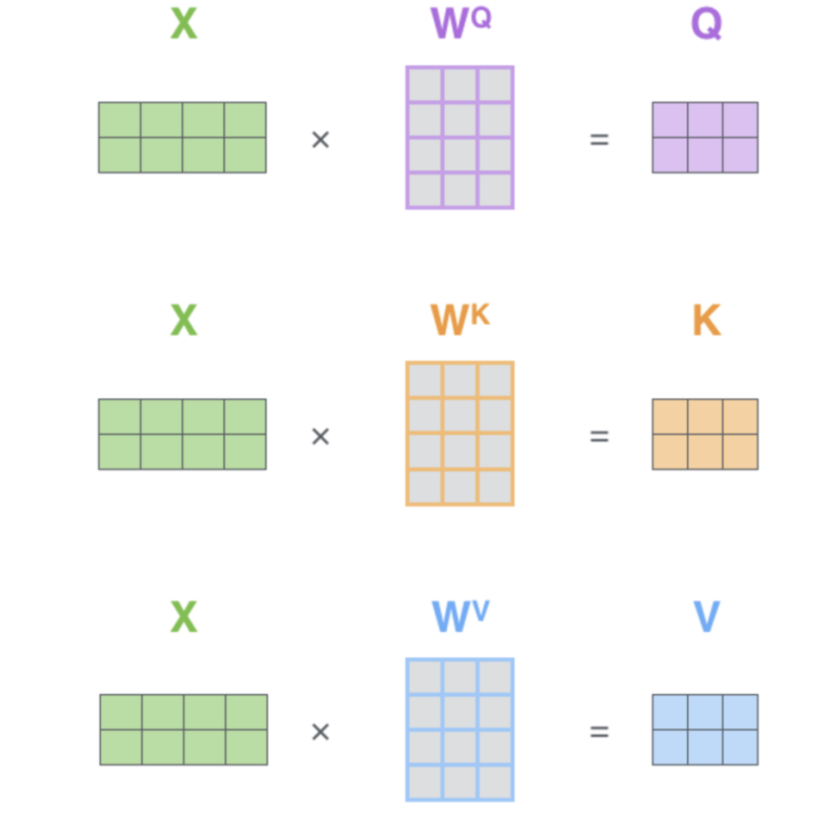
在自注意力机制中,输入序列的每个元素首先被映射到三个向量:查询(Q)、键(K)和值(V)。这一过程通常通过与三个权重矩阵的线性变换实现。具体来说,输入序列X与权重矩阵W^Q、W^K和W^V相乘,得到Q、K和V:
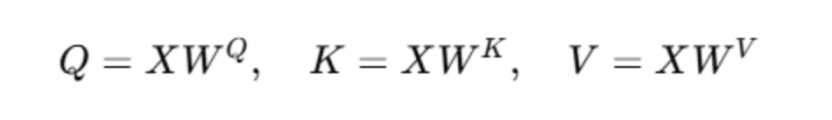
其中,X是输入序列,W^Q、W^K和W^V是可学习的权重矩阵。这些矩阵的维度通常是(序列长度,特征维度)乘以(特征维度,Q/K/V维度)。Q、K和V的维度是(序列长度,Q/K/V维度)。
这三个变换可以看作是对原始输入的一种重新编码,目的是从不同角度提取信息,以便后续计算注意力分数时能够更有效地捕捉到元素间的相关性。
缩放点积计算注意力得分
自注意力机制中,查询向量Q与所有键向量K之间的点积被用来计算注意力得分。为了避免点积结果过大导致梯度问题,引入了一个缩放因子1/√dk,其中dk是键向量的维度。缩放后的注意力得分计算如下:

这个操作生成了一个注意力得分矩阵,其中每个元素代表对应元素对之间的相似度。
Softmax 归一化
为了将注意力得分转换为权重,应用Softmax函数进行归一化。Softmax确保所有输出权重的和为1,从而使得模型可以学习到每个元素对的重要性:

Softmax函数定义为:
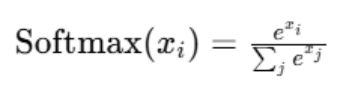

其中,xi是注意力得分矩阵中的元素。这意味着对于每个位置 i,在计算完 softmax 后,我们会获得该位置与其他所有位置的相关性的“概率”。
加权求和生成输出
最后,归一化的注意力权重被用来对值向量V进行加权求和,生成最终的输出序列。输出序列的每个元素是所有值向量的一个加权和,权重由对应的注意力权重决定:

这一步骤有效地整合了序列内部的信息,使得每个元素的输出表示包含了整个序列的上下文信息。
自注意力机制在现代深度学习模型中的重要性
Ø 自注意力机制的重要性在于其灵活性和强大表达能力,特别是在处理长文本或其他类型的序列数据方面表现尤为突出。以下是几个关键点:
Ø Transformer架构的核心:自从Transformer被提出以来,它已经在多个NLP基准测试中取得了顶尖的成绩,并成为了当前最先进的预训练语言模型的基础,如BERT、GPT系列等。这些模型都依赖于多层堆叠的自注意力机制来实现卓越的效果。
Ø 并行化优势:与传统RNN不同的是,自注意力机制允许对整个序列进行并行处理,而不是按顺序逐个处理时间步。这一特性大大加快了训练速度,尤其是在大规模语料库上训练时显得尤为重要。
Ø 捕捉全局依赖性:通过让每个元素都能“看到”整个序列中的所有其他元素,自注意力机制能够在单一层内建立起非常广泛且深入的上下文联系。这对于理解复杂句子结构或文档级别的语义关系至关重要。
Ø 跨领域应用:除了NLP之外,自注意力机制也被成功应用于计算机视觉、语音识别等多个领域。例如,在图像分类任务中,它可以用来捕捉图片内的空间依赖关系;而在视频分析中,则有助于理解时间维度上的动态变化。

本文来自博客园,作者:limingqi,转载请注明原文链接:https://www.cnblogs.com/limingqi/p/18993879

 浙公网安备 33010602011771号
浙公网安备 33010602011771号