

Tokenization
分词(Tokenization)是自然语言处理(NLP)中的基础预处理步骤,它架起了原始文本与机器学习模型之间的桥梁。分词过程涉及将文本分解为称为“token”的更小单元,随后这些token被转换为数字ID。这些ID会作为LLM的输入,并通过嵌入层映射为捕捉语义含义的向量表示。
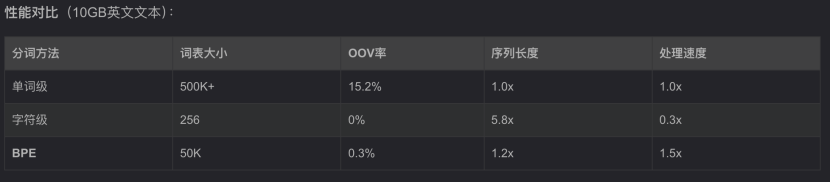
分词方法的选择对LLM的性能和效率起着关键作用。本文将深入探讨三种流行的分词算法:BPE、WordPiece和SentencePiece。每种算法采用不同的方法将文本分割为token,分析其机制、优势与局限性。
1、什么是分词?
分词是将非结构化文本转换为机器学习模型可理解的结构化格式的过程。其核心在于将一段文本(无论是句子、段落还是文档)分割为更小的可管理单元,即“token”。根据所采用的分词策略,这些token可以是单词、子词,甚至是单个字符。分词后,每个token会从预定义词汇表中分配一个数字ID,从而将文本转换为如下所示的数字序列:
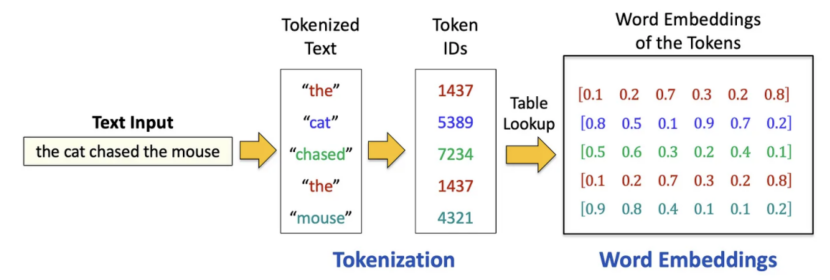
接下来,通过查表从预训练的嵌入矩阵中为每个token ID检索词嵌入(向量表示)。这些嵌入捕捉了语义含义,使模型能够理解单词之间的关系,例如“cat”和“kitten”的相似性。这一过程是NLP任务的基础。
2、分词的类型
根据token的粒度,分词策略主要有三种类型:字符级、词级和子词级分词。每种方法各有优劣,具体选择取决于NLP任务的特定需求。
2.1 字符级分词
在字符级标分词中,文本被分割为单个字符。例如,单词“hello”会被标记为[“h”, “e”, “l”, “l”, “o”]。
优势:
(1)有效处理罕见词或词汇表外(OOV)词,因为所有可能的字符都包含在词汇表中。
(2)适用于形态复杂或词边界模糊的语言(如中文、日文)。
(3)与词级分词相比,词汇表规模更小。
劣势:
(1)导致序列变长,增加计算复杂度。
(2)丢失词级语义,使模型更难捕捉词间关系。
2.2 词级分词
在词级分词中,文本被分割为单个单词。例如,句子“I love coding”会被标记为[“I”, “love”, “coding”]。
优势:
(1)保留词级语义,便于模型理解词间关系。
(2)与字符级分词相比,序列更短,减少计算开销。
劣势:
(1)难以处理罕见词或未见过的词(OOV问题)。
(2)词汇表规模可能极大,尤其在形态丰富的语言或处理领域特定术语时。
2.3 子词级分词
子词级分词将单词分割为更小的单元,如前缀、后缀或其他有意义的子词成分。例如,单词“unbelievable”可能被标记为[“un”, “believ”, “able”]。子词级分词的常用算法包括字节对编码(BPE)、WordPiece(用于BERT)和SentencePiece。
优势:
(1)平衡了字符级和词级分词的优缺点,既能轻松处理OOV词,又能保持较短序列
(2)捕捉形态信息,适用于词结构复杂的语言。
(3)与词级分词相比,减少词汇表规模,同时保留部分语义。
劣势:
(1)需要仔细调整子词分割算法,避免过度分割或分割不足。
(2)单词分割方式可能仍存在歧义,尤其对于形态边界不明确的语言。
3、字节对编码(BPE)
3.1 为什么用BPE
Byte Pair Encoding( BPE )是一种广泛应用于自然语言处理( NLP )的分词算法,尤其在大规模预训练模型( 如GPT、BERT )中表现优异。它的核心思想是通过合并高频字符对来构建子词(subword)单元,从而平衡词汇量大小与语义表达能力。
BPE 的背景与动机
起源:BPE最初是一种数据压缩算法( 1994年提出 ),通过替换高频字节对来减少数据体积。
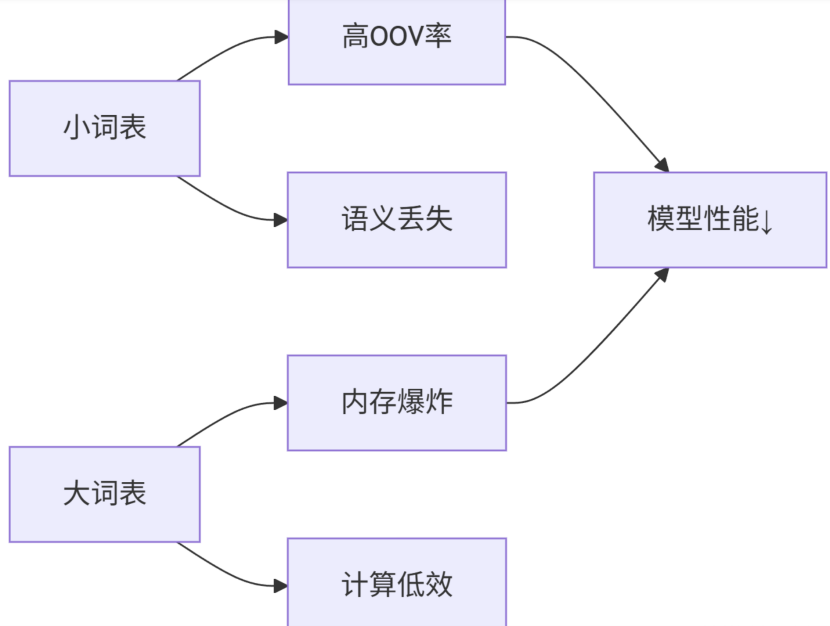
NLP中的应用:2015年由Sennrich等人引入NLP领域,用于解决传统分词方法的局限性:
o 未登录词问题( OOV ):传统方法( 如空格分词 )无法处理未见过的词汇。
o 稀有词问题:低频词在训练数据中稀疏,模型难以学习其语义。
核心目标:将单词拆分为更小的、可重用的子词单元( 如前缀、后缀、词根 ),提升模型泛化能力。
BPE创新本质

3.2 BPE核心原理
BPE 的核心步骤
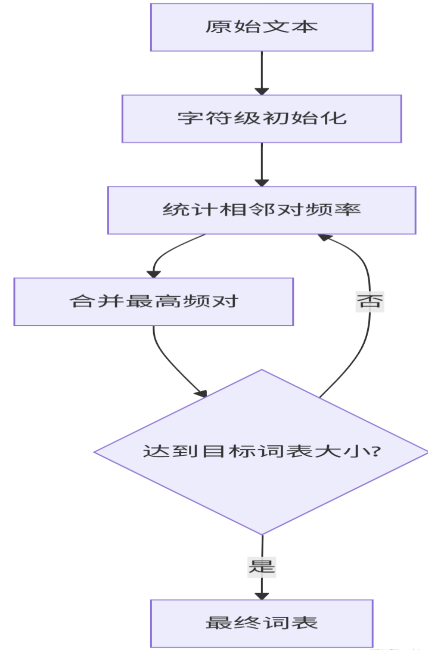
BPE分词分为两个阶段:训练阶段( 构建子词表 )和推理阶段( 用子词表分词 )。
阶段1:训练阶段( 构建子词表 )
初始化:
· 将所有单词拆分为字符( 或字节 )级别,并统计词频。
· 例如:单词"low"拆分为['l', 'o', 'w'],"lower"拆分为['l', 'o', 'w', 'e', 'r']。
迭代合并高频字符对:
统计所有相邻字符对的出现频率,选择频率最高的字符对进行合并。
· 将合并后的新符号加入词汇表,并重复此过程,直到达到预设的词汇表大小( 如50k )或迭代次数。
示例:
假设初始词汇表为字符集:{l, o, w, e, r, s, t}
- 合并最高频的字符对 ('l', 'o') → 新符号 lo
- 合并下一高频对 ('lo', 'w') → 新符号 low
- 最终子词可能包括:low, er, s( 允许"lower"被拆分为"low" + "er" )。
阶段2:推理阶段( 分词 )
将新单词拆分为字符序列,按子词表从最长到最短的优先级进行匹配。
优先合并已存在的子词,无法匹配时退回更小的单元。
示例:
子词表:{low, er, est, s}
- "lowest" → low + est
- "lowering" → low + er + ing( 若ing不在表中,继续拆分为i + n + g )。
3.3 BPE的优缺点
优点:
平衡词汇量与语义:高频词保留完整( 如"the" ),低频词拆分为子词( 如"transformer" → trans + form + er )。
解决未登录词问题:即使单词未在训练数据中出现,也能通过子词组合表示。
跨语言适用性:适用于形态丰富的语言( 如德语、土耳其语 ),无需语言特定规则。
缺点:
对训练数据敏感:合并规则依赖训练语料库的词频分布,可能引入领域偏差。
可能引入歧义:例如:"player"可能被拆分为play + er( 演员 )或pla + yer( 无意义子词 )。
python代码基础实现:
from collections import Counter, defaultdict
import re
def train_bpe(text, vocab_size=1000):
# 1. 预处理:添加单词边界
text = re.sub(r'\s+', ' ', text).strip()
words = text.split()
tokens = [list(word) + ['</w>'] for word in words]
# 2. 初始化词表
vocab = Counter()
for token_list in tokens:
for char in token_list:
vocab[''.join(char)] += 1
# 3. 合并迭代
merges = {}
while len(vocab) < vocab_size:
# 统计连续对频率
pairs = defaultdict(int)
for token_list in tokens:
for i in range(len(token_list)-1):
pair = (token_list[i], token_list[i+1])
pairs[pair] += 1
if not pairs:
break
# 选择最高频对
best_pair = max(pairs, key=pairs.get)
# 执行合并
new_token = best_pair[0] + best_pair[1]
merges[best_pair] = new_token
# 更新词元序列
new_tokens = []
for token_list in tokens:
i = 0
new_list = []
while i < len(token_list):
if i < len(token_list)-1 and (token_list[i], token_list[i+1]) == best_pair:
new_list.append(new_token)
i += 2
else:
new_list.append(token_list[i])
i += 1
new_tokens.append(new_list)
tokens = new_tokens
# 更新词表
vocab = Counter()
for token_list in tokens:
for token in token_list:
vocab[token] += 1
# 构建最终词表
final_vocab = set(vocab.keys())
return final_vocab, merges
# 在小文本上训练
sample_text = "low lower lowest new newer newest wide wider widest"
vocab, merges = train_bpe(sample_text, vocab_size=20)
print("BPE词表:", sorted(vocab))
print("合并规则:", merges)
输出:
BPE词表: ['e', 'es', 'est', 'l', 'lo', 'low', 'n', 'ne', 'new', 'r', 's', 'st', 't', 'w', 'wi', 'wid', 'wide']
合并规则: {('l', 'o'): 'lo', ('lo', 'w'): 'low', ('e', 's'): 'es', ('es', 't'): 'est', ('n', 'e'): 'ne', ('ne', 'w'): 'new', ('w', 'i'): 'wi', ('i', 'd'): 'id', ('id', 'e'): 'ide'}
工具包代码实现:
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
# 初始化BPE模型
tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
# 训练子词表
files = ["text_corpus.txt"] # 输入语料文件
tokenizer.train(files, trainer)
# 分词示例
output = tokenizer.encode("Hello, how are you?")
print(output.tokens) # 输出:["Hello", ",", "how", "are", "you", "?"]
4、WordPiece
WordPiece是一种类似于BPE的子词分词算法,但其核心区别在于选择合并token的方式:WordPiece不是合并最频繁的对,而是合并能最大化训练数据似然的对,这使其在BERT等模型中尤为有效。
“最大化训练数据似然” 可以简单理解为:合并两个字符 / 子词后,让模型预测整个句子的概率变得更高。WordPiece 的核心就是每次选择合并时,都要计算 “合并后是否让整个训练数据的预测更准确”,而不是单纯选出现最多的组合。
4.1 WordPiece的工作原理
Ø 初始词汇表:与BPE类似,从单个字符的词汇表开始。
Ø 似然最大化:WordPiece选择合并后能最大化训练数据似然的token对,通过计算对的概率除以单个token概率的乘积来确定,即选择使P(tok1,tok2)/(P(tok1)×P(tok2))最大化的对(tok1, tok2)。
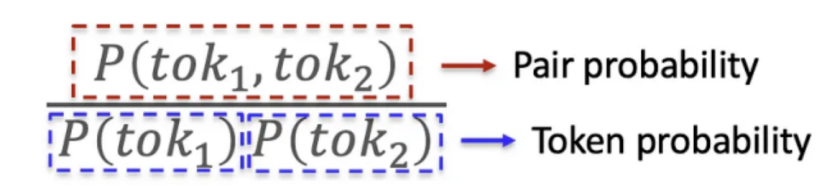
Ø 迭代合并:合并选定的对,重复该过程直到达到所需的词汇表大小。
Ø 最终标记化:使用学习到的子词单元对文本进行分词。
优势与局限性
Ø 优势:有效捕捉有意义的子词单元,广泛应用于BERT等模型。
Ø 局限性:与BPE类似,需要预分词,对某些语言可能存在问题。
5、SentencePiece
BPE和WordPiece都需要预分词作为初始步骤,即在合并前将文本分割为子词单元,但这对中文和日文等词边界不明确的语言构成挑战,使预分词困难或不可行。SentencePiece是专门为克服这些限制而设计的标记化算法。与BPE和WordPiece不同,它将输入文本视为原始字符流(包括空格),无需预分词。这种方法使SentencePiece能够无缝处理词边界模糊的语言,成为多语言和非空格分隔语言的通用选择。
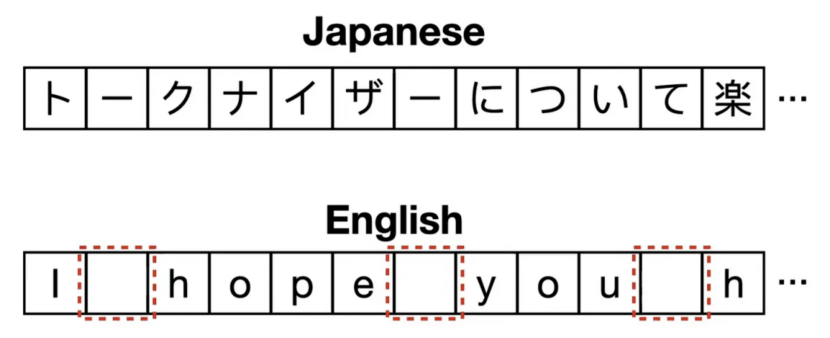
5.1 SentencePiece的工作原理
Ø 作为字符流的输入:SentencePiece不先将文本分割为单词,而是将整个输入文本视为包括空格在内的连续字符序列。
Ø 合并算法:采用与BPE类似的合并算法或一元分词器:
类BPE合并:类似BPE,迭代合并最频繁的字符对。
一元分词器:初始化时使用大量token,逐步修剪每个token以获得更小的词汇表,直到达到所需大小。
Ø 空格处理:SentencePiece使用下划线作为空格的占位符。
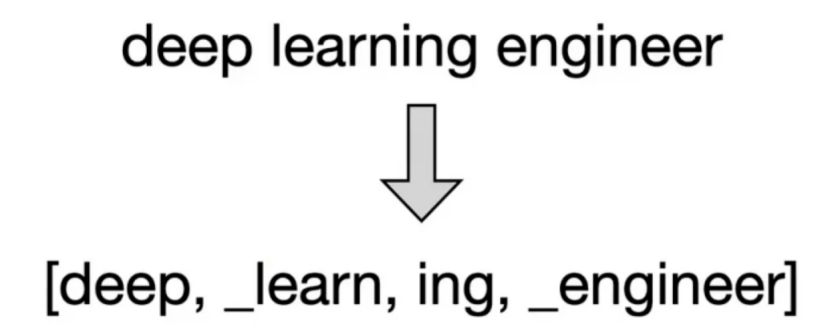
Ø 句子重建:通过连接token并将下划线替换为空格,可重建原始句子。
示例:
对于句子“deep learning engineer”,SentencePiece可能生成标记如[“deep”, “_learning”, “_engineer”],下划线代表空格,以便重建原句。
优势与局限性
Ø 优势:高度灵活,无需预分词即可处理多种语言。
Ø 局限性:将空格作为token的一部分,可能使某些应用的输出不够直观。
6、BPE和其它算法的对比
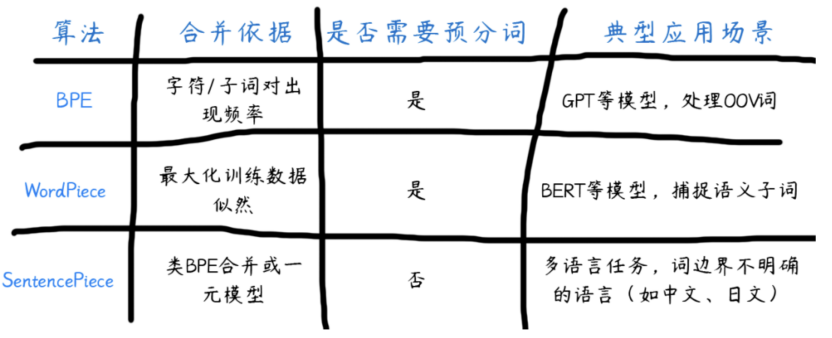
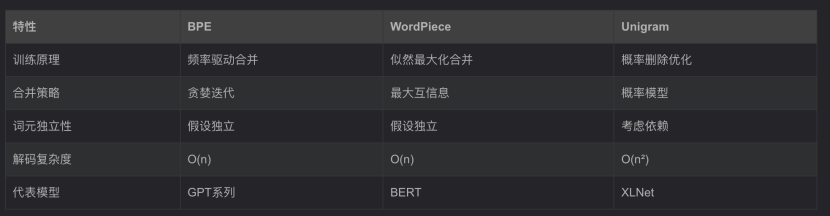
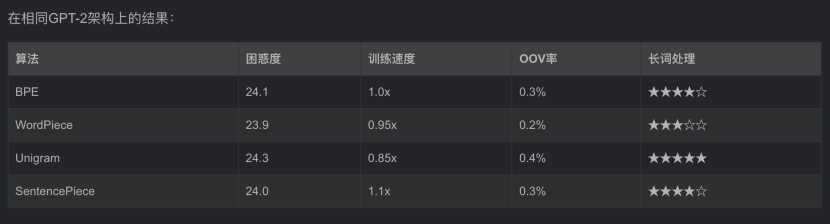
7、BPE在GPT中的演进

8、BPE最佳实践与问题解决方案
参数配置推荐:
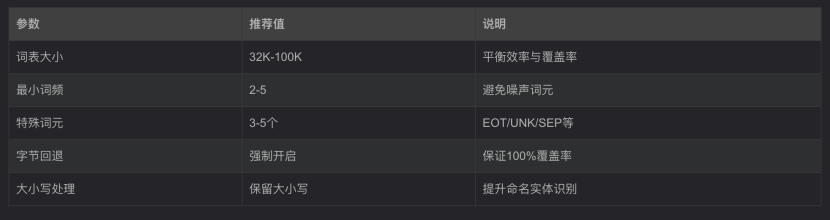
问题解决方案:

结论:
分词是为大语言模型准备文本数据的关键步骤。本文讨论的三种算法(BPE、WordPiece和SentencePiece)各有优势,适用于不同场景:BPE和WordPiece分别广泛应用于GPT和BERT等模型,而SentencePiece为多语言应用提供了更高的灵活性。通过理解这些算法的细微差别,从业者可以针对特定的NLP任务,明智地选择合适的分词方法。

本文来自博客园,作者:limingqi,转载请注明原文链接:https://www.cnblogs.com/limingqi/p/18993211

 浙公网安备 33010602011771号
浙公网安备 33010602011771号