POLAR 的无监督预训练
POLAR 的无监督预训练过程可以拆解为 “数据构建逻辑” 和 “对比学习目标” 两部分,结合具体例子会更易理解:
一、核心目标
让奖励模型(RM)像 “策略侦探” 一样,学会判断两条轨迹(模型输出)是否来自同一个 “政策”(即同一个模型或相似行为模式的模型)。如果来自同一政策,就给它们更高的 “相似度分”;如果来自不同政策,就给更低的分。通过这种训练,RM 能自动捕捉不同模型的行为差异,为后续判断 “哪个轨迹更接近目标政策” 打下基础。
二、具体训练细节拆解
1. 多样化政策池:从哪里找 “嫌疑人”?
2. 构建训练数据:制造 “案发现场”
为了让 RM 学习 “判断两条轨迹是否来自同一政策”,需要构建对比样本:
类比:就像给侦探看三组证据 —— 前两份来自同一嫌疑人,第三份来自另一个嫌疑人,让侦探学会区分 “是否同属一伙”。
3. 对比学习目标:用 BT 损失教 RM “打分”
采用Bradley-Terry(BT)损失,核心是让 RM 对 “同一政策的轨迹对” 打更高的分,对 “不同政策的轨迹对” 打更低的分。
分数 1:r (p, τ₁, τ₂) → 衡量 τ₁和 τ₂的 “政策一致性”(预期:同一政策,分数高)。
分数 2:r (p, τ₁, τ₃) → 衡量 τ₁和 τ₃的 “政策一致性”(预期:不同政策,分数低)。
BT 损失要求:
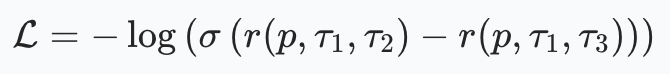
其中 σ 是 sigmoid 函数,目标是让 “同一政策组分数 - 不同政策组分数” 尽可能大(趋近于正无穷),此时损失趋近于 0。
4. 训练结果:RM 学会了什么?
经过大规模预训练(3.6T tokens),RM 会形成一种 “直觉”:
这一步不涉及 “人类偏好”,只学 “政策差异”,就像侦探先学 “认人”,再学 “判断谁是好人”。
三、为何这样设计?
传统奖励模型直接学 “人类觉得哪个好”,但人类偏好数据少且主观;而 POLAR 先学 “模型行为差异”,这种数据可以无限生成(只要有足够多模型),且目标更通用。后续微调时,只需告诉 RM “人类喜欢的目标政策是什么样的”,它就能快速用学到的 “差异识别能力” 去判断 “哪个轨迹更接近目标”。
比如:预训练后,RM 已能区分 “模型 C(擅长 STEM)和模型 D(擅长聊天)的轨迹差异”;微调时给它 “人类认为好的 STEM 回答” 作为目标政策,它就能准确打分 —— 更像模型 C 的轨迹得分更高。
论文:
https://arxiv.org/pdf/2507.05197

本文来自博客园,作者:limingqi,转载请注明原文链接:https://www.cnblogs.com/limingqi/articles/18984322

 浙公网安备 33010602011771号
浙公网安备 33010602011771号