pandas数据表

安装 pip3 install pandas
s=pd.Series([1,3,6,90,44,1]) #创建序列【用列表创建】。数据源的维度必须是一维
#data 指定数据源
print(s)

前面自动产生一个序号
s=pd.Series(data=np.arange(5,9),index=['语文','数学','物理','化学']) #创建序列[用numpy创建]
# index 指定索引

dic={'物理':87,'化学':67,'语文':77,'数学':54}
s=pd.Series(data=dic) #创建序列[用字典创建].
#不能使用index 字典中的key就是索引
s=pd.date_range(start='20170101',end='20170105') #生成一个日期时间索引
# start 指定开始时间; end 指定结束时间

s=pd.date_range(start='20170101',periods=4)
# periods 数据的个数
![]()
s=pd.date_range(start='20170101',periods=6,freq='2D')
#freq:日期偏移量,取值为string或DateOffset,默认为'D'

s=pd.date_range(start='20170101',end='20170110',freq='3D',name='dt')
# 对象的名称
s=pd.date_range(start='2017-01-01 08:10:50',periods=6,freq='s')
# 偏移量是 秒

s=pd.date_range(start='2017-01-01 08:10:50',periods=6,freq='s',normalize=True)
#normalize:若参数为True表示将start、end参数值正则化到午夜时间戳

s=pd.date_range(start='20170101',end='20170110',freq='3D')
![]()
s=pd.date_range(start='20170101',end='20170110',freq='3D',closed='left')
#顾左不顾右
![]()
与上图对比一下
s=pd.date_range(start='20170101',end='20170110',freq='3D',closed='right')
#closed='right' 顾右不顾左
![]()
与上面两图对比一下
q=pd.DataFrame(np.random.randn(4,4),index=list('ABCD'),columns=list('ABCD')) #创建数据表
#DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表
#DataFrame可以设置列名columns与行名index,可以通过位置获取数据也可以通过列名和行名定位
#第一个参数是存放在数据表里的数据 可以是:numpy的矩阵对象、字典、列表
#index就是设置行名 columns设置列明 可以省略
#后两个参数可以使用list输入,但是注意,这个list的长度要和DataFrame的大小匹配

s=pd.date_range(start='20170101',end='20170110',freq='3D')
q=pd.DataFrame(np.random.randn(4,4),index=s,columns=list('ABCD')) #创建数据表
# s 是date_range日期时间索引对象

dic1={'name':['小明','小红','狗蛋','铁柱'],'age':[17,20,5,40],'性别':['男','女','女','男']}
q=pd.DataFrame(dic1) #用字典创建数据表
#每个key的value代表一列,而key是这一列的列名

s=q.dtypes #返回各列的数据类型

q=pd.DataFrame(np.random.randn(6,6))
s=q.head(3) #返回数据表前n行数据
#参数 指定行数 默认5

s=q.tail(3) #返回数据表后n行数据

s=q.index #返回数据表的行名
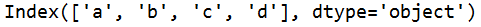
s=q.columns #返回数据表的列名

s=q.values #返回数据表的数据
#返回值类型:numpy矩阵

s=q['B'].values #返回B列的数据
#返回值类型:numpy矩阵
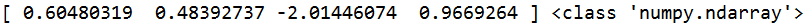
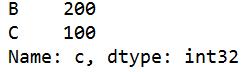
s=q.loc['b'] #返回b行的列名和对应的数据
#只能根据行来查看

s=q.iloc[1] #返回指定索引行的列名和对应的数据

s=q.shape[0] #查看数据表行数 4 <class 'int'>
s=q.shape[1] #查看数据表列数 4 <class 'int'>
s=q.T #行列转置
s=q.describe() #对数值型的列进行统计
#如果想对行进行描述性统计,转置后进行describe
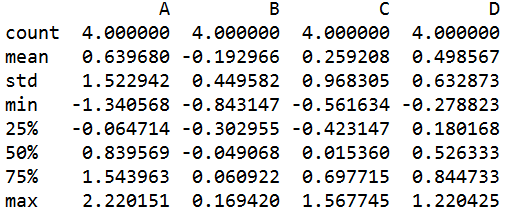
count 行数 mean 平均值 std 标准差
min 最小值 max 最大值
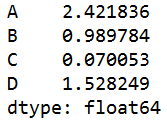
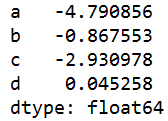
s=q.sum() #对所有列求和
s = self.df['物理'].sum() #对物理列求和
如果是文本列,就是把所有文本加成一个字符串
s=q.sum(1) #对每行求和
#而一行中,有字符串有数值则只计算数值
x=np.array([[1,5,2,3],[10,40,20,30],[300,200,100,400],[4,4,4,4]])
q=pd.DataFrame(x,index=list('abcd'),columns=list('ABCD'))
s=q.apply(lambda x:x*2) #对每个元素进行计算
#如果元素是字符串,则会把字符串再重复一遍
#乘方运算如果有元素是字符串的话,会报错

q['E']=[99,34,12,3] #在后面添加一列
#E 添加的列名

q.insert(1,'F',[88,888,8,888]) #插入一列
#参数1 插入列的索引 其他的列顺延
# 参数2 列名

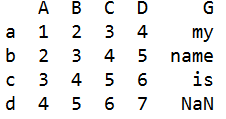
df6=pd.DataFrame(['my','name','is','a'],index=list('abch'),columns=list('G'))
df2=pd.DataFrame([[1,2,3,4],[2,3,4,5],[3,4,5,6],[4,5,6,7]],index=list('abcd'),columns=list('ABCD'))
s=df2.join(df6) #把df6合并到df2
#根据行名 列名 来合并
#两个表有列名相同时就会报错
#s的行是以df2的行index为基准的,在df2相应行不存在数据时,就NaN=空 来填充
df8=df2.join(df6,how='inner') #把df6合并到df2
#how='inner' 交集:只返回两个数据表相同行名的行

df9=df2.join(df6,how='outer') #把df6合并到df2
#'outer'表示并集 :返回两个表的所有行
#如果要合并多个Dataframe,可以用list把几个Dataframe装起来,然后使用concat转化为一个新的Dataframe
df10=pd.DataFrame([1,2,3,4],index=list('abcd'),columns=['A'])
df11=pd.DataFrame([10,20,30,40],index=list('abcd'),columns=['B'])
df12=pd.DataFrame([100,200,300,400],index=list('abcd'),columns=['A'])
list1=[df10, df11, df12]
df13=pd.concat(list1) #合并多个数据表
#参数 是 数据表的列表
#df13 的列是所有数据表不同列名的总和
#df13 的行是所有数据表的总行数
x=np.array([[1,5,2,3],[10,40,20,30],[300,200,100,400],[4,4,4,4]])
q=pd.DataFrame(x,index=list('abcd'),columns=list('ABCD'))
s=q.sort_index(axis=0,ascending=False)#排序.根据列名或行名
#axis=1 对列名排序;axis=0 对行名排序
#ascending=False 降序;ascending=True 升序
s=q.sort_values(by='b',ascending= False,axis=1) #排序。根据数据
#by 根据哪一行或哪一列
#ascending=False 降序;ascending=True 升序
#axis=1 根据某行数据; axis=0 根据某列数据
df.sort_values(by='物理',inplace=True) #排序--根据数据排序 #by='物理'--排序的列 #inplace=True---在原数据表排序,不生成新数据表
s=q['A'] #返回某列数据
s=q.A #返回某列数据

s=q[['B','C']] #返回某n列的数据

s=q[1:3] #返回1到3行的数据。骨头不顾尾
s=q['b':'c'] #返回b行到c行的数据。包括c行
s=q.loc['b'] #返回b行数据

s=q.loc[:,['B','C']] #返回B列、C列所有行的数据

s=q.loc['c',['B','C']] #返回c行的B列、C列数据
s=q.iloc[1:3,1:3] #返回第一行到第三行的第一列到第三列数据
s=q.iloc[2] #返回某行数据
s=q.iloc[2,2] #返回某行某列的数据
s=q.iloc[[1,3],1:3] #返回第一行和第三行的第一列到第三列数据
s=q.ix[0:3,['A','C']] #返回 0:3行,A列和C列 【混合筛选】
s=q.ix[['a','c'],0:3] #返回 a行c行,0:3列
s=q[q.A>8] #筛选A列大于8的所有数据

e=[40,200]
s=q[q['B'].isin(e)] #筛选出所有B列的值在e=[40,200]这个范围内的记录

q[q.B>20]=0 #B列>20的行数据都改成0
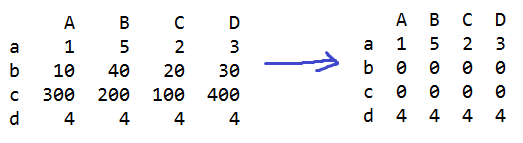
q.A[q.B>20]=0 #B列>20的A列行数据都改成0

s=q.dropna(axis=0,how='any') #删除存在NaN时的数据
#axis=0 删除存在NaN所在行 ;axis=1 删除存在NaN所在列
#how='any' 存在一个NaN时就删除;how='all' 都是NaN时才删除

s=q.fillna(value=0) #把NaN都改成0

s=q.fillna({'A':10,'B':20,'C':30}) #修改NaN的值
#A列的NaN都修改成10;B列的NaN都修改成20;C列的NaN都修改成30
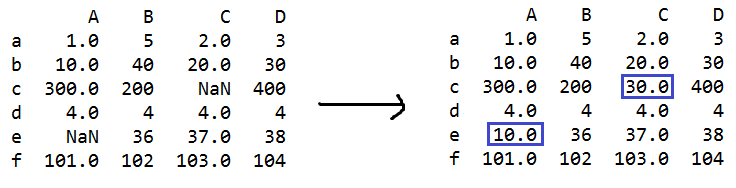
q.fillna({'A':10,'B':20,'C':30},inplace=True) #修改NaN的值
#A列的NaN都修改成10;B列的NaN都修改成20;C列的NaN都修改成30
#inplace=True 不创建副本,在原数据表中修改
s=q.fillna(method='ffill')
#method='ffill' 或者 method='pad' 用前一个非缺失值去填充NaN
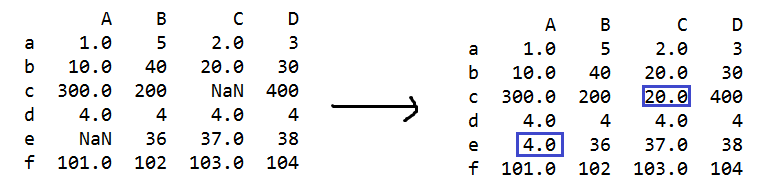
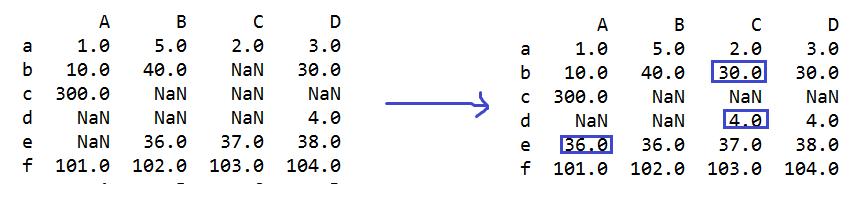
s=q.fillna(method='backfill') #用下一个非缺失值填充NaN

s=q.fillna(method='backfill',limit=1)
#limit=1 限制每列或每行连续NaN的修改次数

s=q.fillna(method='backfill',limit=1,axis=1)
#limit=1 限制每列或每行连续NaN的修改次数
#axis=1 limit按行方向计算;axis=0 limit按列方向计算
s=q.isnull() #判断每个元素是否为缺省值NaN
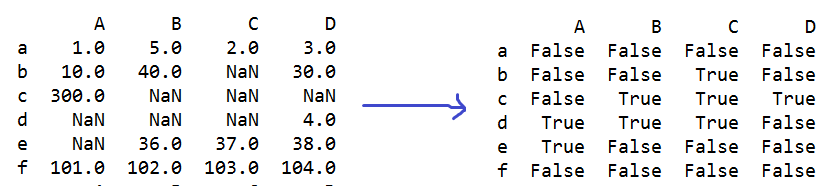
e=np.any(s) == True #s数据表中只要有一个数据是True就返回True
e=np.all(s) == True #s数据表中所有数据都是True就返回True
Pandas中的数据可以加载、存储的文件格式:

q=pd.read_csv(r'D:/ss/成绩1.csv') #读取CSV(逗号分割)文件到数据表
q.to_pickle(r'D:/ss/成绩1.pickle') #把数据表存储为pickle文件
s=pd.concat([q,q1,q2],axis=0,ignore_index=True) #数据表合并
#axis=0 纵向合并
#ignore_index=True 新数据表的索引重新排列

s=pd.concat([q,q3],axis=0,ignore_index=True,join='outer') #数据表合并
#join='outer' 各表中不同的列名或行名 都合并
#join='inner' 只取各表相同的列名或行名


s=pd.concat([q,q3],axis=1,ignore_index=True,join_axes=[q.index]) #数据表合并
#join_axes=[q.index] 横向合并时只取q的行
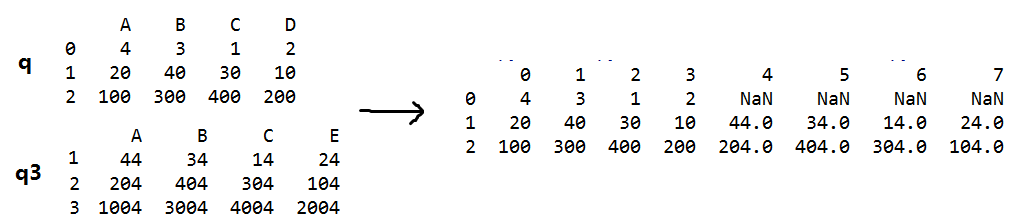
s=pd.concat([q,q3],axis=0,ignore_index=True,join_axes=[q.columns]) #数据表合并
#join_axes=[q.columns] 纵向合并时只取q的列

s=q.append(q1,ignore_index=True) #在q表后面追加q1表
#不修改q1表
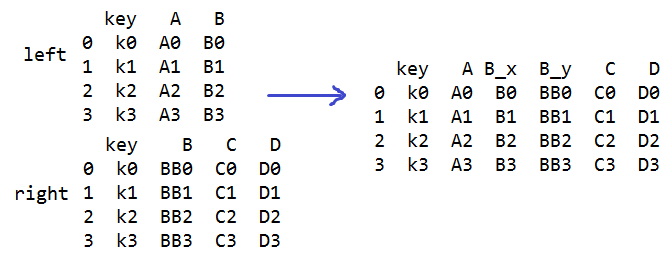
s=pd.merge(left,right,on='key') #合并数据表
#on 设置连接键,连接键的列名要相等,两个表必须都有连接键,合并后连接键只出现一次
#非连接键都会出现,有同名的会自动改名
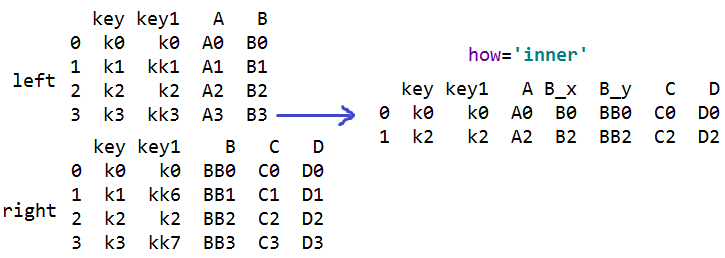
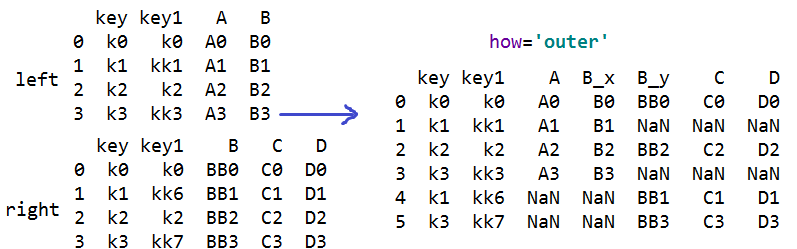
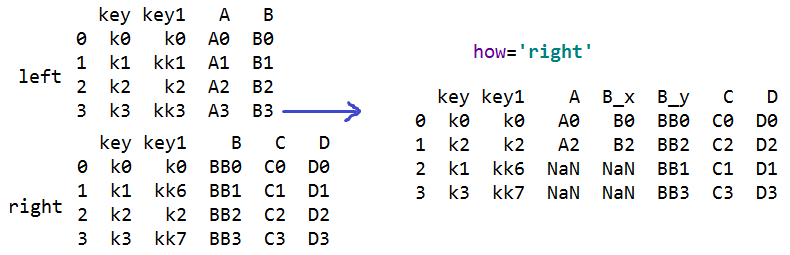
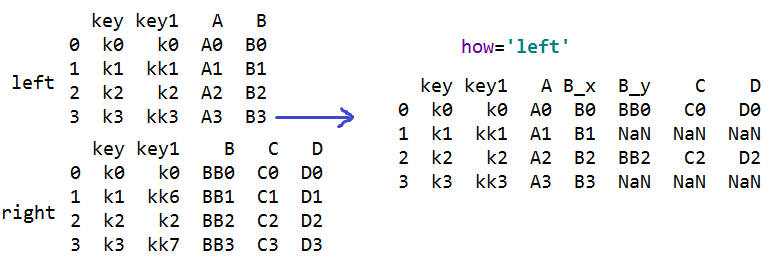
s=pd.merge(left,right,on=['key','key1']) #合并数据表,多个连接键合并
#on 设置连接键,连接键的列名要相等,两个表必须都有连接键,合并后连接键只出现一次
#非连接键都会出现,有同名的会自动改名
#多个连接键合并:how='inner' 只会合并连接键相同的行,默认;
#how='outer' 都合并进来
#how='right' 只合并右对象的连接键
#how='left' 只合并左对象的连接键
#indicator=True 显示出此行在哪个表格中出现

1 import pandas as pd 2 import numpy as np 3 4 s=pd.Series(data=[1,3,6,90,44,1]) #创建序列[用列表创建]。数据源的维度必须是一维 5 #data 指定数据源 6 s=pd.Series(data=np.arange(5,9),index=['语文','数学','物理','化学']) #创建序列[用numpy创建] 7 # index 指定索引 8 dic={'物理':87,'化学':67,'语文':77,'数学':54} 9 s=pd.Series(data=dic) #创建序列[用字典创建]. 10 #不能使用index 字典中的key就是索引 11 s=pd.date_range(start='20170101',end='20170105') #生成一个日期时间索引 12 # start 指定开始时间; end 指定结束时间 13 s=pd.date_range(start='20170101',periods=4) 14 # # periods 数据的个数 15 s=pd.date_range(start='20170101',periods=6,freq='2D') 16 #freq:日期偏移量,取值为string或DateOffset,默认为'D' 17 s=pd.date_range(start='20170101',end='20170110',freq='3D',name='dt') 18 # 对象的名称 19 s=pd.date_range(start='2017-01-01 08:10:50',periods=6,freq='s') 20 # 偏移量是 秒 21 s=pd.date_range(start='2017-01-01 08:10:50',periods=6,freq='s',normalize=True) 22 #normalize:若参数为True表示将start、end参数值正则化到午夜时间戳 23 24 s=pd.date_range(start='20170101',end='20170110',freq='3D',closed='left') 25 #closed='left' 顾左不顾右 26 27 s=pd.date_range(start='20170101',end='20170110',freq='3D',closed='right') 28 #closed='right' 顾右不顾左 29 30 q=pd.DataFrame(np.random.randn(4,4),index=list('ABCD'),columns=list('ABCD')) #创建数据表 31 #DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表 32 #DataFrame可以设置列名columns与行名index,可以通过位置获取数据也可以通过列名和行名定位 33 #第一个参数是存放在数据表里的数据 可以是:numpy的矩阵对象、字典、列表 34 #index就是设置行名 columns设置列明 可以省略 35 #后两个参数可以使用list输入,但是注意,这个list的长度要和DataFrame的大小匹配 36 37 s=pd.date_range(start='20170101',end='20170110',freq='3D') 38 q=pd.DataFrame(np.random.randn(4,4),index=s,columns=list('ABCD')) #创建数据表 39 # s 是date_range日期时间索引对象 40 41 dic1={'name':['小明','小红','狗蛋','铁柱'],'age':[17,20,5,40],'性别':['男','女','女','男']} 42 q=pd.DataFrame(dic1) #用字典创建数据表 43 #每个key的value代表一列,而key是这一列的列名 44 45 s=q.dtypes #返回各列的数据类型 46 47 q=pd.DataFrame(np.random.randn(6,6)) 48 s=q.head(3) #返回数据表前n行数据 49 #参数 指定行数 默认5 50 51 s=q.tail(3) #返回数据表后n行数据 52 q=pd.DataFrame(np.random.randn(4,4),index=list('abcd'),columns=list('ABCD')) 53 s=q.index #返回数据表的行名 54 s=q.columns #返回数据表的列名 55 s=q.values #返回数据表的数据 56 #返回值类型:numpy矩阵 57 s=q['B'].values #返回B列的数据 58 #返回值类型:numpy矩阵 59 s=q.loc['b'] #返回b行的列名和对应的数据 60 #只能根据行来查看 61 62 s=q.iloc[1] #返回指点索引行的列名和对应的数据 63 s=q.shape[0] #查看行数 4 <class 'int'> 64 s=q.shape[1] #查看列数 4 <class 'int'> 65 66 s=q.T #行列转置 67 s=q.describe() #对数值型的列进行统计 68 #如果想对行进行描述性统计,转置后进行describe 69 s=q.sum() #对每列求和 70 s=q.sum(1) #对每行求和 71 #而一行中,有字符串有数值则只计算数值 72 73 x=np.array([[1,5,2,3],[10,40,20,30],[300,200,100,400],[4,4,4,4]]) 74 q=pd.DataFrame(x,index=list('abcd'),columns=list('ABCD')) 75 s=q.apply(lambda x:x*2) #对每个元素进行计算 76 #如果元素是字符串,则会把字符串再重复一遍 77 #乘方运算如果有元素是字符串的话,会报错 78 79 q['E']=[99,34,12,3] #在后面添加一列 80 #E 添加的列名 81 q.insert(1,'F',[88,888,8,888]) #参数一列 82 #参数1 插入列的索引 其他的列顺延 83 # 参数2 列名 84 85 df6=pd.DataFrame(['my','name','is','a'],index=list('abch'),columns=list('G')) 86 df2=pd.DataFrame([[1,2,3,4],[2,3,4,5],[3,4,5,6],[4,5,6,7]],index=list('abcd'),columns=list('ABCD')) 87 s=df2.join(df6) #把df6合并到df2 88 #根据行名 列名 来合并 89 #两个表有列名相同时就会报错 90 #s的行是以df2的行index为基准的,在df2相应行不存在数据时,就NaN=空 来填充 91 92 df8=df2.join(df6,how='inner') #把df6合并到df2 93 #how='inner' 交集:只返回两个数据表相同行名的行 94 95 df9=df2.join(df6,how='outer') #把df6合并到df2 96 #'outer'表示并集 :返回两个表的所有行 97 98 #如果要合并多个Dataframe,可以用list把几个Dataframe装起来,然后使用concat转化为一个新的Dataframe 99 df10=pd.DataFrame([1,2,3,4],index=list('abcd'),columns=['A']) 100 df11=pd.DataFrame([10,20,30,40],index=list('abcd'),columns=['B']) 101 df12=pd.DataFrame([100,200,300,400],index=list('abcd'),columns=['C']) 102 list1=[df10, df11, df12] 103 df13=pd.concat(list1) #合并多个数据表 104 #参数 是 数据表的列表 105 #df13 的列是所有数据表不同列名的总和 106 #df13 的行是所有数据表的总行数 107 108 x=np.array([[1,5,2,3],[10,40,20,30],[300,200,100,400],[4,4,4,4]]) 109 q=pd.DataFrame(x,index=list('abcd'),columns=list('ABCD')) 110 s=q.sort_index(axis=0,ascending=False)#排序.根据列名或行名 111 #axis=1 对列名排序;axis=0 对行名排序 112 #ascending=False 降序;ascending=True 升序 113 s=q.sort_values(by='b',ascending= False,axis=1) #排序。根据数据 114 #by 根据哪一行或哪一列 115 #ascending=False 降序;ascending=True 升序 116 #axis=1 根据某行数据; axis=0 根据某列数据 117 118 s=q['A'] #返回某列数据 119 s=q[['B','C']] #返回某n列的数据 120 s=q.A #返回某列数据 121 s=q[1:3] #返回1到3行的数据。骨头不顾尾 122 s=q['b':'c'] #返回b行到c行的数据。包括c行 123 s=q.loc['b'] #返回b行数据 124 s=q.loc[:,['B','C']] #返回B列、C列所有行的数据 125 s=q.loc['c',['B','C']] #返回c行的B列、C列数据 126 s=q.iloc[2] #返回某行数据 127 s=q.iloc[2,2] #返回某行某列的数据 128 s=q.iloc[1:3,1:3] #返回第一行到第三行的第一列到第三列数据 129 s=q.iloc[[1,3],1:3] #返回第一行和第三行的第一列到第三列数据 130 s=q.ix[0:3,['A','C']] #返回 0:3行,A列和C列 【混合筛选】 131 s=q.ix[['a','c'],0:3] #返回 a行c行,0:3列 132 s=q[q.A>8] #筛选出A列大于8的所有数据 133 134 e=[40,200] 135 s=q[q['B'].isin(e)] #筛选出所有B列的值在e=[40,200]这个范围内的记录 136 137 #q.iloc[2,2]=77 #修改某行某列的值 138 #q.loc['c','B']=54 #修改某行某列的值 139 q[q.B>20]=0 #B列>20的行数据都改成0 140 141 print(q) 142 print(s)
1 import pandas as pd 2 import numpy as np 3 4 x=np.array([[1,5,2,3],[10,40,20,30],[300,200,100,400],[4,4,4,4]]) 5 q=pd.DataFrame(x,index=list('abcd'),columns=list('ABCD')) 6 7 #q[q.B>20]=0 #B列>20的行数据都改成0 8 q.A[q.B>20]=0 #B列>20的A列行数据都改成0 9 10 x=np.array([[1,5,2,3],[10,40,20,30],[300,200,100,400],[4,4,4,4],[35,36,37,38],[101,102,103,104]]) 11 q=pd.DataFrame(x,index=list('abcdef'),columns=list('ABCD')) 12 q.iloc[2,2]=np.NaN 13 q.iloc[4,0]=np.NaN 14 #s=q.dropna(axis=0,how='any') #删除存在NaN时的数据 15 #axis=0 删除存在NaN所在行 ;axis=1 删除存在NaN所在列 16 #how='any' 存在一个NaN时就删除;how='all' 都是NaN时才删除 17 18 #s=q.fillna(value=0) #把NaN都改成0 19 #s=q.fillna({'A':10,'B':20,'C':30},inplace=True) #修改NaN的值 20 #A列的NaN都修改成10;B列的NaN都修改成20;C列的NaN都修改成30 21 22 #q.fillna({'A':10,'B':20,'C':30},inplace=True) #修改NaN的值 23 #A列的NaN都修改成10;B列的NaN都修改成20;C列的NaN都修改成30 24 #inplace=True 不创建副本,在原数据表中修改 25 26 # s=q.fillna(method='ffill') 27 # #method='ffill' 或者 method='pad' 用前一个非缺失值去填充NaN 28 # 29 # s=q.fillna(method='backfill') #用下一个非缺失值填充NaN 30 # s=q.isnull() #判断各个数据是否缺失值NaN 31 32 q.iloc[3,0]=np.NaN 33 q.iloc[3,2]=np.NaN 34 q.iloc[1,2]=np.NaN 35 q.iloc[2,1]=np.NaN 36 q.iloc[2,3]=np.NaN 37 q.iloc[3,1]=np.NaN 38 s=q.fillna(method='backfill',limit=1,axis=1) 39 #limit=1 限制每列或每行连续NaN的修改次数 40 #axis=1 limit按行方向计算;axis=0 limit按列方向计算 41 42 s=q.isnull() #判断每个元素是否为缺省值NaN 43 e=np.any(s) == True #s数据表中只要有一个数据是True就返回True 44 e=np.all(s) == True #s数据表中所有数据都是True就返回True 45 46 print(q) 47 print(s) 48 print(e)
1 import pandas as pd 2 import numpy as np 3 4 # q=pd.read_csv(r'D:/ss/成绩1.csv') #读取CSV(逗号分割)文件到数据表 5 # q.to_pickle(r'D:/ss/成绩1.pickle') #把数据表存储为pickle文件 6 q=pd.DataFrame([[4,3,1,2],[20,40,30,10],[100,300,400,200]],columns=list('ABCD')) #创建数据表 7 q1=pd.DataFrame([[45,35,15,25],[205,405,305,105],[1005,3005,4005,2005]],columns=list('ABCD')) 8 q2=pd.DataFrame([[41,31,11,21],[201,401,301,101],[1001,3001,4001,2001]],columns=list('ABCD')) 9 q3=pd.DataFrame([[44,34,14,24],[204,404,304,104],[1004,3004,4004,2004]],index=[1,2,3],columns=list('ABCE')) 10 # s=pd.concat([q,q1,q2],axis=0,ignore_index=True) #数据表合并 11 #axis=0 纵向合并 12 #ignore_index=True 新数据表的索引重新排列 13 14 # s=pd.concat([q,q3],axis=0,ignore_index=True,join='inner') #数据表合并 15 #join='outer' 各表中不同的列名或行名 都合并 16 #join='inner' 只取各表相同的列名或行名 17 18 # s=pd.concat([q,q3],axis=1,ignore_index=True,join_axes=[q.index]) #数据表合并 19 #join_axes=[q.index] 横向合并时只取q的行 20 21 #s=pd.concat([q,q3],axis=0,ignore_index=True,join_axes=[q.columns]) #数据表合并 22 #join_axes=[q.columns] 纵向合并时只取q的列 23 24 s=q.append(q1,ignore_index=True) #在q表后面追加q1表 25 #不修改q1表 26 27 left=pd.DataFrame({'key':['k0','k1','k2','k3'], 28 'key1':['k0','kk1','k2','kk3'], 29 'A':['A0','A1','A2','A3'], 30 'B':['B0','B1','B2','B3']}) 31 right=pd.DataFrame({'key':['k0','k1','k2','k3'], 32 'key1':['k0','kk6','k2','kk7'], 33 'B':['BB0','BB1','BB2','BB3'], 34 'C':['C0','C1','C2','C3'], 35 'D':['D0','D1','D2','D3'] 36 }) 37 38 #s=pd.merge(left,right,on=['key','key1'],how='right') #合并数据表,多个连接键合并 39 #两个数据表的行数要相等 40 #on 设置连接键,连接键的列名要相等,两个表必须都有连接键,合并后连接键只出现一次 41 #非连接键都会出现,有同名的会自动改名 42 #多个连接键合并:how='inner' 只会合并连接键相同的行,默认; 43 #how='outer' 都合并进来 44 #how='right' 只合并右对象的连接键 45 #how='left' 只合并左对象的连接键 46 #indicator=True 显示出此行在哪个表格中出现 47 48 s=pd.merge(left,right,on='key',right_index=True) #合并数据表 49 50 print(s)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号