
一: 什么是web框架
1.1 概述
web框架(web framework)或者叫做web应用框架(web application framework),是用于进行web开发的一套软件架构。大多数的web框架提供了一套开发和部署网站的方式。为web的行为提供了一套支持支持的方法。使用web框架,很多的业务逻辑外的功能不需要自己再去完善,而是使用框架已有的功能就可以。
1.2 web框架的功能
web框架使得在进行web应用开发的时候,减少了工作量。web框架主要用于动态网络开发,动态网络主要是指现在的主要的页面,可以实现数据的交互和业务功能的完善。使用web框架进行web开发的时候,在进行数据缓存、数据库访问、数据安全校验等方面,不需要自己再重新实现,而是将业务逻辑相关的代码写入框架就可以。也就是说,通过对web框架进行主观上的“缝缝补补”,就可以实现自己进行web开发的需求了。
1.3 关于Django和Flask的简单介绍
目前Python主流的框架有Django和Flask等。Django是一个比较重量级的框架,重量级的意思是说,Django几乎所有的功能都帮助开发者写好了,有时候如果想做一个简单的网站,并不需要太多功能,这时候使用Django的话,就比较不合适,因为在部署网站的时候会导致很多不必要的功能也部署了进来。而Flask是一个轻量级的框架,一些核心的功能实现了,但是实现的功能并没有Django那么多,这样可以进行自己的发挥,在Flask的基础上,如果想实现更多的功能,可以很方便地加入。
Java目前的主流开发框架是ssm(spring spring-mvc和mybatis)。相比之前的ssh(spring struts hibernate),ssm也是比较轻量级的框架。
1.4 总结
web框架是用来进行web应用开发的一个软件架构。主要用于动态网络开发。开发者在基于web框架实现自己的业务逻辑。web框架实现了很多功能,为实现业务逻辑提供了一套通用方法。
二:模拟DIY(创建)一个web框架
目标:
MySQL:在web数据库中使用pymysql模块创建一个表格,并在该表格中插入数据,这里我们直接在MySQL里面插入的数据----models.py文件
后端:创建一个web服务器,实现能够对/login和/auth路径的判断并返回正确的数据---manage.py文件
前端:浏览器
准备的相应文件login.html
文件:
(1)准备的文件login.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form action="http://127.0.0.1:8000/auth" method="post">
用户名:<input type="text" name="user">
密码:<input type="password" name="pwd">
<input type="submit">
</form>
</body>
</html>
(2)python用于创建MySQL的表的文件models.py


1 # -*- coding:utf-8 -*- 2 # 作用:在数据库中创建表,运行程序生成表结构,这里我们直接在MySQL上插入了数据 3 # id | name | password | 4 # +----+------+----------+ 5 # | 1 | lilz | 123 6 7 import pymysql 8 #连接数据库 9 conn = pymysql.connect(host='127.0.0.1',port= 3306,user = 'root',passwd='123',db='web') #db:库名 10 #创建游标 11 cur = conn.cursor() 12 13 sql=''' 14 create table userinfo( 15 id INT PRIMARY KEY , 16 name VARCHAR(32) , 17 password VARCHAR(32) 18 ) 19 20 ''' 21 cur.execute(sql) 22 23 #提交 24 conn.commit() 25 #关闭指针对象 26 cur.close() 27 #关闭连接对象 28 conn.close()
(3)python的web服务器的文件manage.py
1 # 这个模块封装了socketserver 2 from wsgiref.simple_server import make_server 3 # 这是个爬虫模块,这里我们用作解开获取到请求体中的数据 4 from urllib.parse import parse_qs 5 # python与数据库交互的模块 6 import pymysql 7 8 9 def application(environ, start_response): 10 ''' 11 根据路径的不同返回不同的数据 12 :param environ: 表示服务端接收到的请求信息---字典 13 # environ里的PATH_INFO表示请求的路径,获取路径的方法:environ.get("PATH_INFO") 14 :param start_response:封装响应格式的 15 :return: 16 ''' 17 # 获取请求路径 18 print('environ',environ) 19 path=environ.get("PATH_INFO") 20 data = b'404!' 21 if path == '/login': 22 with open('login.html','rb')as f: 23 data = f.read() 24 elif path=='/auth': 25 # 登陆认证 26 # 1.获取用户输入的用户名和密码 27 # 1.1获取请求体的长度 28 request_body_size = int(environ.get('CONTENT_LENGTH', 0)) 29 # 1.2 30 # 可以从请求数据environ中看到'wsgi.input': < _io.BufferedReader name = 832 >是阅读器对象,数据都在这个对象里 31 # 因此下面的read就是读取数据的长度 32 request_body = environ['wsgi.input'].read(request_body_size) 33 # 数据 34 print('=====>',request_body) #=====> b'user=lilz&pwd=123' 35 36 request_data = parse_qs(request_body) 37 print('=====>', request_data) #{b'user': [b'lilz'], b'pwd': [b'123']} 38 user = (request_data.get(b'user')[0]).decode('utf8') 39 pwd = (request_data.get(b'pwd')[0]).decode('utf8') 40 print('=====>', user,pwd) # lilz 123 41 42 43 #2.去数据库做校验,查看用户,密码是否合法,使用pymysql 44 # 连接数据库 45 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='web') # db:库名 46 # 创建游标 47 cur = conn.cursor() 48 49 sql = "select * from userinfo where name = '%s'and password= '%s'" % (user, pwd) 50 51 cur.execute(sql) 52 # cur.fetchone()如果获取成功,就有值 53 if cur.fetchone(): 54 # 验证成功 55 data = "登陆成功".encode('gbk') 56 else: 57 # 验证失败 58 data = "登陆失败".encode('gbk') 59 #3.响应返回 60 # 封包 61 # 响应行、响应头 62 start_response('200 OK', [('Content-Type', 'text/html')]) 63 # 响应体 64 return [data] 65 66 67 httpd = make_server('127.0.0.1', 8000, application) 68 69 print('Serving HTTP on port 8000...') 70 # 开始监听HTTP请求: 71 # (启动:等待客户端连接--->一旦连接成功就会回调到make_server参数里的application函数) 72 httpd.serve_forever()
我们该怎么优化呢?首先我们代码的缺陷就是只有两个路径,如果加一个路径我们又得一个elif,所以我们用函数封住代码
第一次优化:
1 # -*- coding:utf-8 -*- 2 # 这个模块封装了socketserver 3 from wsgiref.simple_server import make_server 4 # 这是个爬虫模块,这里我们用作解开获取到请求体中的数据 5 from urllib.parse import parse_qs 6 # python与数据库交互的模块 7 import pymysql 8 9 10 # 视图函数:处理http请求的函数 11 def login(environ): 12 with open('login.html', 'rb')as f: 13 data = f.read() 14 return data 15 def auth(environ): 16 # 登陆认证 17 # 1.获取用户输入的用户名和密码 18 # 1.1获取请求体的长度 19 request_body_size = int(environ.get('CONTENT_LENGTH', 0)) 20 # 1.2 21 # 可以从请求数据environ中看到'wsgi.input': < _io.BufferedReader name = 832 >是阅读器对象,数据都在这个对象里 22 # 因此下面的read就是读取数据的长度 23 request_body = environ['wsgi.input'].read(request_body_size) 24 # 数据 25 print('=====>', request_body) # =====> b'user=lilz&pwd=123' 26 27 request_data = parse_qs(request_body) 28 print('=====>', request_data) # {b'user': [b'lilz'], b'pwd': [b'123']} 29 user = (request_data.get(b'user')[0]).decode('utf8') 30 pwd = (request_data.get(b'pwd')[0]).decode('utf8') 31 print('=====>', user, pwd) # lilz 123 32 33 # 2.去数据库做校验,查看用户,密码是否合法,使用pymysql 34 # 连接数据库 35 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='web') # db:库名 36 # 创建游标 37 cur = conn.cursor() 38 39 sql = "select * from userinfo where name = '%s'and password= '%s'" % (user, pwd) 40 41 cur.execute(sql) 42 # cur.fetchone()如果获取成功,就有值 43 if cur.fetchone(): 44 # 验证成功 45 data = "登陆成功".encode('gbk') 46 else: 47 # 验证失败 48 data = "登陆失败".encode('gbk') 49 50 return data 51 52 53 def application(environ, start_response): 54 ''' 55 根据路径的不同返回不同的数据 56 :param environ: 表示服务端接收到的请求信息---字典 57 # environ里的PATH_INFO表示请求的路径,获取路径的方法:environ.get("PATH_INFO") 58 :param start_response:封装响应格式的 59 :return: 60 ''' 61 # 获取请求路径 62 print('environ',environ) 63 path=environ.get("PATH_INFO") 64 data = b'404!' 65 if path == '/login': 66 data=login(environ) 67 elif path=='/auth': 68 data=auth(environ) 69 70 #3.响应返回 71 # 封包 72 # 响应行、响应头 73 start_response('200 OK', [('Content-Type', 'text/html')]) 74 # 响应体 75 return [data] 76 77 78 httpd = make_server('127.0.0.1', 8000, application) 79 80 print('Serving HTTP on port 8000...') 81 # 开始监听HTTP请求: 82 # (启动:等待客户端连接--->一旦连接成功就会回调到make_server参数里的application函数) 83 httpd.serve_forever()
再次优化时,我们可以把视图函数单独存放在一个文件中views.py
我们把判断路径的if语句换成循环,可以把所有的路径放在一个列表里这样遍历列表,找到和请求中的路径一样的,然后再调用该路径函数
第二次优化:
1 # -*- coding:utf-8 -*- 2 # 这个模块封装了socketserver 3 from wsgiref.simple_server import make_server 4 from views import login,auth,fav 5 # python与数据库交互的模块 6 import pymysql 7 8 9 def application(environ, start_response): 10 ''' 11 根据路径的不同返回不同的数据 12 :param environ: 表示服务端接收到的请求信息---字典 13 # environ里的PATH_INFO表示请求的路径,获取路径的方法:environ.get("PATH_INFO") 14 :param start_response:封装响应格式的 15 :return: 16 ''' 17 # 获取请求路径 18 print('environ',environ) 19 path=environ.get("PATH_INFO") 20 21 # url与视图函数的映射关系 22 urlpattens = [ 23 ('/login',login), 24 ('/auth',auth), 25 ('/favicon.ico',fav) #图标请求,经常覆盖其他的请求,这个请求是图标,回应数据时不会把别的覆盖掉 26 ] 27 28 func=None 29 # 遍历url与视图函数的映射关系列表,如果有和请求消息中路径相等的我们把该路径对应的视图函数取出来赋给func,然后调用视图函数 30 for item in urlpattens: 31 if item[0]==path: 32 func=item[1] 33 break 34 func = None 35 for item in urlpattens: 36 print("------>", item[0]) 37 if item[0] == path: 38 func = item[1] 39 break 40 if not func: 41 data = b"<h1>404</h1>" 42 else: 43 data = func(environ) 44 45 #3.响应返回 46 # 封包 47 # 响应行、响应头 48 start_response('200 OK', [('Content-Type', 'text/html')]) 49 # 响应体 50 return [data] 51 52 53 httpd = make_server('127.0.0.1', 8000, application) 54 55 print('Serving HTTP on port 8000...') 56 # 开始监听HTTP请求: 57 # (启动:等待客户端连接--->一旦连接成功就会回调到make_server参数里的application函数) 58 httpd.serve_forever()
注意图标请求的影响,代码里面有做处理。这里准备了一张favicon.ico的标题图标文件,自己下载放到项目目录中
1 # -*- coding:utf-8 -*- 2 # 这是个爬虫模块,这里我们用作解开获取到请求体中的数据 3 from urllib.parse import parse_qs 4 import pymysql 5 6 7 # 视图函数:处理http请求的函数 8 def login(environ): 9 with open('login.html', 'rb')as f: 10 data = f.read() 11 return data 12 def auth(environ): 13 # 登陆认证 14 # 1.获取用户输入的用户名和密码 15 # 1.1获取请求体的长度 16 request_body_size = int(environ.get('CONTENT_LENGTH', 0)) 17 # 1.2 18 # 可以从请求数据environ中看到'wsgi.input': < _io.BufferedReader name = 832 >是阅读器对象,数据都在这个对象里 19 # 因此下面的read就是读取数据的长度 20 request_body = environ['wsgi.input'].read(request_body_size) 21 # 数据 22 print('=====>', request_body) # =====> b'user=lilz&pwd=123' 23 24 request_data = parse_qs(request_body) 25 print('=====>', request_data) # {b'user': [b'lilz'], b'pwd': [b'123']} 26 user = (request_data.get(b'user')[0]).decode('utf8') 27 pwd = (request_data.get(b'pwd')[0]).decode('utf8') 28 print('=====>', user, pwd) # lilz 123 29 30 # 2.去数据库做校验,查看用户,密码是否合法,使用pymysql 31 # 连接数据库 32 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='web') # db:库名 33 # 创建游标 34 cur = conn.cursor() 35 36 sql = "select * from userinfo where name = '%s'and password= '%s'" % (user, pwd) 37 38 cur.execute(sql) 39 # cur.fetchone()如果获取成功,就有值 40 if cur.fetchone(): 41 # 验证成功 42 data = "登陆成功".encode('gbk') 43 else: 44 # 验证失败 45 data = "登陆失败".encode('gbk') 46 47 return data 48 49 def fav(environ): 50 with open("favicon.ico",'rb')as f: 51 data = f.read() 52 return data
第三次优化:
把url与视图函数的对应关系的列表单独放在一个文件中---url.py
1 # -*- coding:utf-8 -*- 2 # 这个模块封装了socketserver 3 from wsgiref.simple_server import make_server 4 from url import urlpattens 5 # python与数据库交互的模块 6 import pymysql 7 8 9 def application(environ, start_response): 10 ''' 11 根据路径的不同返回不同的数据 12 :param environ: 表示服务端接收到的请求信息---字典 13 # environ里的PATH_INFO表示请求的路径,获取路径的方法:environ.get("PATH_INFO") 14 :param start_response:封装响应格式的 15 :return: 16 ''' 17 # 获取请求路径 18 print('environ',environ) 19 path=environ.get("PATH_INFO") 20 21 22 23 func=None 24 # 遍历url与视图函数的映射关系列表,如果有和请求消息中路径相等的我们把该路径对应的视图函数取出来赋给func,然后调用视图函数 25 for item in urlpattens: 26 if item[0]==path: 27 func=item[1] 28 break 29 func = None 30 for item in urlpattens: 31 print("------>", item[0]) 32 if item[0] == path: 33 func = item[1] 34 break 35 if not func: 36 data = b"<h1>404</h1>" 37 else: 38 data = func(environ) 39 40 #3.响应返回 41 # 封包 42 # 响应行、响应头 43 start_response('200 OK', [('Content-Type', 'text/html')]) 44 # 响应体 45 return [data] 46 47 48 httpd = make_server('127.0.0.1', 8000, application) 49 50 print('Serving HTTP on port 8000...') 51 # 开始监听HTTP请求: 52 # (启动:等待客户端连接--->一旦连接成功就会回调到make_server参数里的application函数) 53 httpd.serve_forever()
1 # -*- coding:utf-8 -*- 2 # 这是个爬虫模块,这里我们用作解开获取到请求体中的数据 3 from urllib.parse import parse_qs 4 import pymysql 5 6 7 # 视图函数:处理http请求的函数 8 def login(environ): 9 with open('login.html', 'rb')as f: 10 data = f.read() 11 return data 12 def auth(environ): 13 # 登陆认证 14 # 1.获取用户输入的用户名和密码 15 # 1.1获取请求体的长度 16 request_body_size = int(environ.get('CONTENT_LENGTH', 0)) 17 # 1.2 18 # 可以从请求数据environ中看到'wsgi.input': < _io.BufferedReader name = 832 >是阅读器对象,数据都在这个对象里 19 # 因此下面的read就是读取数据的长度 20 request_body = environ['wsgi.input'].read(request_body_size) 21 # 数据 22 print('=====>', request_body) # =====> b'user=lilz&pwd=123' 23 24 request_data = parse_qs(request_body) 25 print('=====>', request_data) # {b'user': [b'lilz'], b'pwd': [b'123']} 26 user = (request_data.get(b'user')[0]).decode('utf8') 27 pwd = (request_data.get(b'pwd')[0]).decode('utf8') 28 print('=====>', user, pwd) # lilz 123 29 30 # 2.去数据库做校验,查看用户,密码是否合法,使用pymysql 31 # 连接数据库 32 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='web') # db:库名 33 # 创建游标 34 cur = conn.cursor() 35 36 sql = "select * from userinfo where name = '%s'and password= '%s'" % (user, pwd) 37 38 cur.execute(sql) 39 # cur.fetchone()如果获取成功,就有值 40 if cur.fetchone(): 41 # 验证成功 42 data = "登陆成功".encode('gbk') 43 else: 44 # 验证失败 45 data = "登陆失败".encode('gbk') 46 47 return data 48 49 def fav(environ): 50 with open("favicon.ico",'rb')as f: 51 data = f.read() 52 return data
1 from views import login,auth,fav 2 3 # url与视图函数的映射关系 4 urlpattens = [ 5 ('/login', login), 6 ('/auth', auth), 7 ('/favicon.ico', fav) # 图标请求,经常覆盖其他的请求,这个请求是图标,回应数据时不会把别的覆盖掉 8 ]
第四次优化:
这些文件都放一块,不好,我们分好目录
templates:放所有的html文件、图标
这样需要修改一下路径
总结:
templates:放所有的html文件、图标
manage.py:启动文件(总逻辑)
models.py:与数据库交互的文件
url.py:url与视图函数的对应关系的列表---关系映射
views.py:视图函数----逻辑
1 # -*- coding:utf-8 -*- 2 # 这个模块封装了socketserver 3 from wsgiref.simple_server import make_server 4 from url import urlpattens 5 # python与数据库交互的模块 6 import pymysql 7 8 9 def application(environ, start_response): 10 ''' 11 根据路径的不同返回不同的数据 12 :param environ: 表示服务端接收到的请求信息---字典 13 # environ里的PATH_INFO表示请求的路径,获取路径的方法:environ.get("PATH_INFO") 14 :param start_response:封装响应格式的 15 :return: 16 ''' 17 # 获取请求路径 18 print('environ',environ) 19 path=environ.get("PATH_INFO") 20 21 22 23 func=None 24 # 遍历url与视图函数的映射关系列表,如果有和请求消息中路径相等的我们把该路径对应的视图函数取出来赋给func,然后调用视图函数 25 for item in urlpattens: 26 if item[0]==path: 27 func=item[1] 28 break 29 func = None 30 for item in urlpattens: 31 print("------>", item[0]) 32 if item[0] == path: 33 func = item[1] 34 break 35 if not func: 36 data = b"<h1>404</h1>" 37 else: 38 data = func(environ) 39 40 #3.响应返回 41 # 封包 42 # 响应行、响应头 43 start_response('200 OK', [('Content-Type', 'text/html')]) 44 # 响应体 45 return [data] 46 47 48 httpd = make_server('127.0.0.1', 8000, application) 49 50 print('Serving HTTP on port 8000...') 51 # 开始监听HTTP请求: 52 # (启动:等待客户端连接--->一旦连接成功就会回调到make_server参数里的application函数) 53 httpd.serve_forever()
1 from views import login,auth,fav 2 3 # url与视图函数的映射关系 4 urlpattens = [ 5 ('/login', login), 6 ('/auth', auth), 7 ('/favicon.ico', fav) # 图标请求,经常覆盖其他的请求,这个请求是图标,回应数据时不会把别的覆盖掉 8 ]
1 # -*- coding:utf-8 -*- 2 # 这是个爬虫模块,这里我们用作解开获取到请求体中的数据 3 from urllib.parse import parse_qs 4 import pymysql 5 6 7 # 视图函数:处理http请求的函数 8 def login(environ): 9 with open('templates/login.html', 'rb')as f: 10 data = f.read() 11 return data 12 def auth(environ): 13 # 登陆认证 14 # 1.获取用户输入的用户名和密码 15 # 1.1获取请求体的长度 16 request_body_size = int(environ.get('CONTENT_LENGTH', 0)) 17 # 1.2 18 # 可以从请求数据environ中看到'wsgi.input': < _io.BufferedReader name = 832 >是阅读器对象,数据都在这个对象里 19 # 因此下面的read就是读取数据的长度 20 request_body = environ['wsgi.input'].read(request_body_size) 21 # 数据 22 print('=====>', request_body) # =====> b'user=lilz&pwd=123' 23 24 request_data = parse_qs(request_body) 25 print('=====>', request_data) # {b'user': [b'lilz'], b'pwd': [b'123']} 26 user = (request_data.get(b'user')[0]).decode('utf8') 27 pwd = (request_data.get(b'pwd')[0]).decode('utf8') 28 print('=====>', user, pwd) # lilz 123 29 30 # 2.去数据库做校验,查看用户,密码是否合法,使用pymysql 31 # 连接数据库 32 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='web') # db:库名 33 # 创建游标 34 cur = conn.cursor() 35 36 sql = "select * from userinfo where name = '%s'and password= '%s'" % (user, pwd) 37 38 cur.execute(sql) 39 # cur.fetchone()如果获取成功,就有值 40 if cur.fetchone(): 41 # 验证成功 42 data = "登陆成功".encode('gbk') 43 else: 44 # 验证失败 45 data = "登陆失败".encode('gbk') 46 47 return data 48 49 def fav(environ): 50 with open("templates/favicon.ico",'rb')as f: 51 data = f.read() 52 return data
1 # -*- coding:utf-8 -*- 2 # 作用:在数据库中创建表,运行程序生成表结构,这里我们直接在MySQL上插入了数据 3 # id | name | password | 4 # +----+------+----------+ 5 # | 1 | lilz | 123 6 7 import pymysql 8 #连接数据库 9 conn = pymysql.connect(host='127.0.0.1',port= 3306,user = 'root',passwd='123',db='web') #db:库名 10 #创建游标 11 cur = conn.cursor() 12 13 sql=''' 14 create table userinfo( 15 id INT PRIMARY KEY , 16 name VARCHAR(32) , 17 password VARCHAR(32) 18 ) 19 20 ''' 21 cur.execute(sql) 22 23 #提交 24 conn.commit() 25 #关闭指针对象 26 cur.close() 27 #关闭连接对象 28 conn.close()
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>Title</title> 6 </head> 7 <body> 8 9 <form action="http://127.0.0.1:8000/auth" method="post"> 10 用户名:<input type="text" name="user"> 11 密码:<input type="password" name="pwd"> 12 <input type="submit"> 13 </form> 14 </body> 15 </html>
框架使用说明:
如果你想访问一个自己写的网页,第一,准备好html文件放在templates目录中,再url.py上列表中添加url与视图函数的对应关系;
第二,在views.py中添加视图函数。
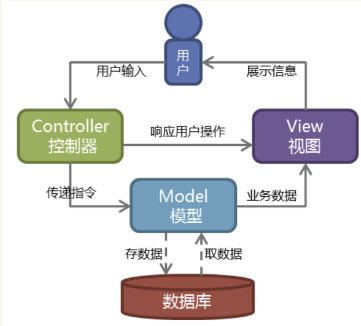
三:MVC架构
M:mdoel 与数据库打交道
C:controller 控制器(url的分发与视图函数的逻辑处理)
V:View 视图 (html文件,即用户界面)
Web服务器开发领域里著名的MVC模式,所谓MVC就是把Web应用分为模型(M),控制器(C)和视图(V)三层,他们之间以一种插件式的、松耦合的方式连接在一起,模型负责业务对象与数据库的映射(ORM),视图负责与用户的交互(页面),控制器接受用户的输入调用模型和视图完成用户的请求。这样强制性的使应用程序输入、处理和输出分开。
模型、视图、控制器的分离,使得一个模型可以有多种视图。如果用户通过某个视图的控制器改变了模型的数据,所有其他依赖于这些数据的视图都反映出这些变化。因此,无论何时发生了何种数据变化,控制器都会将变化通知给所有的视图,导致数据的更新。这就是一种模型的变化的传播机制。
四:MTV架构
Django的MTV模式本质上和MVC是一样的,也是为了各组件间保持松耦合关系,只是定义上有些许不同,Django的MTV分别是值:
- M 代表模型(Model): 负责业务对象和数据库的关系映射(ORM)。与数据库打交道
- T 代表模板 (Template):负责如何把页面展示给用户(html)。存放html文件(和MVC中的V的作用差不多)
- V 代表视图(View): 负责业务逻辑,并在适当时候调用Model和Template。
除了以上三层之外,还需要一个URL分发器,它的作用是将一个个URL的页面请求分发给不同的View处理,View再调用相应的Model和Template,MTV的响应模式如下所示

一般是用户通过浏览器向我们的服务器发起一个请求(request),这个请求回去访问视图函数,(如果不涉及到数据调用,那么这个时候视图函数返回一个模板也就是一个网页给用户),视图函数调用模型,模型去数据库查找数据,然后逐级返回,视图函数把返回的数据填充到模板中空格中,最后返回网页给用户。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号