

一:进程
1:创建多进程
方法一:常用的

1 import multiprocessing 2 3 #方式一 4 5 def task(arg): 6 7 print(arg) 8 9 if__name__=='__main__': 10 11 12 13 for i in range(10): 14 15 p=multiprocessing.Process(target=task,args=(i,)) 16 17 p.start() 18 19 20 21 #方式二: 22 23 def task(arg): 24 25 print(arg) 26 27 28 29 30 31 def run(): 32 33 for i in range(10): 34 35 p=multiprocessing.Process(target=task,args=(i,)) 36 37 p.start() 38 39 if __name__=='__main__': 40 41 run()
|

方法2:面向对象(继承)
1 import multiprocessing 2 3 class MyProcess(multiprocessing.Process): 4 5 def run(self): 6 7 print('当前进程',multiprocessing.current_process()) 8 9 10 11 def run(): 12 13 p1 = MyProcess() 14 15 p1.start() 16 17 18 19 p2 = MyProcess() 20 21 p2.start() 22 23 24 25 if __name__ == '__main__': 26 27 run() 28 29 # 当前进程 <MyProcess(MyProcess-1, started)> 30 31 # 当前进程 <MyProcess(MyProcess-2, started)> |
2:进程之间数据不共享
案例:
1 import multiprocessing 2 data_list = [] 3 4 def task(arg): 5 data_list.append(arg) 6 print(data_list) 7 8 def run(): 9 for i in range(3): 10 p = multiprocessing.Process(target=task,args=(i,)) 11 p.start() 12 13 if __name__ == '__main__': 14 run() 15 16 # [0] 17 # [1] 18 # [2]
|
3:常用方法
join/deamon/name/multiprocessing.current_process()/multiprocessing.current_process().ident/pid
1 import time 2 import multiprocessing 3 def task(arg): 4 p = multiprocessing.current_process() # 5 print(p.name) #获取进程名 6 print(p.ident) #获取进程id 7 print(p.pid) #获取进程id 8 9 time.sleep(2) 10 print(arg) 11 12 13 def run(): 14 print('111111111') 15 p1 = multiprocessing.Process(target=task,args=(1,)) 16 p1.name = 'pp1' #设置进程名 17 # p1.daemon = True # 让主线程不再等待子线程 18 p1.start() 19 20 print('222222222') 21 # p1.join()让主线程等待子线程 22 23
|
二:进程间的数据共享
进程之间的数据是不共享的,那么如何才能使得进程之间的数据共享呢?
方式一:Queue队列
1 import multiprocessing 2 3 import threading 4 5 import queue 6 7 8 9 q = multiprocessing.Queue() 10 11 12 13 def task(arg,q): 14 15 q.put(arg) 16 17 18 19 def run(): 20 21 for i in range(10): 22 23 p = multiprocessing.Process(target=task,args=(i,q,)) 24 25 p.start() 26 27 28 29 while True: 30 31 v = q.get() 32 33 print(v) 34 35 if __name__ == '__main__': #windows系统里需要加上此句,否则报错,Linux不用 36 37 run() |
方式二:Manager 字典
Linux
1 import multiprocessing 2 3 m = multiprocessing.Manager() 4 dic = m.dict() 5 6 def task(arg): 7 dic[arg] = 100 8 9 def run(): 10 for i in range(10): 11 p = multiprocessing.Process(target=task,args=(i)) 12 p.start() 13 14 input('>>>') 15 print(dic.values()) 16 17 |
windows
方式一:
1 import time 2 import multiprocessing 3 4 def task(arg,dic): 5 dic[arg] = 100 6 7 if __name__ == '__main__': 8 m = multiprocessing.Manager() 9 dic = m.dict() 10 for i in range(10): 11 p = multiprocessing.Process(target=task, args=(i,dic)) 12 p.start() 13 p.join() 14 15 print(dic.values()) 16 17 经过多次实际验证,主进程执行完毕后,子进程还在运行,那么,如果子进程用主进程的数据,由于主进程已经关闭, 18 所以就会找不就会报错。如何解决此报错问题呢?第一种方法就是让主进程等待所有子进程运行完毕之后在关闭, 19 第二种方法是就是在主进程中有一个循序,循环中判断进程存活的数量,如果子进程全关了,就退出循环,这样主进程就可以关闭了
|
方式二:
1 import time 2 import multiprocessing 3 4 def task(arg,dic): 5 dic[arg] = 100 6 if __name__ == '__main__': 7 m = multiprocessing.Manager() 8 dic=m.dict() 9 10 process_list = [] 11 for i in range(5): 12 p = multiprocessing.Process(target=task,args=(i,dic,)) 13 p.start() 14 15 process_list.append(p) 16 17 while True: 18 count = 0 19 for p in process_list: 20 if not p.is_alive(): #判断子进程是否存活 21 count+=1 22 if count == len(process_list): 23 break 24 print(dic) 25 26
|
方式三:数据共享更多用这种方式(伪代码)
|
def task(arg,dic): pass
if __name__ == '__main__': while True: # 连接上指定的服务器 # 去机器上获取url url = 'adfasdf' p = multiprocessing.Process(target=task, args=(url,)) p.start()
连接的获取方式:
|
三:进程锁
1:为什么要有进程锁?
因为进程在共享数据时,需要安全机制
2:案例:
1 import time 2 import threading 3 import multiprocessing 4 5 lock = multiprocessing.RLock() 6 def task(arg): 7 print('鬼子来了') 8 lock.acquire() 9 time.sleep(2) 10 print(arg) 11 lock.release() 12 13 14 if __name__ == '__main__': 15 p1 = multiprocessing.Process(target=task,args=(1,)) 16 p1.start() 17 18 p2 = multiprocessing.Process(target=task, args=(2,)) 19 p2.start() |
四:进程池
案例:
1 import time 2 from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor 3 def task(arg): 4 time.sleep(2) 5 print(arg) 6 7 if __name__ == '__main__': 8 pool = ProcessPoolExecutor(5) 9 for i in range(10): 10 pool.submit(task,i) |
五:爬虫模块(request/beautiful)
1:安装的方式
方式一:终端安装
|
pip3 install requests pip3 install beautifulsoup4 |
安装时遇到问题:
(1)找不到内部指令?
方式一:绝对路径安装
C:\Users\Administrator\AppData\Local\Programs\Python\Python36\Scripts\pip3 install requests
方式二:把此路径加入到sys.path里面
C:\Users\Administrator\AppData\Local\Programs\Python\Python36\Scripts
pip3 install requests
方式二:pycharm安装
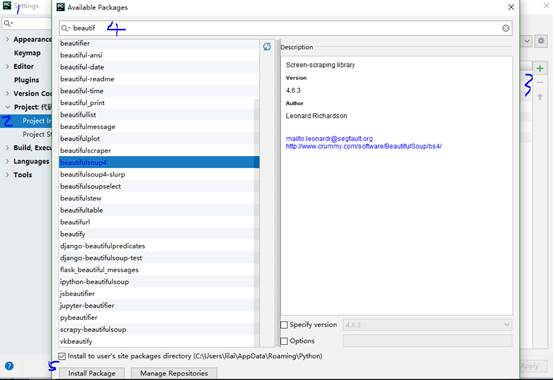
2:requests模块
1:作用:
模拟浏览器向服务器发请求
2:本质:
-创建socket客户端
-连接
-发送请求
-接收请求
-断开连接
3:案例:
1 import requests 2 # 模拟浏览器发送请求 3 4 # 内部创建 sk = socket.socket() 5 6 # 和抽屉进行socket连接 sk.connect(...) 7 8 # sk.sendall('...') 9 10 # sk.recv(...) 11 r1 = requests.get( 12 url='https://dig.chouti.com/', 13 headers={ 14 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36' 15 } 16 ) 17 print(r1.text) |
3:bs4
作用:以前爬取了网页需要正则来截取出来,而bs4就代替正则把数据截取出来
案例:
1 import requests 2 from bs4 import BeautifulSoup 3 from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor 4 5 6 # 模拟浏览器发送请求 7 # 内部创建 sk = socket.socket() 8 # 和抽屉进行socket连接 sk.connect(...) 9 # sk.sendall('...') 10 # sk.recv(...) 11 12 def task(url): 13 print(url) 14 r1 = requests.get( 15 url=url, 16 headers={ 17 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36' 18 } 19 ) 20 21 # 查看下载下来的文本信息 22 soup = BeautifulSoup(r1.text,'html.parser') #html.parser:截取的格式 23 print(soup.text) #content输出的是字节 24 content_list = soup.find('div',attrs={'id':'content-list'}) 25 for item in content_list.find_all('div',attrs={'class':'item'}): 26 title = item.find('a').text.strip() 27 target_url = item.find('a').get('href') 28 print(title,target_url) 29 30 def run(): 31 pool = ThreadPoolExecutor(5) 32 for i in range(1,50): 33 pool.submit(task,'https://dig.chouti.com/all/hot/recent/%s' %i) 34 35 36 if __name__ == '__main__': 37 run() 38 39
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号