

1 什么是正则?
匹配字符串内容的一种规则
在线测试工具 http://tool.chinaz.com/regex/
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。或者说:正则就是用来描述一类事物的规则。(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
2 正则表达式的作用
(1) 从大段的文字中找到符合规则的内容,如把一个文件中所有的手机号找出来。
一般在爬虫、日志分析中用的较多
(2) 判断某个字符串是否完全符合规则,如验证注册时输入的手机号是否合法,一般
在前端中网页注册中用的较多
3 正则表达式的规则
正则表达式只和字符串打交道
4 字符组
|
[0-9] |
匹配数字 |
|
[a-z] |
匹配小写字母 |
|
[A-Z] |
匹配大写字母 |
|
[a-zA-Z] |
匹配大小写字母 |
|
[a-zA-Z0-9] |
匹配大小写字母+数字 |
|
[a-zA-Z0-9_] |
匹配数字字母下滑线 |
|
[0-9a-fA-F] |
可以匹配数字,大小写形式的a~f,用来验证十六进制字符 |
5 元字符
|
\w |
匹配数字字母下划线 ,word关键字 [a-zA-Z0-9_] |
|
\W(大写) |
匹配非数字字母下划线 |
|
\d |
匹配所有的数字 digit [0-9] |
|
\D(大写) |
匹配所有的非数字 |
|
\s |
匹配所有的空白符 换行符、 制表符 、空格 space [\n\t ] |
|
\S(大写) |
匹配任意非空字符 |
|
\b |
表示单词的边界(一个单词结尾的、开头的) |
|
\t |
匹配tab制表符 |
|
\n |
匹配换行符 |
|
^ |
匹配一个字符串的开始 |
|
$ |
匹配一个字符串的结尾 |
|
. |
表示匹配除了换行符之外的所有字符 |
|
a|b |
匹配字符a或字符b |
|
() |
分组 表示给几个字符加上量词约束的需求的时候,就给这些量词分在一个组 |
|
[...] |
匹配字符组中的字符 |
|
[^...] |
匹配除了字符组中字符的所有字符 有一些特殊意义的元字符进入字符组里就会恢复本来的意义:(: . | [ ] ( ) ) |
|
\A |
匹配字符串开始 |
|
\Z |
匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串 |
|
\z |
匹配字符串结束 |
|
\G |
匹配最后匹配完成的位置 |
放在字符组中的元字符会现原形( ) . | ? + * - 号在中括号中有特殊意义,需要转义
6 量词
|
{n} |
表示 这个量词之前的字符出现n次 |
|
{n,} |
表示这个量词之前的字符至少出现n次 |
|
{n,m}: |
表示这个量词之前的字符出现n-m次 |
|
? |
表示匹配量词之前的字符出现0次或1次,表示可有可无 |
|
+ |
表示匹配量词之前的字符出现1次或多次 |
|
* |
表示匹配量词之前的字符出现0次或多次 |
7 转义符
如果有特殊意义,加上转义,就会去掉特殊意义,如果没有特殊意义,加上转义,就有特殊意义
8 正则表达式的贪婪与惰性
8.1 贪婪性
会在允许的范围内取最长的结果
所谓贪婪性,就是从头到尾匹配所有满足条件的,然后匹配到尾后在回溯会想要匹配的最后一个数,这样看的结果,实际上前面所有的满足条件的都在最后的结果里,这就是贪婪性
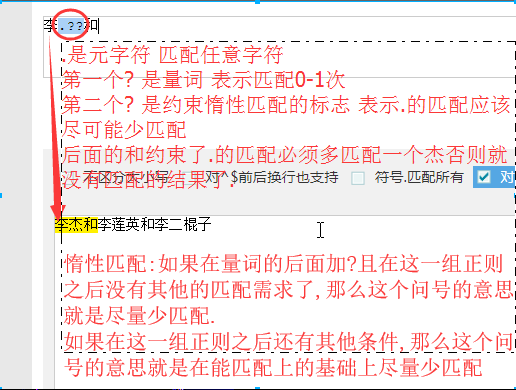
8.2 惰性
非贪婪模式/惰性匹配:在量词的后面加上?
例子:
.*?x 匹配任意非换行符字符任意长度 直到遇到x就停止

可以参考:http://www.cnblogs.com/Eva-J/articles/7228075.html的正则部分

 浙公网安备 33010602011771号
浙公网安备 33010602011771号