大数据
hadoop对于离线业务处理的流程:
flume数据采集-->spark计算-->结果存入Hbase
-->Hive的mapreduce统计、分析、清洗-->结果存入Hive表-->Sqoop同步/导出-->Mysql数据库-->WEB展示
- flume 说明
- Agent: 一个独立的Flume进程,包含组件Source、 Channel、 Sink。(Agent使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含 多个sources和sinks。
![]()
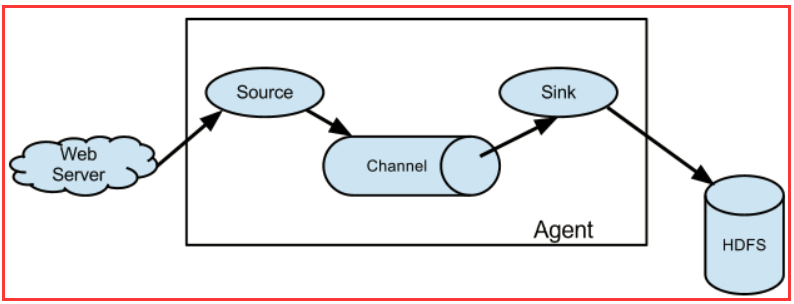
hadoop对于离线业务处理的流程:
flume数据采集-->spark计算-->结果存入Hbase
-->Hive的mapreduce统计、分析、清洗-->结果存入Hive表-->Sqoop同步/导出-->Mysql数据库-->WEB展示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号