
第四次作业
第四次作业
作业1
1.作业要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
代码如下:
items.py
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
price = scrapy.Field()
pipelines.py
import pymysql
class DangdangPipeline(object):
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",passwd = "2643097212", db = "mydb", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "本书籍")
def process_item(self, item, spider):
try:
''''
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
'''
if self.opened:
self.cursor.execute("insert into books (bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values( %s, %s, %s, %s, %s, %s)",(item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
self.count += 1
except Exception as err:
print(err)
return item
mySpider.py
import scrapy
from dangdang.items import DangdangItem
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider"
key = 'python'
source_url='http://search.dangdang.com/'
def start_requests(self):
url = MySpider.source_url+"?key="+MySpider.key
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price =li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date =li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
# detail有时没有,结果None
item = DangdangItem()
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item
# 最后一页时link为None
link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
if link:
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
settings.py
ITEM_PIPELINES = {
'dangdang.pipelines.DangdangPipeline': 300,
}
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())
输出结果

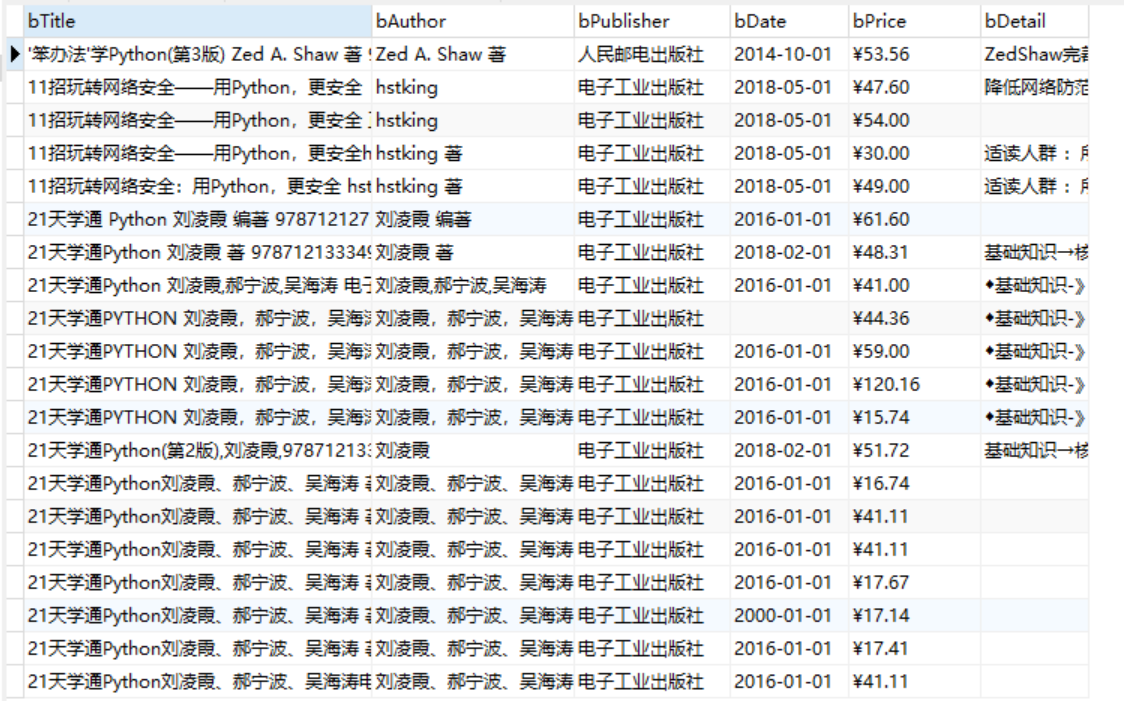
2.作业心得
!!!此次实验,在我艰难的下载好数据库后,满心欢喜的复制进去老师的代码,本以为就这样简单的复现就可以结束了实验,结果出现了一堆问题,放上问题和解决方案,给大家避个雷
问题有:

在一番上网百度后,大致了解是关于数据库的1366问题
解决办法有:
- 检查数据库此字段的字符集与整理字符集是否与SQL语句传递数据的字符集相同;不相同则会引发MySQL1366错误。
- 修改MySQL该字段的字符集与整理规则即可
用于检查的命令有:
- 检查数据表所有字段的状态
->show full columns from books; - 发现bTitle字段的Collation项非utf8,修改它!
->alter table books change name name varchar(100) character set utf8 collate utf8_unicode_ci not null default '';
而我更暴力,直接对整个数据库修改:
这个问题困扰了一早上!!最终在舍友+大佬的帮助下,成功修改好,希望以后更注意这种编码问题!!!
作业2
1.作业要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
方法一:
items.py
import scrapy
class BaidustocksItem(scrapy.Item):
count=scrapy.Field()
# define the fields for your item here like:
Number = scrapy.Field() # 股票代码
Name = scrapy.Field() # 股票名称
Last = scrapy.Field() # 最新报价
Up = scrapy.Field() # 涨跌幅
Down = scrapy.Field() # 涨跌额
Money_number = scrapy.Field() # 成交量
Money = scrapy.Field() # 成交额
Up_number = scrapy.Field() # 振幅
High = scrapy.Field() # 最高
Low = scrapy.Field() # 最低
Open = scrapy.Field() # 今开
closed = scrapy.Field() # 昨收
pipelines.py
import pymysql
class BaidustocksPipeline(object):
count = 0
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",passwd = "2643097212", db = "mydb", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened = True
self.count = 1
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "条记录")
def process_item(self, item, spider):
try:
if self.opened:
self.cursor.execute("insert into stocks1 (id, number,name,Last,up,down, moneynumber , money, up_number, high, low, open, closed) values( %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)",(self.count,item['Number'], item['Name'], item['Last'], item['Up'], item['Down'], item['Money_number'], item['Money'], item['Up_number'], item['High'], item['Low'], item['Open'], item['closed']))
self.count += 1
except Exception as err:
print(err)
return item
SSpider.py
import scrapy
from BaiduStocks.items import BaidustocksItem
import re
import requests
class SSpider(scrapy.Spider):
name = 'SSpider'
def start_requests(self):
global count
count=0
fs = {
"沪深A股": "m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23",
"上证A股": "m:1+t:2,m:1+t:23",
"深证A股": "m:0+t:6,m:0+t:13,m:0+t:80",
"新股": "m:0+f:8,m:1+f:8",
"中小板": "m:0+t:13",
"创业板": "m:0+t:80",
"科技版": "m:1+t:23"
}
# 设置要爬取的页数
for page in range(1,6):
for i in fs.keys():
url1 = "http://47.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112402742908388997074_1604226907915&pn=" + str(page)
url2="&pz=20&po=0&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f12&fs=" + fs[i] + "&fields=f12,f14,f2,f3,f4,f5,f6,f7,f15,f16,f17,f18"
url=url1+url2
yield scrapy.Request(url=url, callback=self.parse)
def parse(self,response):
global count
try:
url=response.url
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36"}
r = requests.get(url, headers=header)
pat = '"diff":\[\{(.*?)\}\]'
data = re.compile(pat, re.S).findall(r.text)
datas = data[0].split("},{") # 根据得到的字符串进行切片
for i in range(len(datas)):
datas1 = datas[i].split(",")
item=BaidustocksItem()
item["Number"] = eval(datas1[6].split(":")[1])
item["Name"] = eval(datas1[7].split(":")[1])
item["Last"] = eval(datas1[0].split(":")[1])
item["Up"] = eval(datas1[1].split(":")[1])
item["Down"] = eval(datas1[2].split(":")[1])
item["Money_number"] = eval(datas1[3].split(":")[1])
item["Money"] = eval(datas1[4].split(":")[1])
item["Up_number"] = eval(datas1[5].split(":")[1])
item["High"]=eval(datas1[8].split(":")[1])
item["Low"] = eval(datas1[9].split(":")[1])
item["Open"] = eval(datas1[10].split(":")[1])
item["closed"] = eval(datas1[11].split(":")[1])
yield item
except Exception as err:
print(err)
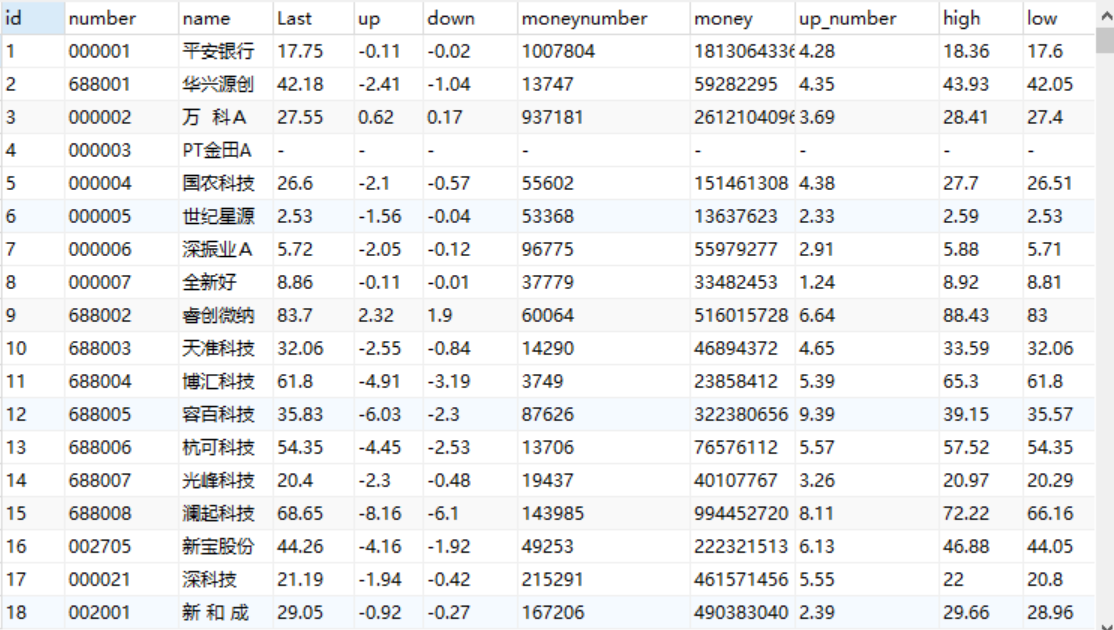
结果截图:
这个结果是在当前页面按了代码排序之后爬取的

方法二:看到其他同学使用selenium的方法加XPATH实现(转专业的同学伤不起,作业真的太多了,在这里留个位置,下次实验补上第二种方法!!!)
2.作业心得
此次实验,,方法一并没有使用xpath,只是将上次的代码修改了pipslines,在数据库中保存,就这样简简单单的操作,还是遇到了一个小麻烦,就是mysql自动排序导致存储在数据库中的数据变成按照股票号码从小到大排序,最后还是选择插入新的一列id,避免掉这个默认排序,也算是一个小小的注意事项,这里给出我查找到的资料————关于这个默认排序的解释mysql默认排序问题
作业3
1.作业要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
设计思路:
f12查看所要求爬取的网页:
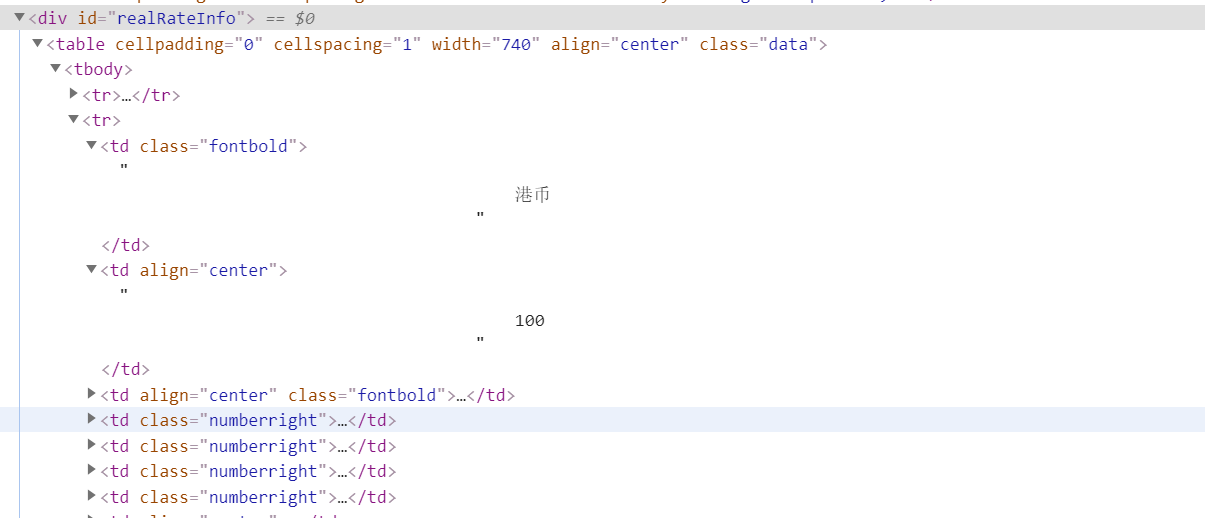
发现我们要爬取的信息都在如下的标签下

根据位置设计xpath的路径(其他数据的位置也很好找,就不一一指出相应的位置)
代码如下
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class StockItem(scrapy.Item):
Currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
Time = scrapy.Field()
pipslines.py
import pymysql
class StockPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="2643097212", db="mydb",charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from money")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "种外汇")
def process_item(self, item, spider):
try:
print(item["Currency"])
print(item["TSP"])
print(item["CSP"])
print(item["TBP"])
print(item["CBP"])
print(item["Time"])
print()
if self.opened:
self.cursor.execute("insert money(Number,Currency,TSP,CSP,TBP,CBP,Time) values (%s,%s,%s,%s,%s,%s,%s)",(self.count, item["Currency"], item["TSP"], item["CSP"], item["TBP"], item["CBP"], item["Time"]))
self.count += 1
except Exception as err:
print(err)
return item
setting.py
ITEM_PIPELINES = {
'stock.pipelines.StockPipeline': 300,
}
zllspider.py
import scrapy
from stock.items import StockItem
from bs4 import UnicodeDammit
class zllspider(scrapy.Spider):
name = "zllspider"
source_url='http://fx.cmbchina.com/hq/'
def start_requests(self):
url = zllspider.source_url
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector=scrapy.Selector(text=data)
lines=selector.xpath("//div[@id =\"realRateInfo\"]//tr")
#print(lines.extract())
# 为了防止爬取了表头导致的一开始为none
for line in lines[1:]:
# 如果不用extract_first()最后不能对列表进行切割
Currency = line.xpath("./td[@class =\"fontbold\"]/text()").extract_first()
TSP = line.xpath("./td[@class =\"numberright\"][1]/text()").extract_first()
CSP = line.xpath("./td[@class =\"numberright\"][2]/text()").extract_first()
TBP=line.xpath("./td[@class =\"numberright\"][3]/text()").extract_first()
CBP=line.xpath("./td[@class =\"numberright\"][4]/text()").extract_first()
Time=line.xpath("./td[@align =\"center\"][3]/text()").extract_first()
item=StockItem()
item["Currency"]=Currency.strip() if Currency else ""
item["TSP"] = TSP.strip() if TSP else ""
item["CSP"] = CSP.strip() if CSP else ""
item["TBP"] = TBP.strip() if TBP else ""
item["CBP"] = CBP.strip() if CBP else ""
item["Time"] = Time.strip() if Time else ""
yield item
except Exception as err:
print(err)
结果截图:
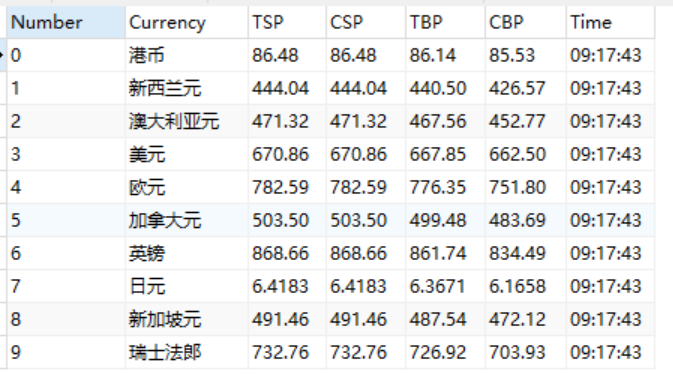

2.作业心得
该次实验比较容易,就是分析网页后,依据xpath定位,获得我们需要的数据,存储进入数据库,在实验过程中出现了各种小小的问题,还是花费了较多的时间,总结几个小坑
出现问题1(没有认真查看网页html中标签下我们要爬取的具体位置):

爬取的数据第一行都为None,一开始以为是爬取的定位出现了问题,,打开网页F12分析之后,发现是爬取了表头

所以在设置循环时应该从第二个元素开始:
for line in lines[1:]:
出现问题2:

实验xpath中的extract方法时,返回的是列表,要使用的是extract_first()!细心!
总结
- 发现自己一个坏毛病了,就是在熟悉爬取后,开始懒得去认真分析一个网页,而是想把模板先写一下,然后改一改,就成了,这次!因为第一题耗费时间长,做到第二题的时候,股票网站的URL都改了!!!没有及时查看网站的URL,(改了很久都不理解为啥爬不下来),以后还是得改掉这个
坏毛病 - 熟悉了XPATH+SCRAPY+MySQL框架的运用,在数据库连接也踩了坑,实验虽简单但是遇到的坑还不少(是我太菜了~)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号