大模型微调概念梳理
1. 微调方式
- 全参数微调(Full Fine-Tuning, FFT):调节大模型的全部参数,需要微调样本数据量充足,计算资源充足的情况下
- ✅适用于复杂任务
- ❌容易过拟合,计算成本高
- 参数高效微调(Parameter-Efficient Fine-Tuning, PEFT):调节大模型的部分参数
- ✅计算开销低
- ✅大部分场景下足够了
- 不同类型的PEFT训练方法对不同任务有偏好
- ❌可能引入额外推理延迟
1.1. PEFT常见技术
- LoRA(Low-Rank Adaptation)
- QLoRA(Quantized LoRA)
- Adapter Tuning
- Prefix Tuning / Prompt Tuning
- CRFT(关键表示微调)
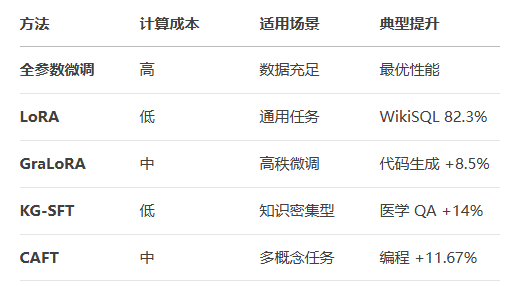
2. 微调工具&框架
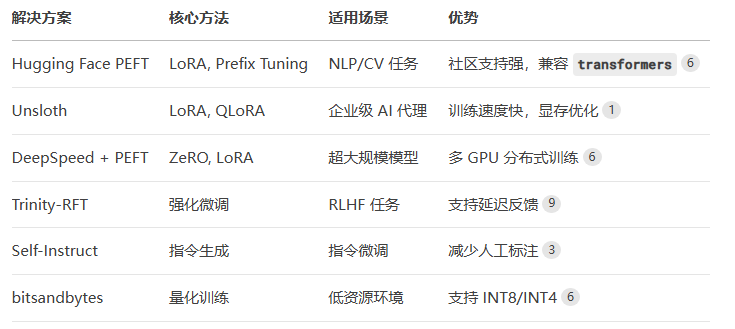
3. 常见类库介绍
- PyTorch:提供神经网络构建的基础设施(如张量计算、自动求导等),是ML领域流行的通用库(对标Tensorflow)
- transformers:HuggingFace推出,提供预训练模型的加载、推理和微调
- peft:HuggingFace推出,提供LoRA、Adapter等各种PEFT微调工具
- bitsandbytes:压缩模型权重至4/8bit,减少显存占用
- accelerate:简化多GPU/TPU训练和推理的代码编写
4. 我应该准备什么样的数据格式
首先,大语言模型对你输入的微调数据没有任何结构化要求,你可以输入任意纯文本。
但通常,微调场景是为了让模型对于某些固定的问题有着较为精确的回答,所以通常具有如下通用格式
4.1. QA对
QA对通常是一个问题一个回答的集合,格式通常是:
[
{
"question": "xxxxxxxx",
"answer": "yyyyyyy"
}
]
注意:所有这些结构化的数据最终给模型进行微调时都会转换成非结构化的文本,如上面可能会转化成:“你是一个问答助手,问题:xxxxxx,回答:yyyyyyy”
4.2. 指令微调
考虑多语言翻译场景,qa对是不够的,可以使用如下格式:
[
{
"instruction": "将下面的中文翻译成英文",
"input": "你好",
"output": "hello"
}
]
4.3. 对话微调
在客服场景,通常会用如下格式:
[
{
"dialogue": [
{
"role": "system",
"content": "aaaa"
},
{
"role": "user",
"content": "xxx"
},
{
"role": "assistant",
"content": "yyy"
}
]
}
]
4.4. 文本分类
...
4.5. 领域适配
...
4.6. 推理模型微调
...
5. 微调数据如何获取
- 人工准备
- 代码清洗
- 基于LLM清洗
- firecrawl可以爬取任意网页,转换成大模型友好的markdown和json
- 基于firecrawl爬取的内容,编写脚本让大模型执行数据清洗
- 对大模型清洗后的脚本进行二次代码清洗
6. 实例
6.1. 异度之刃2知识库
用户可能提出任何关于游戏《异度之刃2》的问题,比如“神八的牵绊圆环如何解锁3阶”,知识库需要能够给出精准的回答
- 利用firecrawl爬取 乐园数据管理室 的异刃数据,保存为markdown
- 使用LLM,基于这些markdown提取问答对
- 清洗这些问答对至结构化数据
- 大模型微调
6.2. AI SQL Editor
对于AI SQL编辑器场景,光有表结构、字段注释等信息远远不能精准生成SQL代码,还需要PRD、代码等信息
- 从PRD、代码库中提取信息(如何提取?有没有现存方案)
- 提取出什么信息?
- AI SQL编辑器需要什么信息?
- 哪些信息是结构化的?
- 清洗信息
- 微调

 浙公网安备 33010602011771号
浙公网安备 33010602011771号