SparkPaper RDD:一个内存集群计算的可容错抽象
本文是Spark论文的翻译,并非通篇翻译,只摘了关键部分帮助更好的理解Spark是什么,架构如何设计。
原文:Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
摘要
是什么:RDD(Resilient Distributed Datasets 弹性分布式数据集)是一个分布式内存抽象,用于以可容错的方式在大集群上执行内存计算。
主要动机:当前的计算框架(译者:当时应该不常见内存计算框架)有两种无法高效处理的情况,迭代算法以及交互式数据挖掘工具。而在这些情况下,将数据存到内存里可以将性能提升几个数量级。
和Spark的关系:RDD是一个抽象概念,Spark是其具体实现。
介绍
动机:提供可用于广大范围的,可以实现高效数据重用的抽象——RDD
- 当前计算框架(如MapReduce)对那些多轮计算需要重用数据的情况不友好,若重用,需使用分布式存储,带来的额外开销比计算本身还大
- 即使有了一些重视重用的计算框架(Pregel、HaLoop),但大都是处理特定问题。
数据粒度:
- 现存的内存存储集群通常提供一个细粒度的接口以变更状态,这种情况下,容错的唯一途径就是在多台机器上保存数据的副本或更新日志,对于数据密集型负载这是昂贵的
- RDD提供了基于粗粒度转换(transformation)的接口(例如、map、filter以及join),它们对于大量数据应用相同的操作。这允许我们可以存储用于构建dataset(lineage 血统)的这些转换的日志来高效实现容错,而非实际数据。
- 如果RDD的一个部分丢失,RDD具有足够的信息,知道它是从哪个其它RDD派生出来的,并重计算这个丢失的分区
译者:说白了,就是将整体数据分块,然后只给几种操作类型,每一块都是从其它块应用一种操作计算出来的,这样,某一块丢失,可以基于其血缘关系直接计算出来(最初的块丢失咋办?)
通用性:RDD可以高效表达现存多种集群编程模型可以做的,如MapReduce、DryadLINQ、SQL、Pregel和HaLoop,对于一些这些系统无法做到的,RDD也可以做到(如交互式数据挖掘)
Resilient Distributed Datasets(RDDs)
RDD抽象
RDD定义:一个只读的,分区的记录集合
创建方式:只有两种
- 通过在稳定存储上的数据
- 通过其它RDDs派生。和RDD上的其它操作不同,能够派生RDD的操作称作transformations(map、join、filter)
无需物化:RDD在任何时候都不需要物化,它具有足够的关于它从何派生而来的(血缘)信息,这些信息来自稳定存储
额外控制:用户可以控制RDD的持久性和分区。
- 用户可以指定哪些RDD需要被重用,并且为它们选择存储策略
- 用户可以指定RDD元素基于每个record上的一个key来在多个机器上分区
Spark编程接口
- Spark将RDD作为一个对象暴露出去,transformation是对象上的方法
- 程序员从对稳定存储中的数据进行转换来定义一个或多个RDD
- 可以将RDD用在action中,action是一个操作,这个操作将给应用程序返回值,或将数据导出到存储系统。action的例子:
count:返回dataset中的元素数量collect:返回元素本身save:将dataset输出到存储系统
- Spark的RDD计算是lazy的,只有当RDD被应用到action中才会计算,所以它可以流水线化转换
- Spark默认在内存中持久化RDD,但当空间不足时,它会将其溢出到磁盘中。用户可以通过
persist方法来指明某一个RDD会在未来被重用(译者:或许是说可以pin在内存?) - 用户也可以通过
persist中的flag,选择其它持久化策略,如只在磁盘上或在多个机器间备份 - 用户可以给每一个RDD设置一个持久化优先级,指定哪些内存数据将先被溢出到磁盘

示例:控制台日志挖掘
假设web服务大量error,维护人员想要从HDFS上的TB级的日志中找到原因。使用Spark,维护人员只需将错误信息从日志中加载到一系列节点的RAM中,然后交互式的查询它们。她首先会打下下面的Scala代码:

- 定义了一个背后是HDFS文件的RDD
- 派生一个过滤后的RDD
- 请求将errors在内存中持久化,以让其可以在查询间共享
至此,尚未有任何工作实际执行了,用户现在可以将RDD用到action中,比如计算消息数量:

用户也可以进一步在RDD上执行转换:

为了描述我们的模型如何达到容错,我们给出了血缘图:
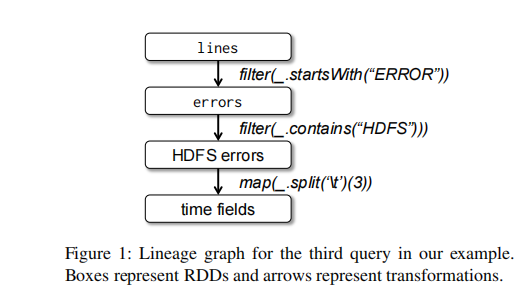
我们从errors开始,它是lines的过滤结果,然后,我们应用了filter和map。Spark调度器将流水线化后两个转换,给持有errors的缓存分区的节点发送一系列任务来计算它们。如果分区errors的一个分区丢了,Spark将通过只在lines的对应分区上重新应用filter来重建它。
不适用于RDD的应用
RDD最适用于在dataset的所有元素上应用相同操作的批量程序,不适用于那些需要对共享状态做异步细粒度更新的应用,如web应用的存储系统或步进式的web爬虫。
表示RDDs
提供RDD抽象的一个挑战是:选择一个可以在大量的转换间跟踪血缘的一个表示形式
理想情况下,实现RDDs的系统应该尽可能提供一组丰富的转换操作,让用户以任何方式组织它们。我们提出了一种简单的,基于图的RDD表示方法来达到这些目标,且在Spark中用于支持大量的转换而不需要在调度器中为每一个添加特殊的逻辑。
简言之,我们决定通过一个通用接口来暴露出五块信息:
- 一系列分区——即dataset的原子块
- 一系列父RDD的依赖
- 一个用于根据其父级来计算dataset的函数(transformations)
- 关于它分区模式以及数据定位的信息
一个有趣的问题是,如何表示RDD之间的依赖,我们发现将依赖关系分为两种类型是足够且好用的:
- 窄依赖(narrow dependencies):每一个parent RDD的分区,最多只被一个child RDD的分区依赖(如map)
- 宽依赖(wide dependencies):多个子分区可能依赖同一个父分区(如join,除非父节点已经被hash分区了)

这个区别有用,有两个原因:
- 窄依赖允许在一个集群节点上流水线执行,该节点可以计算所有的父分区(如,它可以在元素级别执行一个
map,然后跟着一个filter) - 相反,宽依赖需要所有的父分区都可用,并且需要在节点间使用类似MapReduce形式的shuffle操作
- 窄依赖在节点失效时能更高效的恢复,因为只有丢失的parent分区需要被重新计算,并且可以在不同节点上并行计算
- 宽依赖的一个失效节点可能导致一个RDD的所有祖先的部分分区失效,需要完整的重执行
译者:没太理解...
实现
未完...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号