
【python爬虫课程设计】去哪儿旅游网--数据爬取+数据分析
一、选题的背景
在当今社会,人们的生活质量越来越高,精神的需求也随之提升。在忙碌的工作日之后,假期的去出也是人们思考的问题,去哪?怎么去?从而诞生了许多旅游攻略网。琳琅满目的标题与页面看的眼花缭乱,通过爬取关键的信息,集合分析数据从而得到了大多数人最优解方案,以达到便利,供人参考的目的。
二、主题式网络爬虫设计方案
首先爬取URL分页数据储存进txt,再读取txt爬取每个分页的页面信息存入csv,使用BeautifulSoup库解析获取到的网页内容,提取所需的信息,如地点、简介、出发时间、天数、人均费用、人物、玩法和浏览量等。最后使用pandas库对文件进行分析和数据可视化。
技术难点:一些网页的不规范原因,一些地名无法抓取
三、主题页面的结构特征分析
1.主题页面的结构与特征分析

可以看出关键的日期,费用等信息都是在顶部一个列表中显示
2.Htmls 页面解析
关键的信息都被包含在class,ul和li中,发现只需抓取某些关键字段即可,如:出发日期、天数、人均消费、人物、玩法等,但由于某些网页的不规范原因,一些地名无法抓取,所以用攻略代替。
3.节点(标签)查找方法与遍历方法
find查找,for循环遍历
四、网络爬虫程序设计
爬取每篇分页的URL存入url_1,再爬取分页中的内容存入Travel_first.csv中,用于生成饼图的评论存入travel_text


import requests
from bs4 import BeautifulSoup
import re
import time
import csv
import random
#爬取每个网址的分页
fb = open(r'url_1.txt','w')
url = 'http://travel.qunar.com/travelbook/list.htm?page={}&order=hot_heat&avgPrice=1_2'
#请求头,cookies在电脑网页中可以查到
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.360',
'cookies':'JSESSIONID=5E9DCED322523560401A95B8643B49DF; QN1=00002b80306c204d8c38c41b; QN300=s%3Dbaidu; QN99=2793; QN205=s%3Dbaidu; QN277=s%3Dbaidu; QunarGlobal=10.86.213.148_-3ad026b5_17074636b8f_-44df|1582508935699; QN601=64fd2a8e533e94d422ac3da458ee6e88; _i=RBTKSueZDCmVnmnwlQKbrHgrodMx; QN269=D32536A056A711EA8A2FFA163E642F8B; QN48=6619068f-3a3c-496c-9370-e033bd32cbcc; fid=ae39c42c-66b4-4e2d-880f-fb3f1bfe72d0; QN49=13072299; csrfToken=51sGhnGXCSQTDKWcdAWIeIrhZLG86cka; QN163=0; Hm_lvt_c56a2b5278263aa647778d304009eafc=1582513259,1582529930,1582551099,1582588666; viewdist=298663-1; uld=1-300750-1-1582590496|1-300142-1-1582590426|1-298663-1-1582590281|1-300698-1-1582514815; _vi=6vK5Gry4UmXDT70IFohKyFF8R8Mu0SvtUfxawwaKYRTq9NKud1iKUt8qkTLGH74E80hXLLVOFPYqRGy52OuTFnhpWvBXWEbkOJaDGaX_5L6CnyiQPPOYb2lFVxrJXsVd-W4NGHRzYtRQ5cJmiAbasK8kbNgDDhkJVTC9YrY6Rfi2; viewbook=7562814|7470570|7575429|7470584|7473513; QN267=675454631c32674; Hm_lpvt_c56a2b5278263aa647778d304009eafc=1582591567; QN271=c8712b13-2065-4aa7-a70b-e6156f6fc216',
'referer':'http://travel.qunar.com/travelbook/list.htm?page=1&order=hot_heat&avgPrice=1'}
count = 1
#共200页
for i in range(1,201):
url_ = url.format(i)
try:
response = requests.get(url=url_,headers = headers)
response.encoding = 'utf-8'
html = response.text
soup = BeautifulSoup(html,'lxml')
#print(soup)
all_url = soup.find_all('li',attrs={'class': 'list_item'})
#print(all_url[0])
'''
for i in range(len(all_url)):
#p = re.compile(r'data-url="/youji/\d+">')
url = re.findall('data-url="(.*?)"', str(i), re.S)
#url = re.search(p,str(i))
print(url)
'''
print('正在爬取第%s页' % count)
for each in all_url:
each_url = each.find('h2')['data-bookid']
#print(each_url)
fb.write(each_url)
fb.write('\n')
#last_url = each.find('li', {"class": "list_item last_item"})['data-url']
#print(last_url)
time.sleep(random.randint(3,5))
count+=1
except Exception as e:
print(e)爬取的数据存在这个txt中

爬取页面关键字内容
import requests
from bs4 import BeautifulSoup
import re
import time
import csv
import random
url_list = []
with open('url_1.txt','r') as f:
for i in f.readlines():
i = i.strip()
url_list.append(i)
the_url_list = []
for i in range(len(url_list)):
url = 'http://travel.qunar.com/youji/'
the_url = url + str(url_list[i])
the_url_list.append(the_url)
last_list = []
def spider():
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.360',
'cookies': 'QN1=00002b80306c204d8c38c41b; QN300=s%3Dbaidu; QN99=2793; QN205=s%3Dbaidu; QN277=s%3Dbaidu; QunarGlobal=10.86.213.148_-3ad026b5_17074636b8f_-44df|1582508935699; QN601=64fd2a8e533e94d422ac3da458ee6e88; _i=RBTKSueZDCmVnmnwlQKbrHgrodMx; QN269=D32536A056A711EA8A2FFA163E642F8B; QN48=6619068f-3a3c-496c-9370-e033bd32cbcc; fid=ae39c42c-66b4-4e2d-880f-fb3f1bfe72d0; QN49=13072299; csrfToken=51sGhnGXCSQTDKWcdAWIeIrhZLG86cka; QN163=0; Hm_lvt_c56a2b5278263aa647778d304009eafc=1582513259,1582529930,1582551099,1582588666; viewdist=298663-1; uld=1-300750-1-1582590496|1-300142-1-1582590426|1-298663-1-1582590281|1-300698-1-1582514815; viewbook=7575429|7473513|7470584|7575429|7470570; QN267=67545462d93fcee; _vi=vofWa8tPffFKNx9MM0ASbMfYySr3IenWr5QF22SjnOoPp1MKGe8_-VroXhkC0UNdM0WdUnvQpqebgva9VacpIkJ3f5lUEBz5uyCzG-xVsC-sIV-jEVDWJNDB2vODycKN36DnmUGS5tvy8EEhfq_soX6JF1OEwVFXk2zow0YZQ2Dr; Hm_lpvt_c56a2b5278263aa647778d304009eafc=1582603181; QN271=fc8dd4bc-3fe6-4690-9823-e27d28e9718c',
'Host': 'travel.qunar.com'
}
count = 1
for i in range(len(the_url_list)):
try:
print('正在爬取第%s页'% count)
response = requests.get(url=the_url_list[i],headers = headers)
response.encoding = 'utf-8'
html = response.text
soup = BeautifulSoup(html,'lxml')
information = soup.find('p',attrs={'class': 'b_crumb_cont'}).text.strip().replace(' ','')
info = information.split('>')
if len(info)>2:
location = info[1].replace('\xa0','').replace('旅游攻略','')
introduction = info[2].replace('\xa0','')
else:
location = info[0].replace('\xa0','')
introduction = info[1].replace('\xa0','')
#爬取内容
other_information = soup.find('ul',attrs={'class': 'foreword_list'})
when = other_information.find('li',attrs={'class': 'f_item when'})
time1 = when.find('p',attrs={'class': 'txt'}).text.replace('出发日期','').strip()
howlong = other_information.find('li',attrs={'class': 'f_item howlong'})
day = howlong.find('p', attrs={'class': 'txt'}).text.replace('天数','').replace('/','').replace('天','').strip()
howmuch = other_information.find('li',attrs={'class': 'f_item howmuch'})
money = howmuch.find('p', attrs={'class': 'txt'}).text.replace('人均费用','').replace('/','').replace('元','').strip()
who = other_information.find('li',attrs={'class': 'f_item who'})
people = who.find('p',attrs={'class': 'txt'}).text.replace('人物','').replace('/','').strip()
how = other_information.find('li',attrs={'class': 'f_item how'})
play = how.find('p',attrs={'class': 'txt'}).text.replace('玩法','').replace('/','').strip()
Look = soup.find('span',attrs={'class': 'view_count'}).text.strip()
if time1:
Time = time1
else:
Time = '-'
if day:
Day = day
else:
Day = '-'
if money:
Money = money
else:
Money = '-'
if people:
People = people
else:
People = '-'
if play:
Play = play
else:
Play = '-'
last_list.append([location,introduction,Time,Day,Money,People,Play,Look])
#设置爬虫时间
time.sleep(random.randint(2,4))
count+=1
except Exception as e :
print(e)
#写入csv
with open('Travel_first.csv', 'a', encoding='utf-8-sig', newline='') as csvFile:
csv.writer(csvFile).writerow(['地点', '短评', '出发时间', '天数','人均费用','人物','玩法','浏览量'])
for rows in last_list:
csv.writer(csvFile).writerow(rows)
if __name__ == '__main__':
spider()

wordcloud 的分词可视化
import jieba
import jieba.analyse
import re
punc = '~`!#$%^&*()_+-=|\';":/.,?><~·!@#¥%……&*()——+-=“:’;、。,?》《{}【】' # 定义需要去除的标点符号
def remove_fuhao(e):
short = re.sub(r"[%s]+" % punc, " ", e) # 使用正则表达式替换掉字符串中的标点符号
return short
def cut_word(text):
text = jieba.cut_for_search(str(text)) # 使用jieba进行分词
return ' '.join(text)
data2 = df
data2['简介'] = data2['短评'].apply(remove_fuhao).apply(cut_word)
data2.head(100) # 显示前100行数据
word = data2['简介'].values.tolist() # 将简介列转换为列表
fb = open(r'.\travel_text.txt','w',encoding='utf-8') # 以写入模式打开文件
for i in range(len(word)):
fb.write(word[i]) # 将每个简介写入文件
with open(r'.\travel_text.txt','r',encoding='utf-8')as f:
words = f.read()
f.close
jieba.analyse.set_stop_words(r'.\travel_text.txt') # 设置停用词表
new_words = jieba.analyse.textrank(words, topK=30, withWeight=True) # 使用jieba的textrank方法提取关键词
print(new_words) # 打印提取到的关键词及其权重
from pyecharts import WordCloud # 导入词云图库
word1 = []
num1 = []
for i in range(len(new_words)):
word1.append(new_words[i][0])
num1.append(new_words[i][1])
wordcloud=WordCloud('简介词云分析',width=600,height=400) # 创建词云对象
wordcloud.add('简介词云分析',word1,num1,word_size_range=[25,80],shape = 'diamond') # 添加词云数据
wordcloud.render("简介词云分析.html") # 渲染词云图并保存为HTML文件
数据分析与可视化
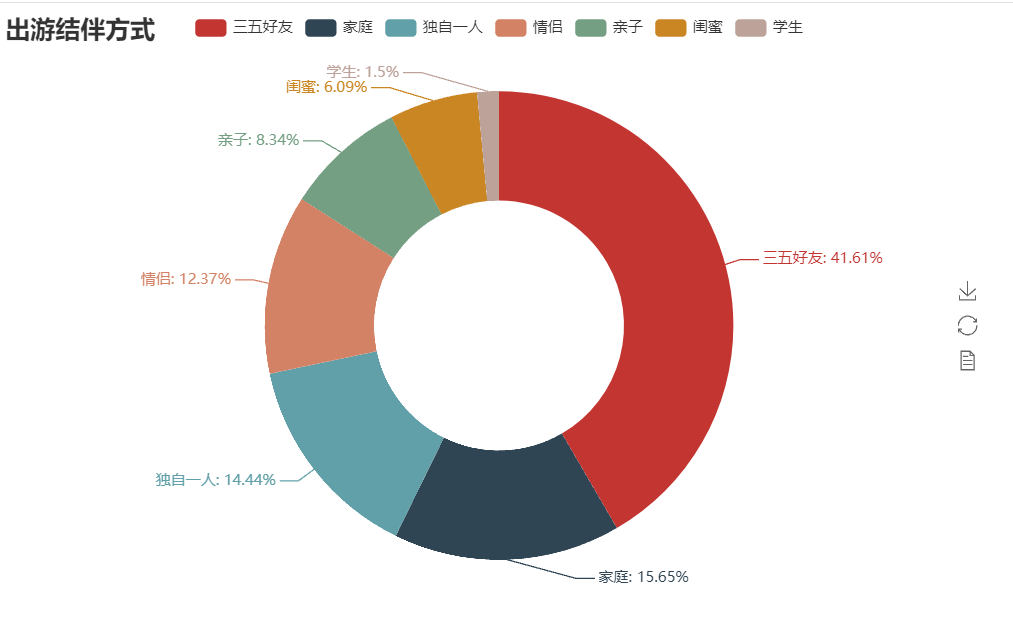
根据提取的关键字:人物,生成了出游结伴方式的饼图
import jieba
import jieba.analyse
import re
punc = '~`!#$%^&*()_+-=|\';":/.,?><~·!@#¥%……&*()——+-=“:’;、。,?》《{}【】' # 数据清洗,定义需要去除的标点符号
def remove_fuhao(e):
short = re.sub(r"[%s]+" % punc, " ", e) # 使用正则表达式替换掉字符串中的标点符号
return short
def cut_word(text):
text = jieba.cut_for_search(str(text)) # 使用jieba进行分词
return ' '.join(text) # 将分词结果用空格连接成字符串并返回
data2 = df
data2['简介'] = data2['短评'].apply(remove_fuhao).apply(cut_word) # 对短评进行处理,生成简介列
data2.head(100) # 显示前100行数据
word = data2['简介'].values.tolist() # 将简介列转换为列表
fb = open(r'.\travel_text.txt','w',encoding='utf-8')
for i in range(len(word)):
fb.write(word[i])
fb.close()
with open(r'.\travel_text.txt','r',encoding='utf-8')as f:
words = f.read()
f.close()
jieba.analyse.set_stop_words(r'.\travel_text.txt') # 设置停用词表为自定义的文件
new_words = jieba.analyse.textrank(words, topK=30, withWeight=True) # 使用jieba的textrank方法提取关键词,提取数量为30,返回权重值
print(new_words) # 打印提取到的关键词及其权重值
import pandas as pd
df = pd.read_csv('Travel_first.csv', encoding='gb18030')
df.info()
from pyecharts import Pie
m1 = df['人物'].value_counts().index.tolist() # 统计'人物'列中各个值出现的次数,并转换为列表
n1 = df['人物'].value_counts().values.tolist() # 统计'人物'列中各个值出现的次数,并将值转换为列表
pie = Pie('出游结伴方式', background_color='white', width=800, height=500, title_text_size=20) # 创建一个饼图对象,设置标题、背景颜色、宽度、高度和标题字体大小
pie.add('', m1, n1, is_label_show=True, is_legend_show=True, radius=[40, 75]) # 向饼图中添加数据,设置是否显示标签、图例和半径范围
pie.render('出行结伴方试.html')
通过遍历和获取地点和人均费用两个关键字生成了人均消费旅游地的数据柱形图
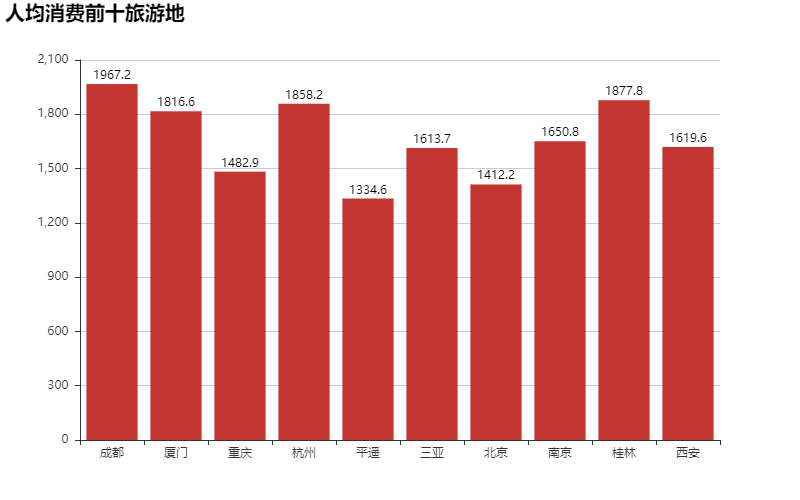
由图可以看出人们还是喜欢去大城市一点
通过通过获取出行年份关键字生成了2023的出游时间曲线图

from pyecharts import Line
m5 = m3['2023'].index
n5 = m3['2023'].values
# 对m3数据框中的'2023'列进行排序,并取最后10个值
m3['2023'].sort_values().tail(10)
# 创建一个Line对象,设置宽度为800,高度为500,标题字体大小为20
line2 = Line('出游时间曲线', width=800, height=500, title_text_size=20)
# 向Line对象中添加数据,设置图例显示为True
line2.add('', m5, n5, is_legend_show=True)
line2.render('出游时间曲线2023.html')有点意外,国庆节出行旅游这么少,难道大家都不愿意人挤人了吗。
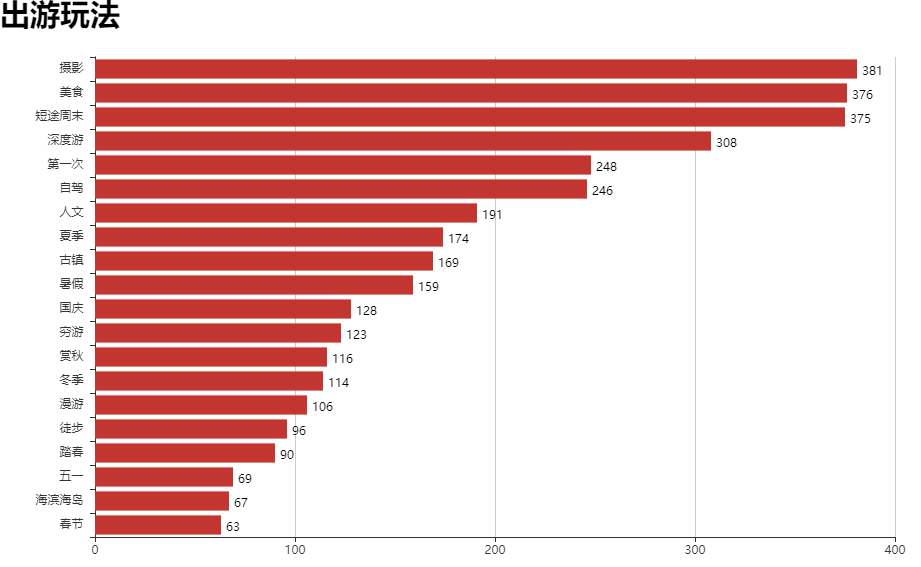
出游玩法直方图
m pyecharts import Line
for i in range(20):
m6.append(list[i][0])
n6.append(list[i][1])
# 反转m6和n6列表,使索引按照降序排列
m6.reverse()
n6.reverse()
# 复制m6和n6列表到m7和n7列表
m7 = m6[:]
n7 = n6[:]
# 创建出游玩法柱状图
bar = Bar('出游玩法', width=1000, height=600, title_text_size=30)
# 添加柱状图数据,设置是否显示标签、标签位置等属性
bar.add('', m7, n7, is_convert=True, is_label_show=True, label_pos='right')
# 渲染出游玩法柱状图为HTML文件
bar.render('出游玩法.html')
爬虫课程设计全部代码如下:
#爬取分页url
import requests
from bs4 import BeautifulSoup
import re
import time
import csv
import random
# part1 爬虫 + 持久化
fb = open(r'url_1.txt','w')
url = 'http://travel.qunar.com/travelbook/list.htm?page={}&order=hot_heat&avgPrice=1_2'
#请求头,cookies在电脑网页中可以查到
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.360',
'cookies':'JSESSIONID=5E9DCED322523560401A95B8643B49DF; QN1=00002b80306c204d8c38c41b; QN300=s%3Dbaidu; QN99=2793; QN205=s%3Dbaidu; QN277=s%3Dbaidu; QunarGlobal=10.86.213.148_-3ad026b5_17074636b8f_-44df|1582508935699; QN601=64fd2a8e533e94d422ac3da458ee6e88; _i=RBTKSueZDCmVnmnwlQKbrHgrodMx; QN269=D32536A056A711EA8A2FFA163E642F8B; QN48=6619068f-3a3c-496c-9370-e033bd32cbcc; fid=ae39c42c-66b4-4e2d-880f-fb3f1bfe72d0; QN49=13072299; csrfToken=51sGhnGXCSQTDKWcdAWIeIrhZLG86cka; QN163=0; Hm_lvt_c56a2b5278263aa647778d304009eafc=1582513259,1582529930,1582551099,1582588666; viewdist=298663-1; uld=1-300750-1-1582590496|1-300142-1-1582590426|1-298663-1-1582590281|1-300698-1-1582514815; _vi=6vK5Gry4UmXDT70IFohKyFF8R8Mu0SvtUfxawwaKYRTq9NKud1iKUt8qkTLGH74E80hXLLVOFPYqRGy52OuTFnhpWvBXWEbkOJaDGaX_5L6CnyiQPPOYb2lFVxrJXsVd-W4NGHRzYtRQ5cJmiAbasK8kbNgDDhkJVTC9YrY6Rfi2; viewbook=7562814|7470570|7575429|7470584|7473513; QN267=675454631c32674; Hm_lpvt_c56a2b5278263aa647778d304009eafc=1582591567; QN271=c8712b13-2065-4aa7-a70b-e6156f6fc216',
'referer':'http://travel.qunar.com/travelbook/list.htm?page=1&order=hot_heat&avgPrice=1'}
count = 1
#共200页
for i in range(1,201):
url_ = url.format(i)
try:
response = requests.get(url=url_,headers = headers)
response.encoding = 'utf-8'
html = response.text
soup = BeautifulSoup(html,'lxml')
#print(soup)
all_url = soup.find_all('li',attrs={'class': 'list_item'})
#print(all_url[0])
'''
for i in range(len(all_url)):
#p = re.compile(r'data-url="/youji/\d+">')
url = re.findall('data-url="(.*?)"', str(i), re.S)
#url = re.search(p,str(i))
print(url)
'''
print('正在爬取第%s页' % count)
for each in all_url:
each_url = each.find('h2')['data-bookid']
#print(each_url)
fb.write(each_url)
fb.write('\n')
#last_url = each.find('li', {"class": "list_item last_item"})['data-url']
#print(last_url)
time.sleep(random.randint(3,5))
count+=1
except Exception as e:
print(e)
#爬取分页内容
import requests
from bs4 import BeautifulSoup
import re
import time
import csv
import random
# part2 爬虫 + 持久化
# 导入所需库
import requests
from bs4 import BeautifulSoup
import time
import random
import csv
# 读取url列表
with open('url_1.txt','r') as f:
for i in f.readlines():
i = i.strip()
url_list.append(i)
# 生成完整的url列表
the_url_list = []
for i in range(len(url_list)):
url = 'http://travel.qunar.com/youji/'
the_url = url + str(url_list[i])
the_url_list.append(the_url)
last_list = []
# 定义爬虫函数
def spider():
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36',
'cookies': 'QN1=00002b80306c204d8c38c41b; QN300=s%3Dbaidu; QN99=2793; QN205=s%3Dbaidu; QN277=s%3Dbaidu; QunarGlobal=10.86.213.148_-3ad026b5_17074636b8f_-44df|1582508935699; QN601=64fd2a8e533e94d422ac3da458ee6e88; _i=RBTKSueZDCmVnmnwlQKbrHgrodMx; QN269=D32536A056A711EA8A2FFA163E642F8B; QN48=6619068f-3a3c-496c-9370-e033bd32cbcc; fid=ae39c42c-66b4-4e2d-880f-fb3f1bfe72d0; QN49=13072299; csrfToken=51sGhnGXCSQTDKWcdAWIeIrhZLG86cka; QN163=0; Hm_lvt_c56a2b5278263aa647778d304009eafc=1582513259,1582529930,1582551099,1582588666; viewdist=298663-1; uld=1-300750-1-1582590496|1-300142-1-1582590426|1-298663-1-1582590281|1-300698-1-1582514815; viewbook=7575429|7473513|7470584|7575429|7470570; QN267=67545462d93fcee; _vi=vofWa8tPffFKNx9MM0ASbMfYySr3IenWr5QF22SjnOoPp1MKGe8_-VroXhkC0UNdM0WdUnvQpqebgva9VacpIkJ3f5lUEBz5uyCzG-xVsC-sIV-jEVDWJNDB2vODycKN36DnmUGS5tvy8EEhfq_soX6JF1OEwVFXk2zow0YZQ2Dr; Hm_lpvt_c56a2b5278263aa647778d304009eafc=1582603181; QN271=fc8dd4bc-3fe6-4690-9823-e27d28e9718c',
'Host': 'travel.qunar.com'
}
count = 1
for i in range(len(the_url_list)):
try:
print('正在爬取第%s页'% count)
response = requests.get(url=the_url_list[i],headers = headers)
response.encoding = 'utf-8'
html = response.text
soup = BeautifulSoup(html,'lxml')
information = soup.find('p',attrs={'class': 'b_crumb_cont'}).text.strip().replace(' ','')
info = information.split('>')
if len(info)>2:
location = info[1].replace('\xa0','').replace('旅游攻略','')
introduction = info[2].replace('\xa0','')
else:
location = info[0].replace('\xa0','')
introduction = info[1].replace('\xa0','')
#爬取内容
other_information = soup.find('ul',attrs={'class': 'foreignword_list'})
when = other_information.find('li',attrs={'class': 'f_item when'})
time1 = when.find('p',attrs={'class': 'txt'}).text.replace('出发日期','').strip()
howlong = other_information.find('li',attrs={'class': 'f_item howlong'})
day = howlong.find('p', attrs={'class': 'txt'}).text.replace('天数','').replace('/','').replace('天','').strip()
howmuch = other_information.find('li',attrs={'class': 'f_item howmuch'})
money = howmuch.find('p', attrs={'class': 'txt'}).text.replace('人均费用','').replace('/','').replace('元','').strip()
who = other_information.find('li',attrs={'class': 'f_item who'})
people = who.find('p',attrs={'class': 'txt'}).text.replace('人物','').replace('/','').strip()
how = other_information.find('li',attrs={'class': 'f_item how'})
play = how.find('p',attrs={'class': 'txt'}).text.replace('玩法','').replace('/','').strip()
Look = soup.find('span',attrs={'class': 'view_count'}).text.strip()
if time1:
Time = time1
else:
Time = '-'
if day:
Day = day
else:
Day = '-'
if money:
Money = money
else:
Money = '-'
if people:
People = people
else:
People = '-'
if play:
Play = play
else:
Play = '-'
last_list.append([location,introduction,Time,Day,Money,People,Play,Look])
#设置爬虫时间
time.sleep(random.randint(2,4))
count+=1
except Exception as e :
print(e)
#写入csv
with open('Travel_first.csv', 'a', encoding='utf-8-sig', newline='') as csvFile:
csv.writer(csvFile).writerow(['地点', '短评', '出发时间', '天数','人均费用','人物','玩法','浏览量'])
for rows in last_list:
csv.writer(csvFile).writerow(rows)
if __name__ == '__main__':
spider()
#数据可视化加数据分析代码
import pandas as pd
df = pd.read_csv('Travel_first.csv',encoding = 'gb18030')
df
df.info()
from pyecharts import Pie
m1 = df['人物'].value_counts().index.tolist()
n1 = df['人物'].value_counts().values.tolist()
pie =Pie('出游结伴方式',background_color = 'white',width = 800,height = 500,title_text_size = 20)
pie.add('',m1,n1,is_label_show = True,is_legend_show= True,radius=[40, 75])
pie.render('出行结伴方试.html')
from pyecharts import Bar
m2 = df['地点'].value_counts().head(10).index.tolist()
n2 = df['地点'].value_counts().head(10).values.tolist()
bar = Bar('目的地Top10',width = 800,height = 500,title_text_size = 20)
bar.add('',m2,n2,is_label_show = True,is_legend_show= True)
bar.render('目的地.html')
def Month(e):
m = str(e).split('/')[2]
if m=='01':
return '一月'
if m=='02':
return '二月'
if m=='03':
return '三月'
if m=='04':
return '四月'
if m=='05':
return '五月'
if m=='06':
return '六月'
if m=='07':
return '七月'
if m=='08':
return '八月'
if m=='09':
return '九月'
if m=='10':
return '十月'
if m=='11':
return '十一月'
if m=='12':
return '十二月'
df['旅行月份'] = df['出发时间'].apply(Month)
df['出发时间']=pd.to_datetime(df['出发时间'])
df
import re
def Look(e):
if '万' in e:
num1 = re.findall('(.*?)万',e)
return float(num1[0])*10000
else:
return float(e)
df['浏览次数'] = df['浏览量'].apply(Look)
df.drop(['浏览量'],axis = 1,inplace = True)
df['浏览次数'] = df['浏览次数'].astype(int)
df.head()
#遍历10行10列
df.head(10)
df.info()
data = df
data['地点'].value_counts()
loc = data['地点'].value_counts().head(10).index.tolist()
print(loc)
loc_data = data[df['地点'].isin(loc)]
price_mean = round(loc_data['人均费用'].groupby(loc_data['地点']).mean(),1)
print(price_mean)
#生成人均消费前十旅游地
from pyecharts import Bar
bar = Bar('人均消费前十旅游地',width = 800,height = 500,title_text_size = 20)
bar.add('',loc,price_mean,is_label_show = True,is_legend_show = True)
bar.render('人均消费前十旅游地.html')
df['天数'].value_counts()
df['旅游时长'] = df['天数'].apply(lambda x:str(x) + '天')
df['人物'].value_counts()
t = df['浏览次数'].sort_values(ascending=False).index[:].tolist()
df = df.loc[t]
df = df.reset_index(drop = True)
df['旅行月份'].value_counts()
word_list = []
for i in df['玩法']:
t = re.split('\xa0',i)
word_list.append(t)
dict = {}
for j in range(len(word_list)):
for i in word_list[j]:
if i not in dict:
dict[i] = 1
else:
dict[i]+=1
print(dict)
list = []
for item in dict.items():
list.append(item)
for i in range(1,len(list)):
for j in range(0,len(list)-1):
if list[j][1]<list[j+1][1]:
list[j],list[j+1] = list[j+1],list[j]
print(list)
from pyecharts import Pie
m1 = df['人物'].value_counts().index.tolist()
n1 = df['人物'].value_counts().values.tolist()
pie = Pie('出游结伴方式',background_color = 'white',width = 800,height = 500,title_text_size = 20)
pie.add('',m1,n1,is_label_show = True,is_legend_show= True,radius=[40, 75])
pie.render('出游结伴方式')
#生成2022出游时间曲线
from pyecharts import Line
m3 = df['出发时间'].value_counts().sort_index()[:]
m4 = m3['2022'].index
n4 = m3['2022'].values
m3['2022'].sort_values().tail(10)
line = Line('出游时间曲线',width = 800,height = 500,title_text_size = 20)
line.add('',m4,n4,is_legend_show= True)
line.render('出游时间曲线.html')
#生成2023出游时间曲线
m5 = m3['2023'].index
n5 = m3['2023'].values
m3['2023'].sort_values().tail(10)
line2 = Line('出游时间曲线',width = 800,height = 500,title_text_size = 20)
line2.add('',m5,n5,is_legend_show= True)
line2.render('出游时间曲线2023.html')
#出游玩法
m6= []
n6 = []
for i in range(20):
m6.append(list[i][0])
n6.append(list[i][1])
m6.reverse()
m7 = m6
n6.reverse()
n7 = n6
bar = Bar('出游玩法',width = 1000,height = 600,title_text_size = 30)
bar.add('',m7,n7,is_convert = True,is_label_show = True,label_pos = 'right')
bar.render('出游玩法.html')
df.head(10)
data_mo = df[((df['旅行月份'] =='七月')|(df['旅行月份'] =='八月'))&(df['人物']=='三五好友')]
data_mo.head(1000)
data_mo2 = df[((df['人物'] =='情侣')|(df['人物'] =='独自一人'))&(df['旅行月份']=='十月')]
data_mo2.head(1000)
#生成饼图
import jieba
import jieba.analyse
import re
punc = '~`!#$%^&*()_+-=|\';":/.,?><~·!@#¥%……&*()——+-=“:’;、。,?》《{}【】'
def remove_fuhao(e):
short = re.sub(r"[%s]+" % punc, " ", e)
return short
def cut_word(text):
text = jieba.cut_for_search(str(text))
return ' '.join(text)
data2 = df
data2['简介'] = data2['短评'].apply(remove_fuhao).apply(cut_word)
data2.head(100)
word = data2['简介'].values.tolist()
fb = open(r'.\travel_text.txt','w',encoding='utf-8')
for i in range(len(word)):
fb.write(word[i])
with open(r'.\travel_text.txt','r',encoding='utf-8')as f:
words = f.read()
f.close
jieba.analyse.set_stop_words(r'.\travel_text.txt')
new_words = jieba.analyse.textrank(words, topK=30, withWeight=True)
print(new_words)
from pyecharts import WordCloud
word1 = []
num1 = []
for i in range(len(new_words)):
word1.append(new_words[i][0])
num1.append(new_words[i][1])
wordcloud=WordCloud('简介词云分析',width=600,height=400)
wordcloud.add('简介词云分析',word1,num1,word_size_range=[25,80],shape = 'diamond')
wordcloud.render("简介词云分析.html")
m8 = df['天数'].value_counts().index.tolist()
n8 = df['天数'].value_counts().values.tolist()
m8.reverse()
m9 = m8
n8.reverse()
n9 = n8
bar = Bar('旅行时长',width = 800,height = 500,title_text_size = 30)
bar.add('',m9,n9,is_convert = True,is_label_show = True,label_pos = 'right')
bar.render('旅行时长.html')总结
根据词云可以得出人们都喜欢通过网红的影响去打卡旅游,自驾游越来越多,旅游的准备越来越充分。
根据饼图得出好友结伴旅游是最多的,家庭旅游其次,最少的是学生旅游,或许是因为当代大学生的时间和精力财力都不足以支撑额外开销吧
根据直方图可得最多的旅游城市是成都,最少的是桂林。娱乐方法最多的是摄影美食。
我认为分析此数据能够达到给大伙提供旅游参考的目的。
综上,我认为成都和厦门是个值得一去的地方。
对于我自己,我在这次课程设计中学到了很多,无论是代码实现还是数据分析,通过自己的实践实现一个个功能,都给我的python生涯是一个标志的里程碑,除开自己,最重要的还是老师专业的教导。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号