
论文阅读(XiangBai——【PAMI2018】ASTER_An Attentional Scene Text Recognizer with Flexible Rectification )
XiangBai——【PAMI2018】ASTER_An Attentional Scene Text Recognizer with Flexible Rectification
作者和论文
- 论文
XiangBai——【PAMI2018】ASTER_An Attentional Scene Text Recognizer with Flexible Rectification
姊妹会议篇论文:
B. Shi, X. Wang, P. Lyu, C. Yao, and X. Bai. Robust scene text recognition with automatic rectification. In CVPR, pages 4168– 4176, 2016.
- 作者
Baoguang Shi, Mingkun Yang, Xinggang Wang, Pengyuan Lyu, Cong Yao, and Xiang Bai
- 代码
方法概述
本文方法主要解决不规则排列文字的文字识别问题,论文为之前一篇CVPR206的paper(Robust Scene Text Recognition with Automatic Rectification,方法简称为RARE)的改进版(journal版)。
1. 主要思路
- 针对不规则文字,先矫正成正常线性排列的文字,再识别;
- 整合矫正网络和识别网络成为一个端到端网络来训练;
- 矫正网络使用STN,识别网络用经典的sequence to sequence + attention
2. 方法框架和流程
方法ASTER全称为Attentional Scene TExt Recognizer with Flexible Rectification,包括两个模块,一个用来矫正(rectification network),另一个用来识别(recognition work),如下图所示。
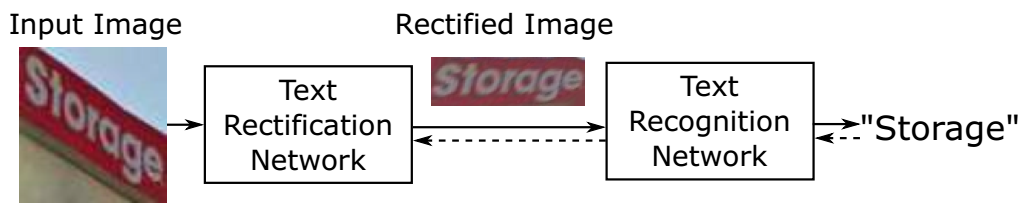
3. 文章亮点
- 效果太好了,针对普通文字和不规则文字,尤其是不规则文字
- 端到端训练 + 不需要人工标注(无需矫正网络的控制点)
方法细节
1. 背景
问题定义
本文要解决的问题是irregular text的识别问题,包括:多方向文字(oriented text)、透视形变文字(perspective text)、曲线文字(curved text),如下图所示:

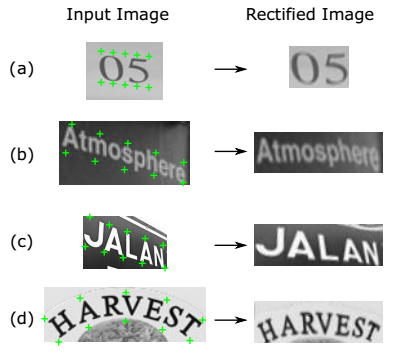
TPS
TPS全称Thin-Plate-Spline,可以对形变图像(仿射、透视、曲线排列等)进行校正,通过对control point进行定位和映射,来得到校正后的图像,方便后续进行识别。如下图所示,详细算法可以阅读参考文献1。

2. Rectification Network
网络框架
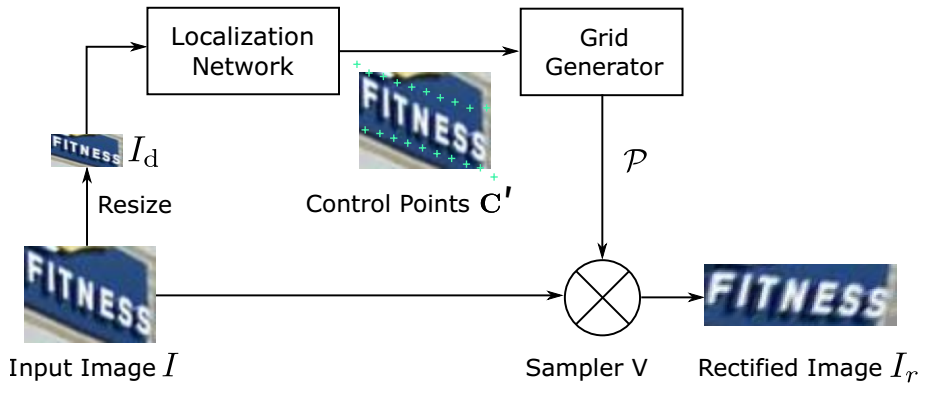
矫正网络框架图如下图,基本上是用STN的框架,包含三个部分,Localization Network,Grid Generator,以及Sampler。
- Localization Network用来检测图中的那些Control Points;
- Grid Generator通过这些Control Point来计算要生成的新图中每个点在原图中的点位置的映射关系;
- Sampler在原图上采样那些Grid Generator计算出的点位置,生成校正后的图。
Localization Network
- 定位网络(已经训练完进行测试时)的输入是待识别的未矫正前图像,输出是K个控制点的位置。
- 该定位网络训练时没有用K个控制点作为annotation进行训练,而是直接接入后面的Grid Generator + Sample利用最后的识别结果,连成一个end-to-end的框架进行训练。
- 网络结构采用一个自己设计的普通的卷积网络(6层卷积 + 5个max-pooling + 2个全连接)来预测K个control point的位置(K= 20),点对应关系如下图:
Grid Generator
该网格生成器和之前那篇会议paper(参考文献3),以及STN(参考文献2)其实是一样的,只是作者将公式用更详细的公式推导和图表示了一下。这里简单介绍下主要思想,具体公式推导等不细讲了。
-
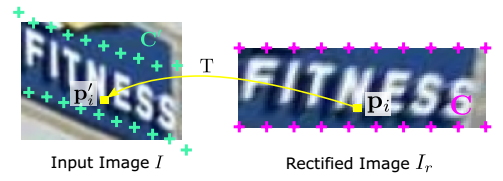
网格生成器的输入是已有的Control point点集 + 矫正后的图(还未生成,但给定图大小可以取点)上的某个点坐标,输出是该点在矫正前(原图)上的点坐标位置
-
网格生成器可以看成是一个矩阵变换操作(变换的几个参数a0-a2, b0-b2可以通过Control point位置利用优化问题求解方法求出,因为Control Point在矫正前后的图上的位置都是已知的,故可以计算出对应关系),实际做预测时也是计算该待测点与已知的control point的位置关系,通过一系列对应关系算出在原图的位置。贴个图感受一下这个对应关系如下,p为矫正后的点位置,C为矫正后的Control point的点位置,p'为矫正前的点位置,C’为Control point在矫正前的点位置:
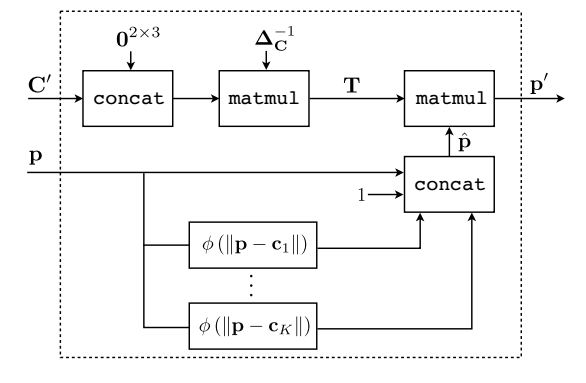
Sampler
该Sampler就是给定点映射关系及原图,生成一张新的矫正后的图,用到了简单的插值,以及当超出图外时直接clip掉。另外,Sampler采用可微的采样方法,方便梯度的bp。
- 输入是原图 + 矫正后的图上的点在原图上的对应位置关系, 输出是矫正后的图
和STN以及RARE的对比
-
和STN的不同点
本文在输入网络前将原图resize成小的图,然后在该小图上预测control point,而输入到Grid Generator或Sample计算的时候又映射回原图大小。这样的目的是为了减小网络参数,降低计算量(但有没有可能小图对于control point的prediction会不准?对于识别来讲,每个word的patch块本身就比较小了,而且小图映射回大图的点位置这个误差比例就会放大?)
-
和RARE的不同点
网络最后fc层的激活函数不是用tanh,而是直接对值进行clipping(具体怎么clip论文没说),这样做的目的是为了解决采样点可能落到图外面的问题,以及加快了网络训练的收敛速度,论文中对此没有解释本质原因,只是说明实验证明如此
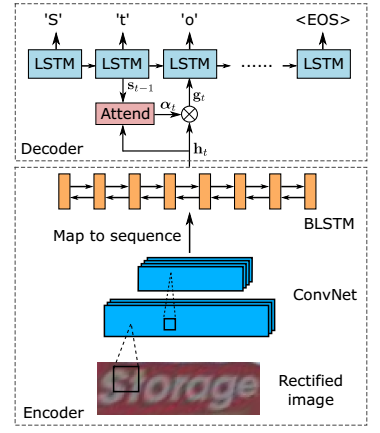
3. Recognition Network
网络框架
识别网络采用当前识别的一般思路:
sequence-to-sequence (encoder/decoder框架)+ attention + beam search。
网络主要分为两部分,ConvNet + 双向LSTM的encoder模块,和LSTM + attention的decoder模块。
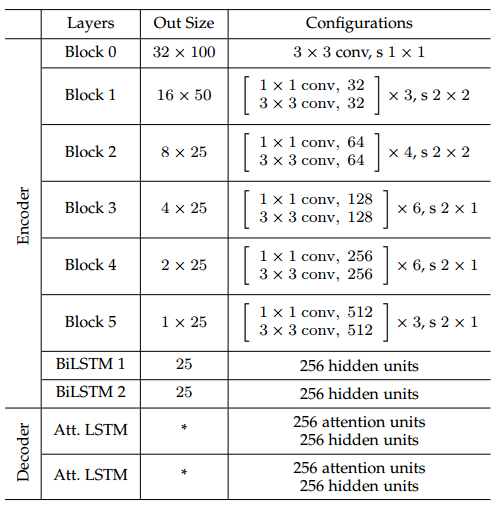
网络配置
4. 网络训练
损失函数如下,需要计算left-to-right的decoder以及right-to-left的decoder损失。除Location Network的FC层权重初始化为0(防止矫正后的图distort非常厉害),其余所有网络层都采用随机初始化。
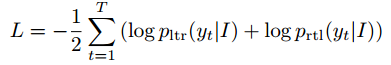
实验结果
实现细节
- 环境:tensorflow, TITAN Xp,12GB 内存
- 速度:训练6.5iter/s,2天训练,测试inference 20ms
- 优化:ADADELTA(比SGD更好一些),在Synth90k预训练,学习率1.0,0.1(0.6M), 0.01(0.8M)
验证矫正网络
结论: 矫正对一般水平样本(IIIT5k,IC03,IC13)略有提高,对形变比较大的不规则样本(SVT,SVTP,CUTE)提高3~4个点



Selected results on SVT-Perspective and CUTE80. For every two rows, the first row contains the input images (top), the predicted control points (visualized as green crosses), and the rectified images (bottom). The second row contains the recognition results.
验证识别网络
-
Attention的效果
结论: attention对字符的位置有隐性的定位功能
![]()
-
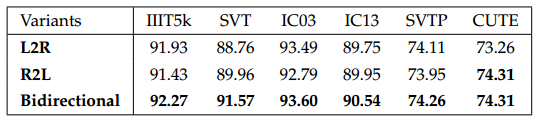
双向LSTM的作用
结论:两个方向的LSTM有一定互补作用
![]()
-
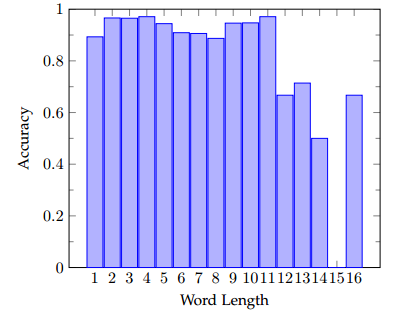
字符长度的影响
结论: 字符小于11时,识别精度差不多,大于11后精度有所下降,因为长文字本身更难
![]()

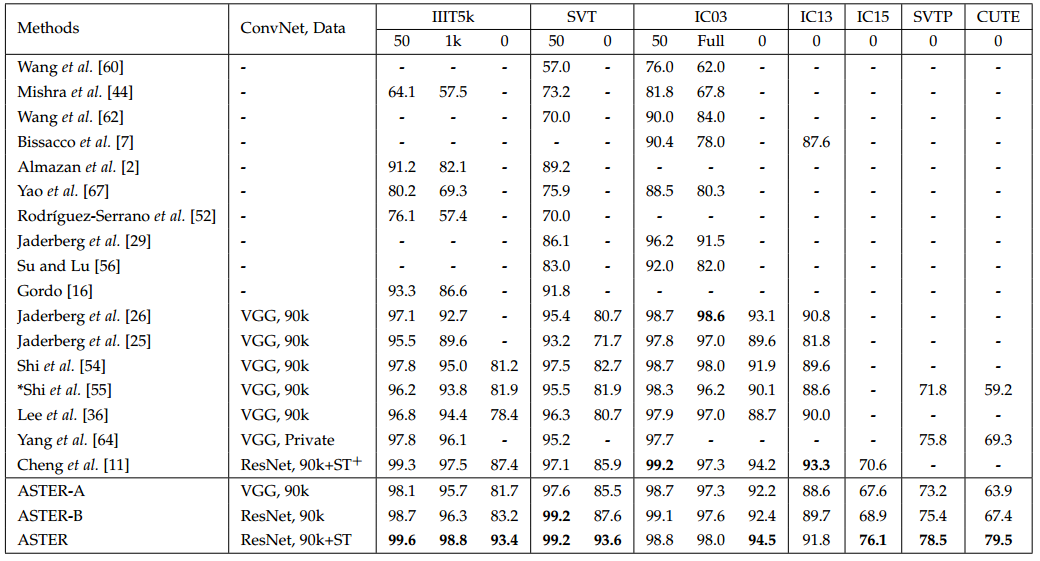
验证端到端结果
结论:这个效果有点碉堡了...有几个库甩第二名好多,就连其他CVPR2018的paper都望尘莫及...
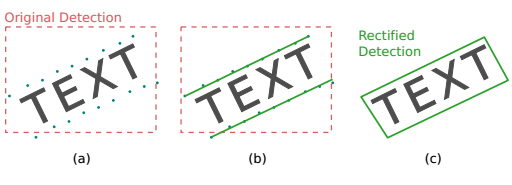
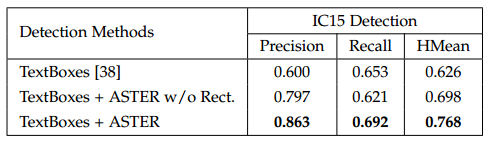
验证对检测的影响
结论:对检测结果可以微调,可以让检测结果更好,这里提高原因有两个,1是因为通过识别把噪声过滤掉了, 2是位置更准确
总结与收获
- 问题整理
- 这篇文章和之前的RARE从方法介绍上看,几乎没什么变化,作者说不同点一个是有进行resize,另一个是localization network的fc激活函数从tanh换成一般的value clipping。这两点变化都不大,但效果比RARE好很多,具体原因有待探讨
- 根据文献4和文献5,TPS训练上需要很多规则和技巧,没有人工标注的点很难训练好,这一点这篇文章是怎么解决的?
- 怎样判断一张图是否需要矫正?如果普通图输入到矫正网络,是否有可能会因为control point预测错误导致识别效果反而不好?
- 好像没有提到整个识别的时间?
- 当前做不规则文字的检测和识别思路主要是两类,一种是本文的先用一个网络矫正,再用一个网络识别,另一种思路是结合字符信息来做。本文针对不规则的文字识别问题,把第一条思路几乎已经做到极致了(至少效果上是...)
参考文献
- F. L. Bookstein. Principal warps: Thin-plate splines and the decomposition of deformations. IEEE Trans. Pattern Anal. Mach. Intell., 11(6):567–585, 1989.
- M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu. Spatial transformer networks. In NIPS, 2015.
- B. Shi, X. Wang, P. Lyu, C. Yao, and X. Bai. Robust scene text recognition with automatic rectification. In CVPR, pages 4168– 4176, 2016.
- Zhanzhan Cheng——【CVPR2018】AON_Towards Arbitrarily-Oriented Text Recognition
- Zhanzhan Cheng——【CVPR2018】Edit Probability for Scene Text Recognition

 浙公网安备 33010602011771号
浙公网安备 33010602011771号