
Python网络爬虫——爬取豆瓣电影剧情片排行榜
Python网络爬虫——爬取豆瓣剧情片排行榜
一、 选题的背景
为什么要选择此选题?要达到的数据分析的预期目标是什么?(10分)
电影行业的兴起,引发许多的热潮,剧情片又是电影的一大种类,非常具有意义。爬取之后可以更直观的明白剧情片排行的相应情况。
从社会、经济、技术、数据来源等方面进行描述(200字以内)
疫情当前,许多人只能居家,电影自然就成了大家消遣的一大方式,清楚的了解电影相关的数据,可以使人们更好的明白如何去选择优质的电影。
二、主题式网络爬虫设计方案(10分)
1.主题式网络爬虫名称
Python网络爬虫——爬取豆瓣剧情片排行榜
2.主题式网络爬虫爬取的内容与数据特征分析
爬取豆瓣剧情片排行数据做可视化处理
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
步骤:首先,先确定此次的选题的主题内容,然后爬取豆瓣剧情热搜排行,设计爬取程序进行爬取(爬取内容时会遇到爬出来的数据为***万人,思考如何将此数据变成数字),将爬取的数据做成xsl表格时(
1. 进行可视化处理。最后,保存数据。
三、主题页面的结构特征分析
1.主题页面的结构与特征分析
1.主题页面的结构与特征分析:打开开发者控制工具,通过逐个检索分析找到自己需要的数据,发现所需的标签都在<body>的<div>中。
2.Htmls页面解析

四、网络爬虫程序设计
1 import requests 2 import json 3 url = 'https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=0&limit=20' 4 head={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.6241 SLBChan/25'} 5 r=requests.get(url,headers=head) 6 r.encoding = "utf-8" 7 data=json.loads(r.text) 8 a=data 9 for i in data: 10 print(i)

1 rank=[] 2 name=[] 3 vote=[] 4 actor=[] 5 score=[] 6 for i in a: 7 rank.append(i['rank']) 8 name.append(i['title']) 9 vote.append(i['vote_count']) 10 actor.append(i['actor_count']) 11 score.append(i[ 'score']) 12 print(rank) 13 print(name) 14 print(vote) 15 print(actor) 16 print(score)

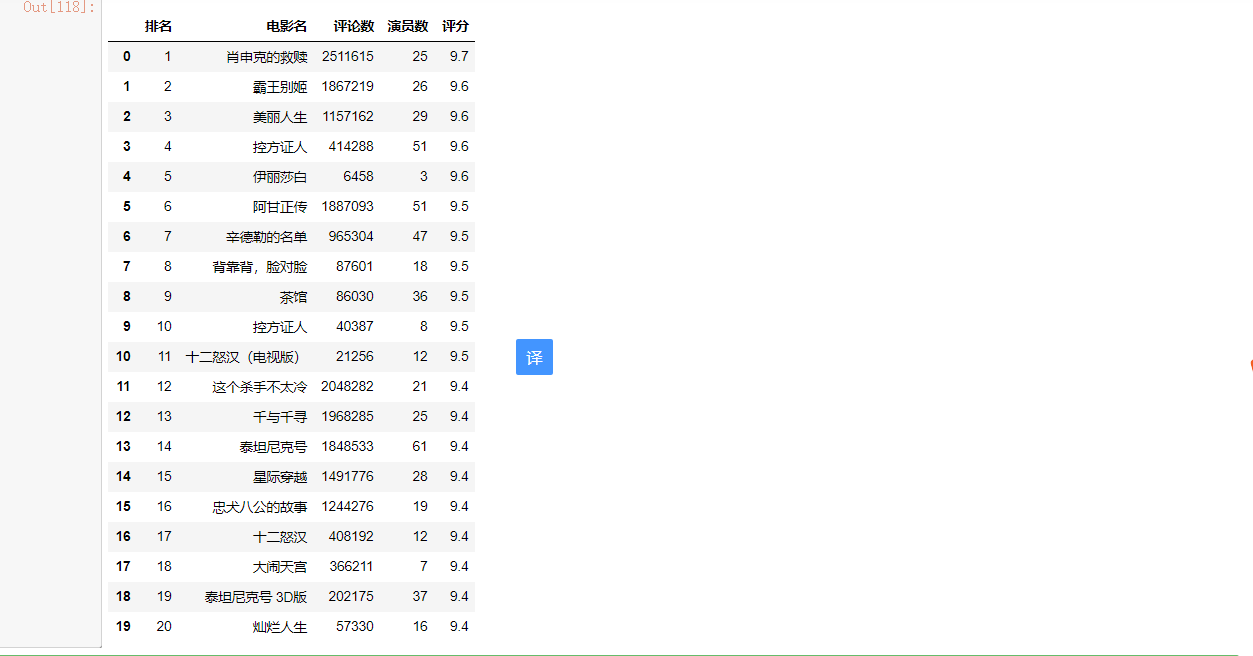
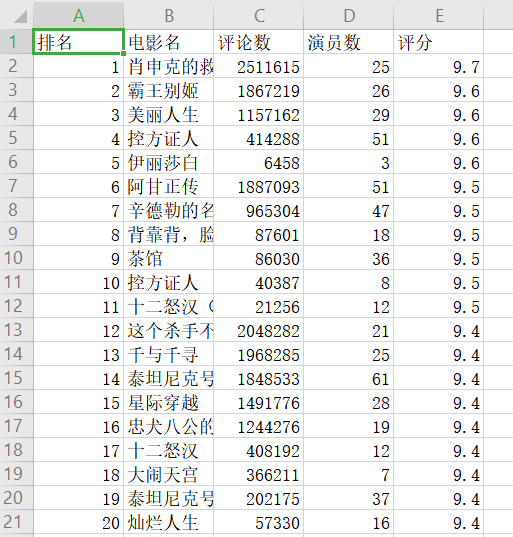
1 import pandas as pd 2 df=pd.DataFrame({'排名':rank,'电影名':name}) 3 df['评论数']=vote 4 df['演员数']=actor 5 df['评分']=score 6 df 7 df.to_csv('D:\Python\豆瓣电影.txt') 8 df.to_csv('D:\Python\豆瓣电影.csv',index=False)
1 #删除无效列 2 #df.drop('电影名',axis=1,inplace=True) 3 df.head()
1 #删除无效列 2 df.drop('演员数',axis=1,inplace=True) 3 print(df.head)

1 #检查是否有重复值 2 print(df.duplicated())

#检查是否有空值 print(df['评分'].isnull().value_counts()) #检查是否有空值 print(df['排名'].isnull().value_counts()) #检查是否有空值 print(df['评论数'].isnull().value_counts()) #检查是否有空值 print(df['演员数'].isnull().value_counts())

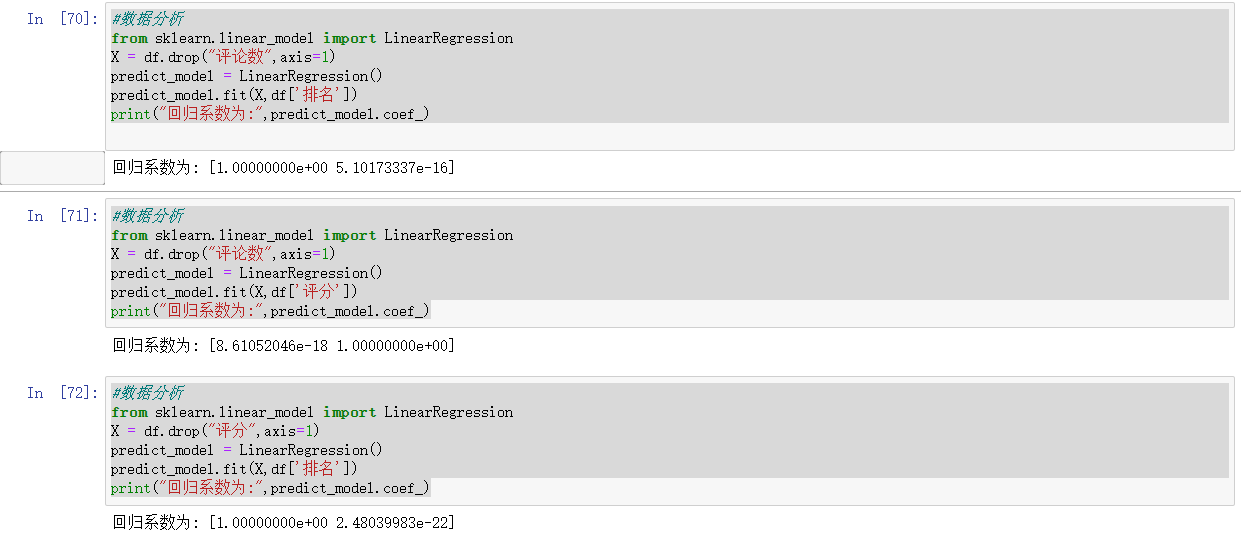
1 #数据分析 2 from sklearn.linear_model import LinearRegression 3 X = df.drop("评论数",axis=1) 4 predict_model = LinearRegression() 5 predict_model.fit(X,df['排名']) 6 print("回归系数为:",predict_model.coef_) 7 #数据分析 8 from sklearn.linear_model import LinearRegression 9 X = df.drop("评论数",axis=1) 10 predict_model = LinearRegression() 11 predict_model.fit(X,df['评分']) 12 print("回归系数为:",predict_model.coef_) 13 #数据分析 14 from sklearn.linear_model import LinearRegression 15 X = df.drop("评分",axis=1) 16 predict_model = LinearRegression() 17 predict_model.fit(X,df['排名']) 18 print("回归系数为:",predict_model.coef_)
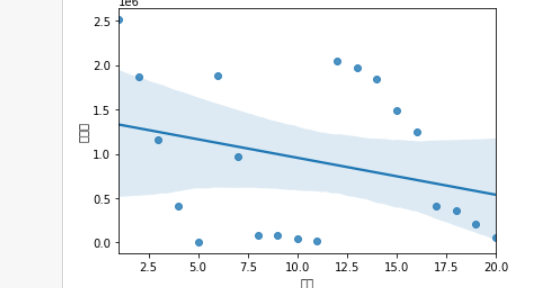
1 #绘制排名与热度的回归图 2 import seaborn as sns 3 sns.regplot(df['排名'],df['评论数'])
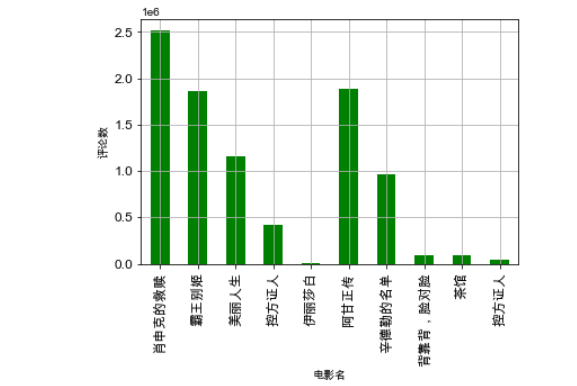
1 #柱形图 2 import matplotlib.pyplot as plt 3 import pandas as pd 4 import numpy as np 5 data=pd.Series(vote[0:10],name[0:10]) 6 print(data) 7 #索引 8 index=np.arange(1,11) 9 #用来正常显示中文标签 10 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] 11 #用来正常显示负号 12 plt.rcParams['axes.unicode_minus']=False 13 #修改x轴字体大小为12 14 plt.xticks(fontsize=12) 15 #修改y轴字体大小为12 16 plt.yticks(fontsize=12) 17 print(data) 18 print(index) 19 #x标签 20 plt.xlabel('电影名') 21 #y标签 22 plt.ylabel('评论数') 23 data.plot(kind='bar',color='g') 24 plt.grid() 25 plt.show()
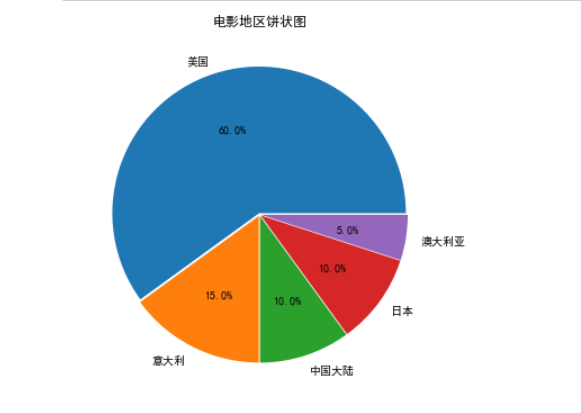
1 import matplotlib.pyplot as plt 2 plt.rcParams['font.sans-serif']='SimHei' 3 #设置中文显示 4 plt.figure(figsize=(6,6)) 5 #将画布设定为正方形,则绘制的饼图是正圆 6 label=['美国','意大利','中国大陆','日本','澳大利亚'] 7 #定义饼图的标签,标签是列表 8 explode=[0.01,0.01,0.01,0.01,0.01] 9 #设定各项距离圆心n个半径 10 #plt.pie(values[-1,3:6],explode=explode,labels=label,autopct='%1.1f%%') 11 #绘制饼图 12 values=[12,3,2,2,1] 13 plt.pie(values,explode=explode,labels=label,autopct='%1.1f%%') 14 #绘制饼图 15 plt.title('电影地区饼状图') 16 #绘制标题 17 plt.savefig('./电影地区饼状图') 18 #保存图片 19 plt.show()
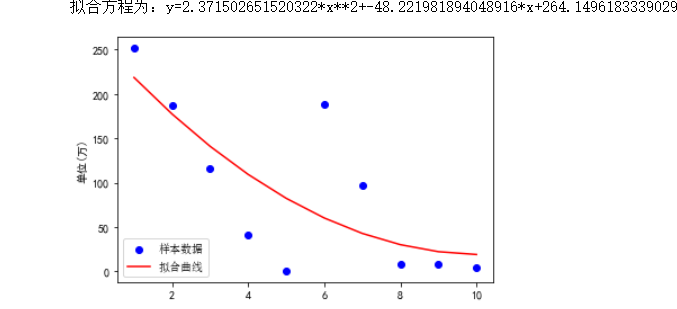
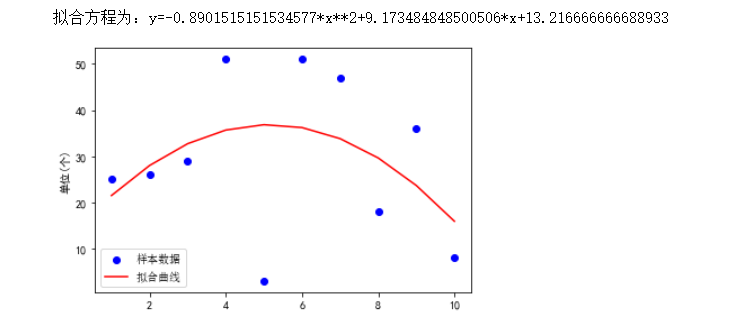
1 import matplotlib.pyplot as plt 2 import matplotlib 3 import numpy as np 4 import scipy.optimize as opt 5 x0=df['排名'][0:10] 6 y0=df['评论数'][0:10]/10000 7 def func(x,c0): 8 a,b,c=c0 9 return a*x**2+b*x+c 10 def errfc(c0,x,y): 11 return y-func(x,c0) 12 c0=[0,2,3] 13 c1=opt.leastsq(errfc,c0,args=(x0,y0))[0] 14 a,b,c=c1 15 print(f"拟合方程为:y={a}*x**2+{b}*x+{c}") 16 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') 17 plt.plot(x0,y0,"ob",label="样本数据") 18 plt.plot(x0,func(x0,c1),"r",label="拟合曲线") 19 plt.legend(loc=3,prop=chinese) 20 plt.ylabel('单位(万)') 21 plt.show() 22 import matplotlib.pyplot as plt 23 import matplotlib 24 import numpy as np 25 import scipy.optimize as opt 26 x0=df['排名'][0:10] 27 y0=df['演员数'][0:10] 28 def func(x,c0): 29 a,b,c=c0 30 return a*x**2+b*x+c 31 def errfc(c0,x,y): 32 return y-func(x,c0) 33 c0=[0,2,3] 34 c1=opt.leastsq(errfc,c0,args=(x0,y0))[0] 35 a,b,c=c1 36 print(f"拟合方程为:y={a}*x**2+{b}*x+{c}") 37 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') 38 plt.plot(x0,y0,"ob",label="样本数据") 39 plt.plot(x0,func(x0,c1),"r",label="拟合曲线") 40 plt.legend(loc=3,prop=chinese) 41 plt.ylabel('单位(个)') 42 plt.show()
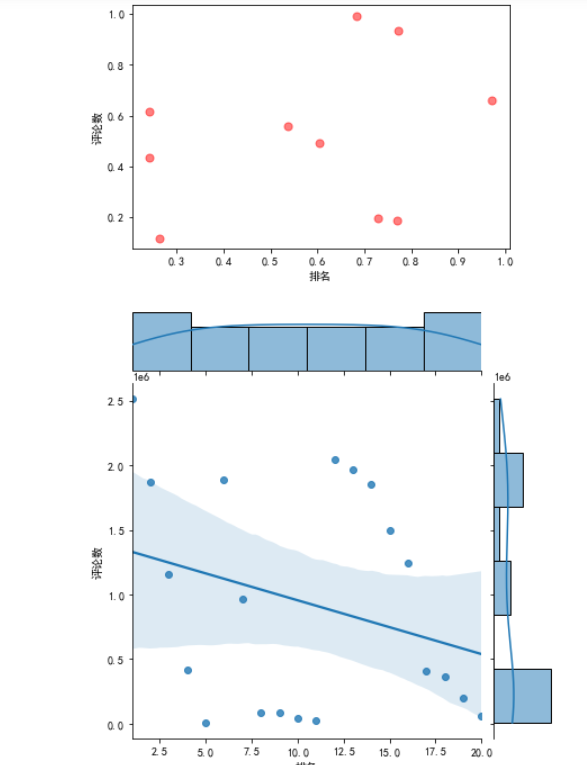
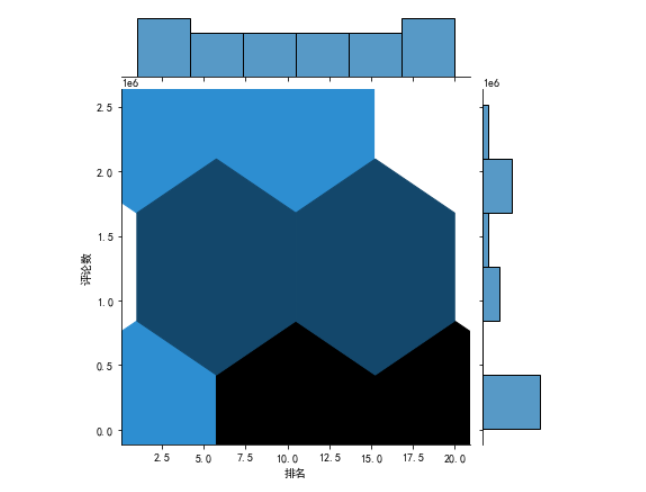
1 plt.rcParams['font.sans-serif'] = ['SimHei'] 2 # 用来正常显示中文标签 3 plt.rcParams['axes.unicode_minus'] = False 4 # 用来正常显示负号 5 N=10 6 x=np.random.rand(N) 7 y=np.random.rand(N) 8 size=50 9 plt.xlabel("排名") 10 plt.ylabel("评论数") 11 plt.scatter(x,y,size,color='r',alpha=0.5,marker="o") 12 #散点图 kind='reg' 13 sns.jointplot(x="排名",y="评论数",data=df,kind='reg') 14 # kind='hex' 15 sns.jointplot(x="排名",y="评论数",data=df,kind='hex') 16 # kind='kde' 17 sns.jointplot(x="排名",y="评论数",data=df,kind="kde",space=0,color='g')

五、完整代码
1 import requests 2 import json 3 url = 'https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=0&limit=20' 4 head={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.6241 SLBChan/25'} 5 r=requests.get(url,headers=head) 6 r.encoding = "utf-8" 7 data=json.loads(r.text) 8 a=data 9 for i in data: 10 print(i) 11 rank=[] 12 name=[] 13 vote=[] 14 actor=[] 15 score=[] 16 for i in a: 17 rank.append(i['rank']) 18 name.append(i['title']) 19 vote.append(i['vote_count']) 20 actor.append(i['actor_count']) 21 score.append(i[ 'score']) 22 print(rank) 23 print(name) 24 print(vote) 25 print(actor) 26 print(score) 27 import pandas as pd 28 df=pd.DataFrame({'排名':rank,'电影名':name}) 29 df['评论数']=vote 30 df['演员数']=actor 31 df['评分']=score 32 df 33 df.to_csv('D:\Python\豆瓣电影.txt') 34 df.to_csv('D:\Python\豆瓣电影.csv',index=False) 35 #删除无效列 36 #df.drop('电影名',axis=1,inplace=True) 37 df.head() 38 #删除无效列 39 df.drop('演员数',axis=1,inplace=True) 40 print(df.head) 41 #检查是否有重复值 42 print(df.duplicated()) 43 #检查是否有空值 44 print(df['评分'].isnull().value_counts()) 45 #检查是否有空值 46 print(df['排名'].isnull().value_counts()) 47 #检查是否有空值 48 print(df['评论数'].isnull().value_counts()) 49 #检查是否有空值 50 print(df['演员数'].isnull().value_counts()) 51 #数据分析 52 from sklearn.linear_model import LinearRegression 53 X = df.drop("评论数",axis=1) 54 predict_model = LinearRegression() 55 predict_model.fit(X,df['排名']) 56 print("回归系数为:",predict_model.coef_) 57 #数据分析 58 from sklearn.linear_model import LinearRegression 59 X = df.drop("评论数",axis=1) 60 predict_model = LinearRegression() 61 predict_model.fit(X,df['评分']) 62 print("回归系数为:",predict_model.coef_) 63 #数据分析 64 from sklearn.linear_model import LinearRegression 65 X = df.drop("评分",axis=1) 66 predict_model = LinearRegression() 67 predict_model.fit(X,df['排名']) 68 print("回归系数为:",predict_model.coef_) 69 #绘制排名与热度的回归图 70 import seaborn as sns 71 sns.regplot(df['排名'],df['评论数']) 72 #柱形图 73 import matplotlib.pyplot as plt 74 import pandas as pd 75 import numpy as np 76 data=pd.Series(vote[0:10],name[0:10]) 77 print(data) 78 #索引 79 index=np.arange(1,11) 80 #用来正常显示中文标签 81 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] 82 #用来正常显示负号 83 plt.rcParams['axes.unicode_minus']=False 84 #修改x轴字体大小为12 85 plt.xticks(fontsize=12) 86 #修改y轴字体大小为12 87 plt.yticks(fontsize=12) 88 print(data) 89 print(index) 90 #x标签 91 plt.xlabel('电影名') 92 #y标签 93 plt.ylabel('评论数') 94 data.plot(kind='bar',color='g') 95 plt.grid() 96 plt.show() 97 import matplotlib.pyplot as plt 98 plt.rcParams['font.sans-serif']='SimHei' 99 #设置中文显示 100 plt.figure(figsize=(6,6)) 101 #将画布设定为正方形,则绘制的饼图是正圆 102 label=['美国','意大利','中国大陆','日本','澳大利亚'] 103 #定义饼图的标签,标签是列表 104 explode=[0.01,0.01,0.01,0.01,0.01] 105 #设定各项距离圆心n个半径 106 #plt.pie(values[-1,3:6],explode=explode,labels=label,autopct='%1.1f%%') 107 #绘制饼图 108 values=[12,3,2,2,1] 109 plt.pie(values,explode=explode,labels=label,autopct='%1.1f%%') 110 #绘制饼图 111 plt.title('电影地区饼状图') 112 #绘制标题 113 plt.savefig('./电影地区饼状图') 114 #保存图片 115 plt.show() 116 import matplotlib.pyplot as plt 117 import matplotlib 118 import numpy as np 119 import scipy.optimize as opt 120 x0=df['排名'][0:10] 121 y0=df['评论数'][0:10]/10000 122 def func(x,c0): 123 a,b,c=c0 124 return a*x**2+b*x+c 125 def errfc(c0,x,y): 126 return y-func(x,c0) 127 c0=[0,2,3] 128 c1=opt.leastsq(errfc,c0,args=(x0,y0))[0] 129 a,b,c=c1 130 print(f"拟合方程为:y={a}*x**2+{b}*x+{c}") 131 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') 132 plt.plot(x0,y0,"ob",label="样本数据") 133 plt.plot(x0,func(x0,c1),"r",label="拟合曲线") 134 plt.legend(loc=3,prop=chinese) 135 plt.ylabel('单位(万)') 136 plt.show() 137 import matplotlib.pyplot as plt 138 import matplotlib 139 import numpy as np 140 import scipy.optimize as opt 141 x0=df['排名'][0:10] 142 y0=df['演员数'][0:10] 143 def func(x,c0): 144 a,b,c=c0 145 return a*x**2+b*x+c 146 def errfc(c0,x,y): 147 return y-func(x,c0) 148 c0=[0,2,3] 149 c1=opt.leastsq(errfc,c0,args=(x0,y0))[0] 150 a,b,c=c1 151 print(f"拟合方程为:y={a}*x**2+{b}*x+{c}") 152 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') 153 plt.plot(x0,y0,"ob",label="样本数据") 154 plt.plot(x0,func(x0,c1),"r",label="拟合曲线") 155 plt.legend(loc=3,prop=chinese) 156 plt.ylabel('单位(个)') 157 plt.show() 158 plt.rcParams['font.sans-serif'] = ['SimHei'] 159 # 用来正常显示中文标签 160 plt.rcParams['axes.unicode_minus'] = False 161 # 用来正常显示负号 162 N=10 163 x=np.random.rand(N) 164 y=np.random.rand(N) 165 size=50 166 plt.xlabel("排名") 167 plt.ylabel("评论数") 168 plt.scatter(x,y,size,color='r',alpha=0.5,marker="o") 169 #散点图 kind='reg' 170 sns.jointplot(x="排名",y="评论数",data=df,kind='reg') 171 # kind='hex' 172 sns.jointplot(x="排名",y="评论数",data=df,kind='hex') 173 # kind='kde' 174 sns.jointplot(x="排名",y="评论数",data=df,kind="kde",space=0,color='g')
六、总结
1.经过对主题数据的分析和可视化,发现剧情片排名靠前的电影不一定评论数多,有几部电影的评论较少,因此评分高不一定代表热度评论数就多。
2.在数据处理上,有些数据无法进行相关分析,像评分与排名之间就无法做出相关线性图,因此只能用评论数和排名进行相关分析,不过柱状图、饼状图就可对其进行相关分析,可以更加直观的看起其对应的关系,可以更好的对数据进行分析。
3.通过本次课程设计的学习,我也了解到自己知识点的薄弱,许多问题无法自行解决,需要翻阅资料,查看网络相关视频、请教同学才能解决相应问题,因此在后面的学习过程中应该更加认真。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号