
了解Hive基础
一、了解Hive基础
(一)认识Hive
1、背景
数据存储在HDFS上没有Schema(模式)的概念,所以Facebook创造Hive将数据从一个现有的数据架构转移到Hadoop
Schema:模式,相当于表里的列、字段、字段名称、字段与字段的分隔符
2、数据仓库与数据库的区别
| 数据仓库 | 数据库 | |
|---|---|---|
| 处理方式 | 联机分析处理(OLAP,On-Line Analytical Processing) | 联机事务处理(OLTP,On-Line Transaction Processing) |
| 数据 | 历史数据 | 业务数据 |
| 面向 | 面向主题 | 面向事务 |
| 目的 | 分析数据 | 捕获数据 |
| 是否冗余 | 有意冗余,依照分析需求设计 | 避免冗余,针对某一业务 |
3、Hive在Hadoop生态中的位置
Hive将存储在HDFS中的结构化数据映射成类关系型数据库表,接受类SQL语句,转化为MapReduce程序去执行。
Hive执行本质仍是MapReduce,但多了SQL到MapReduce的转化,所以同等条件下,Hive在运行时并没有直接编写MapReduce效率高。
Hive的必要环境:HDFS、MapReduce和YARN。
4、Hive与传统关系型数据库
传统关系型数据库:Relational Database Management System,简称RDBMS
| Hive | RDBMS | |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | 块设备,本地文件系统 |
| 执行 | MapReduce(硬盘执行) | Executor() |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
| 事务 | 0.14版本后加入 | 支持 |
| 索引 | 0.8版本后加入 | 索引复杂 |
| 应用场景 | 离线大数据分析(日志分析) | 在线应用 |
5、Hive优势
- 语言和SQL类似,提高了开发效率
- 支持在不同的计算机框架运行,YARN、Tez、Spark、Flink等。
- 支持用户自定义的函数、脚本
- 避免编写MapReduce,减少开发人员的学习成本
- 支持Java数据库与开放数据库的连接
- 支持HDFS与HBase上的ad-hoc
ad-hoc:拉丁语,for this 意为 "为了此事 ",大数据领域称之为 “即席查询”,用户根据自己的需求,灵活的选择查询条件,系统能够根据条件快速的进行查询分析返回结果
生产环境中的优势
- 可扩展性:自由扩展规模,无需重启
- 可延展性:用户可自定义函数
- 可容错性:节点出错SQL仍可完成任务
(二)Hive架构设计
1、Hive客户端
针对应用程序提供不同驱动,对Java应用程序提供JDBC;其它的提供ODBC。
2、Hive服务端
客户端通过服务端进行交互,服务端主要包括CLI、Driver等。
3、Hive存储与计算
通过元数据存储数据库和Hadoop集群进行数据的存储和计算。
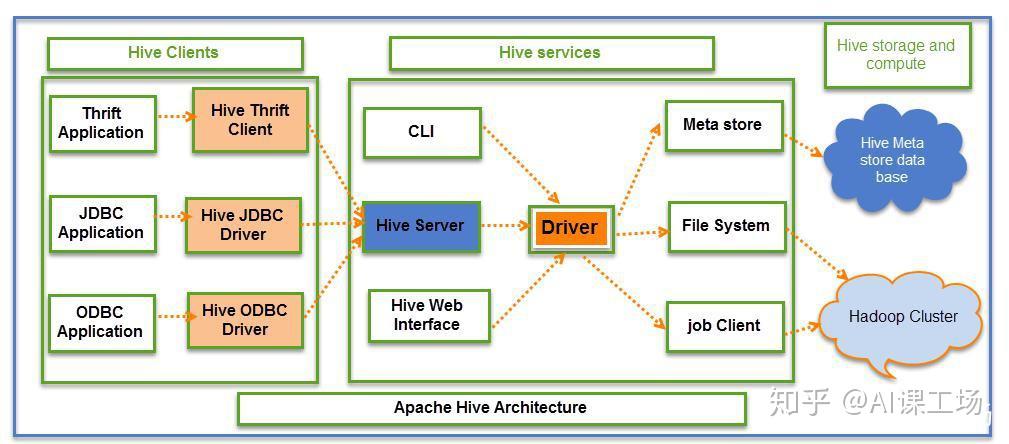
主要组件

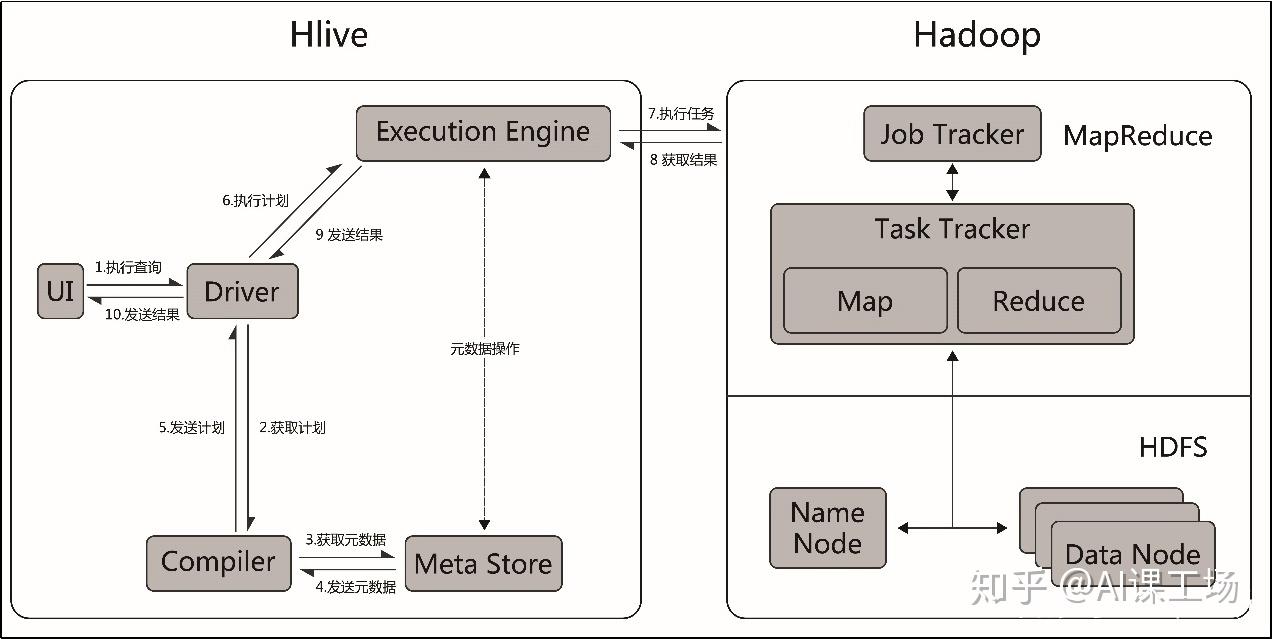
(三)Hive工作流程:

(四)Hive适用的场景
- 非结构化数据的离线分析统计场合
- 由于高延迟所以只适用实时性不高的场景
- 大数据处理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号