

102302126李坤铭作业1
作业1
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
1)代码:
点击查看代码
import requests
from bs4 import BeautifulSoup
# 目标 URL(上海软科 2020 年中国大学排名)
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
# 1. 发送 HTTP 请求
try:
response = requests.get(url)
response.encoding = "utf-8" # 确保编码正确
response.raise_for_status() # 如果请求失败,抛出异常
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
exit()
# 2. 解析 HTML 内容
soup = BeautifulSoup(response.text, "html.parser")
# 3. 定位排名数据所在的表格
tables = soup.find_all("table")
for table in tables:
if "排名" in table.text: # 判断表格是否包含“排名”
break
if not table:
print("未找到排名表格!")
exit()
# 4. 提取表格中的每一行数据(跳过表头)
rows = table.find_all("tr")[1:] # 跳过表头行
# 5. 存储并打印排名信息
rankings = []
for row in rows:
cols = row.find_all("td")
if len(cols) < 5: # 确保每行有足够的数据
continue
rank = cols[0].text.strip() # 排名
name = cols[1].text.strip() # 学校名称
province = cols[2].text.strip() # 省市
type_ = cols[3].text.strip() # 学校类型
score = cols[4].text.strip() # 总分
rankings.append((rank, name, province, type_, score))
# 6. 打印结果
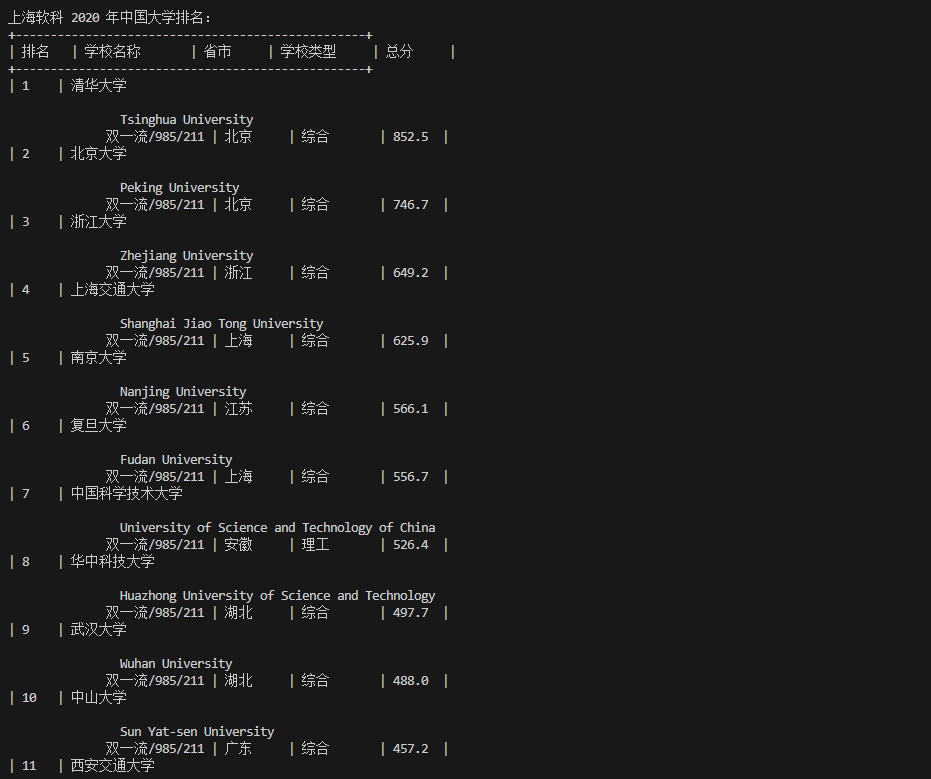
print("上海软科 2020 年中国大学排名:")
print("+" + "-"*50 + "+")
print("| {:<4} | {:<10} | {:<6} | {:<8} | {:<6} |".format("排名", "学校名称", "省市", "学校类型", "总分"))
print("+" + "-"*50 + "+")
for rank in rankings:
print("| {:<4} | {:<10} | {:<6} | {:<8} | {:<6} |".format(*rank))
print("+" + "-"*50 + "+")
2)作业心得
这段代码是一个简单的网页数据抓取示例,其逻辑非常直观:首先通过请求获取网页内容,然后利用解析工具对页面进行解析,最后从中提取所需的数据信息。具体来说,使用requests库来获取网页内容,借助BeautifulSoup库精准定位数据所在位置,同时还需要对中文乱码以及数据中多余的空格、换行进行清理,让展示的数据会显得整齐统一。
作业2
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
1)代码:
点击查看代码
import urllib.request
import re
def fetch_dangdang_backpack_products():
search_url = "https://search.dangdang.com/?key=%CA%E9%B0%FC&category_id=10009684#J_tab"
try:
with urllib.request.urlopen(search_url, timeout=3) as response:
page_content = response.read().decode('gb2312')
# 使用更精确的正则匹配商品列表项
product_items = re.findall(r'<li[^>]*?class="line[^>]*>(.*?)</li>', page_content, re.S)
# 定义更健壮的正则模式
title_regex = re.compile(r'<a[^>]*title=["\']\s*([^"\']*?)\s*["\']', re.I)
price_regex = re.compile(r'<span[^>]*class=["\']price_n["\'][^>]*>(.*?)</span>', re.S)
valid_products = 0
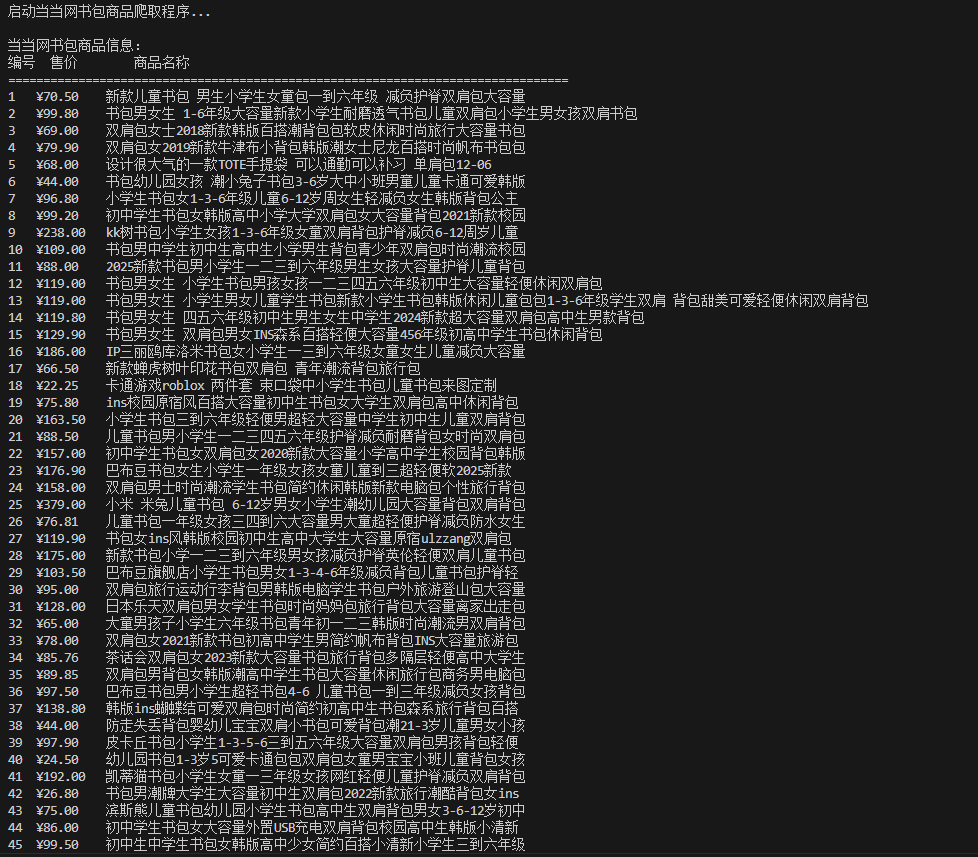
print("当当网书包商品信息:")
print(f"{'编号':<4}{'售价':<10}{'商品名称'}")
print("=" * 80)
for position, item in enumerate(product_items, 1):
titles = title_regex.findall(item)
prices = price_regex.findall(item)
if titles and prices:
item_name = titles[0].strip()
item_price = prices[0].strip().replace('¥', '¥')
print(f"{position:<4}{item_price:<10}{item_name}")
valid_products += 1
print("=" * 80)
print(f"成功获取 {valid_products} 个有效商品信息")
except urllib.error.URLError as error:
if hasattr(error, 'code'):
print(f"HTTP请求失败,状态码:{error.code}(可能触发反爬机制,建议优化请求头)")
else:
print(f"网络请求异常:{error.reason}")
if __name__ == "__main__":
print("启动当当网书包商品爬取程序...\n")
fetch_dangdang_backpack_products()
print("\n爬取程序执行完毕!")
2)作业心得
通过本次代码调试实践,我深入认识到Cookie在应对网站反爬机制中的关键作用:当当网通过Cookie来追踪和验证用户身份,当HTTP请求缺少有效的Cookie时,服务器会直接返回显示"无商品数据"的空白页面(即便请求头中已正确设置User-Agent)。因此,在实际爬取操作前,必须从浏览器开发者工具中复制真实的Cookie信息并添加到请求头中,这是绕过基础反爬策略的必要前提条件。
作业3
爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
1)代码:
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
import time
from urllib.parse import urljoin
# 待抓取的新闻页面列表
news_pages = [
"https://news.fzu.edu.cn/yxfd.htm",
"https://news.fzu.edu.cn/yxfd/1.htm",
"https://news.fzu.edu.cn/yxfd/2.htm",
"https://news.fzu.edu.cn/yxfd/3.htm",
"https://news.fzu.edu.cn/yxfd/4.htm",
"https://news.fzu.edu.cn/yxfd/5.htm"
]
# 图片存储配置
IMAGE_FOLDER = "fzu_news_images"
downloaded_images = 0
# 自动创建图片目录
os.makedirs(IMAGE_FOLDER, exist_ok=True)
print(f"图片存储目录已创建:{IMAGE_FOLDER}")
def save_image(image_url, page_index):
"""下载并保存单张新闻图片"""
global downloaded_images
# 配置请求头模拟浏览器访问
request_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/128.0.0.0 Safari/537.36"
}
try:
# 发起图片下载请求
img_response = requests.get(image_url, headers=request_headers, timeout=15)
img_response.raise_for_status()
# 生成规范化文件名
filename = image_url.split("/")[-1]
if "." not in filename:
filename = f"unnamed_{downloaded_images + 1}.jpg"
save_path = os.path.join(IMAGE_FOLDER, f"page_{page_index}_{filename}")
# 写入图片文件
with open(save_path, "wb") as img_file:
img_file.write(img_response.content)
downloaded_images += 1
print(f"[成功] 页面{page_index} - 图片{downloaded_images}: {filename}")
return True
except Exception as error:
print(f"[失败] 页面{page_index} 图片下载失败: {image_url}\n原因: {error}")
return False
def parse_news_page(page_url, page_index):
"""解析新闻页面并提取图片"""
print(f"\n开始处理页面 {page_index}: {page_url}")
# 配置请求头
request_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/128.0.0.0 Safari/537.36"
}
try:
# 获取页面内容
page_response = requests.get(page_url, headers=request_headers, timeout=15)
page_response.encoding = page_response.apparent_encoding
# 解析HTML文档
html_parser = BeautifulSoup(page_response.text, "html.parser")
image_containers = html_parser.find_all("div", class_="img slow")
if not image_containers:
print(f"[提示] 页面{page_index} 未发现图片元素")
return
# 处理每个图片容器
for container in image_containers:
img_element = container.find("img")
if img_element and img_element.get("src"):
# 处理相对路径
full_image_url = urljoin(page_url, img_element["src"])
save_image(full_image_url, page_index)
time.sleep(1) # 请求间隔
print(f"[完成] 页面{page_index} 处理完毕")
except Exception as error:
print(f"[错误] 页面{page_index} 解析失败: {error}")
if __name__ == "__main__":
print("福州大学新闻图片抓取程序启动")
print(f"目标页面列表: {news_pages}")
# 遍历所有新闻页面
for idx, page_url in enumerate(news_pages, start=1):
parse_news_page(page_url, idx)
# 页面间延迟(除最后一页)
if idx < len(news_pages):
print("等待2秒后处理下一页...")
time.sleep(2)
# 输出统计信息
print("\n抓取任务完成!")
print(f"处理页面数: {len(news_pages)}")
print(f"成功下载图片数: {downloaded_images}")
print(f"图片存储路径: {os.path.abspath(IMAGE_FOLDER)}")

2)作业心得
在网页数据采集阶段,我采用urllib.request库构建带自定义请求头的HTTP请求,通过模拟浏览器行为(User-Agent伪装)有效规避了基础反爬机制,成功获取到完整的网页HTML源码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号