
HBase 架构与工作原理1 - HBase 的数据模型
本文系转载,如有侵权,请联系我:likui0913@gmail.com
一、应用场景
HBase 与 Google 的 BigTable 极为相似,可以说 HBase 就是根据 BigTable 设计的,这一点在 BigTable 论文中也能发现。
在 BigTable 论文中提到了它的应用场景:
BigTable 是一个分布式的结构化数据存储系统,它被设计用来处理海量数据:通常是分布在数千台普通服务器上的 PB 级的数据。
Google 的很多项目使用 Bigtable 存储数据,包括 Web 索引、Google Earth、Google Finance。这些应用对 Bigtable 提出的要求差异非常大,无论是在数据量上(从 URL 到网页到卫星图像)还是在响应速度上(从后 端的批量处理到实时数据服务)。
Bigtable 已经在超过 60 个 Google 的产品和项目上得到了应用,包括 Google Analytics、Google Finance、 Orkut、Personalized Search、Writely 和 Google Earth。
以上应用场景的一个典型特点就是会不断的插入新的数据,而不怎么修改,比如Web 索引、Google Earth。而同时呢,也可能需要保存一定的历史数据用以查看或分析,比如网页快照、Google Analytics、或者联想到如今的大数据中,根据您以往的行为来预测您的行为与喜好等。另外它存储的属性可能会很多且不固定,比如一个网页的数据,除了它的内容外,可能还需要存储它相关的外链、关键字、锚点、标题、图片等。
那么根据这些应用的需求,对 BigTable 中的数据总结有以下特点:
- 数据量大
- 属性不固定
- 插入多,但不存在频繁的修改
- 存在历史版本数据
二、Table 组成元素
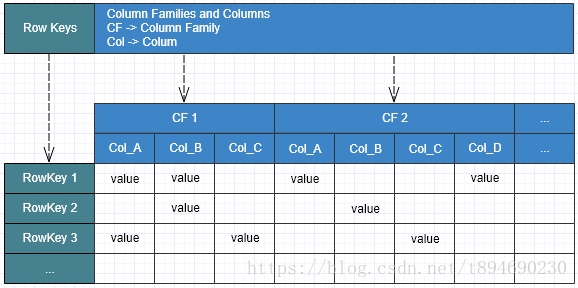
在 HBase 中,数据存储在具有行和列的表中,表的每行包含一个或多个列族,每个列族则可能包含一个或多个列,而行与列的交叉点则被称为单元格,用来存放数据的值。
表(Table)
Table 是在创建表时的 schema 声明定义的,其一旦创建便不可修改。
行(Row)
与传统关系系数据库类似却又不太相同,HBase 中的行具有如下特点:
- 行由一个或多个列族组成,每个列族包含一个或多个列,列可以动态添加;
- 每个行都包含一个行键(Rowkey),类似于关系型数据库中的主键。
- 行键是不可分割的字节数组,Table 中的行按照行键的字典序由低到高有序排列。
- 每行可以存储多个历史版本,默认读取的为最新的版本;
列族(Column Family)
列族是一个或多个列的集合,列可以动态增减,但是列族则需要在创建或修改表时提前定义。同一个列族下的所有列使用相同的前缀来标识其属于哪一个列族,比如列courses:history和courses:math都是列族courses的成员。
在物理存储上,一个列族下的所有成员在文件系统上是存储在一起的,这个原理对于之后的优化有着重要的意义。
单元格(Cells)
单元格是行与列的交叉点,同时因为版本的存在,所以它类似于一个3维元祖 {row, column, version},同行键一样,单元格中的内容也是不可分割的字节数组。
三、示例
以稍微修改过的 BigTable 论文中的 Webtable 为例:有一个名为 WebTable 的表格,其中包含两行(com.cnn.www 和 com.example.www)和三个名为 contents、anchor 和 people 的列族。对于第一行(com.cnn.www),anchor 包含两列(anchor:cssnsi.com,anchor:my.look.ca),contants 包含一列(contents:html)。同时,row key 为 com.cnn.www 的行保存了 5 个版本(5 个历史数据),row key 为 com.example.www 的行则只保存了 1 个版本。contents 列族中,html 列限定符中包含指定网站的整个 HTML 内容。anchor 列族中,每个限定符都包含链接到该行所代表的站点的外部站点,以及它在链接锚点(anchor)中使用的文本。people 列族中则保存与该网站相关的人员。
那么根据这个示例,可以得到如下的逻辑视图与物理视图。
逻辑视图
| Row Key | Time Stamp | ColumnFamily contents | ColumnFamily anchor | ColumnFamily people |
|---|---|---|---|---|
| “com.cnn.www” | t9 | anchor:cnnsi.com = “CNN” | ||
| “com.cnn.www” | t8 | anchor:my.look.ca = “CNN.com” | ||
| “com.cnn.www” | t6 | contents:html = “<html>…” | ||
| “com.cnn.www” | t5 | contents:html = “<html>…” | ||
| “com.cnn.www” | t3 | contents:html = “<html>…” | ||
| “com.example.www” | t5 | contents:html = “<html>…” | people:author = “John Doe” |
与传统的关系型数据库不同的是,此表中为空的单元格(Cell)在实际中并不会占用空间或者说事实上并不存在,这正是 HBase “稀疏”的原因。使用表格只是查看 HBase 数据的一种方式,同样也可以转换成 JSON 格式:
{
"com.cnn.www": {
contents: {
t6: contents:html: "<html>..."
t5: contents:html: "<html>..."
t3: contents:html: "<html>..."
}
anchor: {
t9: anchor:cnnsi.com = "CNN"
t8: anchor:my.look.ca = "CNN.com"
}
people: {}
}
"com.example.www": {
contents: {
t5: contents:html: "<html>..."
}
anchor: {}
people: {
t5: people:author: "John Doe"
}
}
}
物理视图
HBase 的数据按照列族(cloumn family)物理存储。也即是说不同列族下的数据被分开存放,您可以随时将新的列限定符(column_family:column_qualifier)添加到现有的列族。对应上面的示例,它的物理存储如下:
列族 anchor:
| Row Key | Time Stamp | Column Family anchor |
|---|---|---|
| “com.cnn.www” | t9 | anchor:cnnsi.com = “CNN” |
| “com.cnn.www” | t8 | anchor:my.look.ca = “CNN.com” |
列族 contents:
| Row Key | Time Stamp | Column Family contents |
|---|---|---|
| “com.cnn.www” | t6 | contents:html = “<html>…” |
| “com.cnn.www” | t5 | contents:html = “<html>…” |
| “com.cnn.www” | t3 | contents:html = “<html>…” |
列族 people:
| Row Key | Time Stamp | Column Family people |
|---|---|---|
| “com.example.www” | t5 | people:author = “John Doe” |
这样的物理视图有 3 个特点:
- 概念视图中的空的单元格不会被存储;
- 通过 Rowkey、时间戳、列族与限定符可以定位到一条数据;
- 如果未指定时间戳,将返回最新的数据。比如 get(RowKey=”com.cnn.www”, column_family:column_qualifier=”contents:html”),将返回 t6 时间的值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号