1.netty底层实现原理
1.netty:高性能、高并发网络应用框架。
2.如何做到高性能?高并发?
1.对NIO进行封装。
1.NIO:基于事件驱动,(单线程模型,多线程模型,主从模型)
3.selector:请求-->socket Channel-->selector(thread-->关注io读写事件)
1.Channel(它负责基本的 IO 操作,例如:bind(),connect(),read(),write() 等等。同时它也是数据入站和出站的载体)
2.EventLoop聚合了多路复用器Selector。消息的“出站”/“入站”就称为事件(Event)。
3.EventLoopGroup 要做的就是创建一个新的 Channel,并且生成一个EventLoop并分配给它。
4.ChannelHandler:EventLoop 是事件的通知者,那么 ChannelHandler 就是事件的处理者
5.ChannelPipeline:事件的处理顺序是由 ChannelPipeline 来决定的。到 Channel 被创建的时候,ChannelHandler 会被 Netty 框架自动分配到 ChannelPipeline 上。
6.ChannelHandlerContext:负责传递消息,每当有 ChannelHandler 添加到 ChannelPipeline 时,同时会创建 ChannelHandlerContext..
4.Netty 的数据容器:
5.Bootstrap 对象:Bootstrap 的作用就是将 Netty 核心组件配置到程序中,并且让他们运行起来。
优秀原文链接:https://blog.csdn.net/suifeng629/article/details/103500016
1.netty介绍:
1.定义:Netty 是一个异步的、基于事件驱动的网络应用框架,它可以用来开发高性能服务端和客户端。(实际并非异步)
2.为了满足高并发下网络请求,引入了 NIO 的概念。Netty 是针对 NIO 的实现,在 NIO 封装,网络调用,数据处理以及性能优化等方面都有不俗的表现。
3.Selector 机制就是 NIO 的核心。
1.当每次客户端请求时,会创建一个 Socket Channel,并将其注册到 Selector 上(多路复用器);
2.Selector 关注服务端 IO 读写事件,此时客户端并不用等待 IO 事件完成,可以继续做接下来的工作;
3.一旦,服务端完成了 IO 读写操作,Selector 会接到通知,同时告诉客户端 IO 操作已经完成;
4.接到通知的客户端,就可以通过 SocketChannel 获取需要的数据了。
2.netty的优点:
1.对 NIO 进行封装,开发者不需要关注 NIO 的底层原理,只需要调用 Netty 组件就能够完成工作。
2.对网络调用透明,从 Socket 建立 TCP 连接到网络异常的处理都做了包装。
3.对数据处理灵活, Netty 支持多种序列化框架,通过“ChannelHandler”机制,可以自定义“编/解码器”。
4.对性能调优友好,Netty 提供了线程池模式以及 Buffer 的重用机制(对象池化),不需要构建复杂的多线程模型和操作队列。
3.netty场景:
1.Netty 作为 NIO 的实现,它适用于服务器/客户端通讯的场景;
2.以及针对于 TCP 协议下的高并发应用。
2.netty核心组件:
1.Channel
1.当客户端和服务端连接的时候会建立一个 Channel。
2.这个 Channel 我们可以理解为 Socket 连接,它负责基本的 IO 操作,例如:bind(),connect(),read(),write() 等等。
3.简单的说,Channel 就是代表连接,同时它也是数据入站和出站的载体。
2.EventLoop 和 EventLoopGroup
1.EventLoop:消息的“出站”/“入站”就会产生事件(Event),那么就有一个机制去监控和协调事件。这个机制就是EventLoop。Netty的IO线程EventLoop聚合了多路复用器Selector。
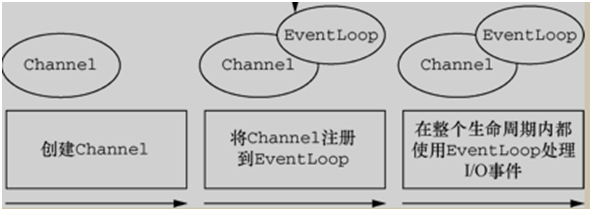
2.在 Netty 中每个 Channel 都会被分配到一个 EventLoop。
1.一个 EventLoop 可以服务于多个 Channel。
2.每个 EventLoop 会占用一个 Thread,同时这个 Thread 会处理 EventLoop 上面发生的所有 IO 操作和事件。
3.图形展示:(channel1、channel2、channel3)-eventloop-thread-(io,io,io)
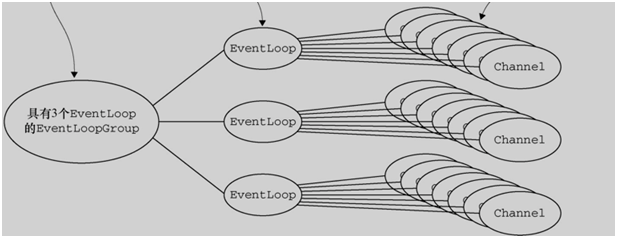
4.EventLoopGroup :
1.EventLoopGroup 要做的就是创建一个新的 Channel,并且生成一个EventLoop并分配给它。
2.一个 EventLoopGroup 中包含了多个 EventLoop 对象。
3.模拟请求流程
1.客户端发送消息到服务端,EventLoop 发现以后会告诉服务端:“你去获取消息”,同时客户端进行其他的工作。
2.当 EventLoop 检测到服务端返回的消息,也会通知客户端:“消息返回了,你去取吧“,客户端再去获取消息。
3.整个过程 EventLoop 就是监视器+传声筒。
3.ChannelHandler,ChannelPipeline 和 ChannelHandlerContext
1.ChannelHandler:EventLoop 是事件的通知者,那么 ChannelHandler 就是事件的处理者
1.ChannelHandler 中可以添加一些业务代码,例如数据转换,逻辑运算等等。
2.Server 和 Client 分别都有一个 ChannelHandler 来处理,读取信息,网络可用,网络异常之类的信息。
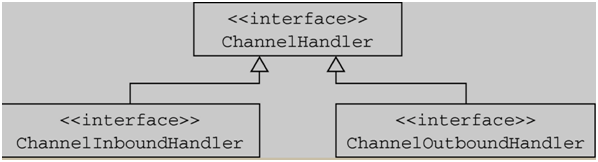
3.针对出站和入站的事件,有不同的 ChannelHandler。
1.ChannelInBoundHandler(入站事件处理器)
2.ChannelOutBoundHandler(出站事件处理器)
2.ChannelPipeline :事件的处理顺序是由 ChannelPipeline 来决定的。
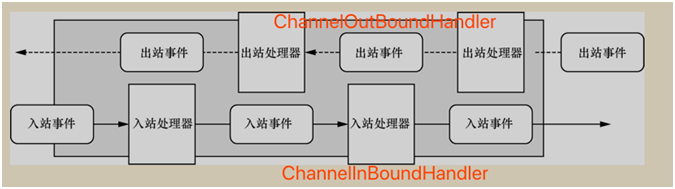
1.ChannelPipeline 为 ChannelHandler 链提供了容器。到 Channel 被创建的时候,会被 Netty 框架自动分配到 ChannelPipeline 上。
2.ChannelPipeline 保证 ChannelHandler 按照一定顺序处理事件,当事件触发以后,会将数据通过 ChannelPipeline 按照一定的顺序通过 ChannelHandler。
3.ChannelPipeline 也可以添加或者删除 ChannelHandler,管理整个队列。
3.ChannelHandlerContext :每当有 ChannelHandler 添加到 ChannelPipeline 时,同时会创建 ChannelHandlerContext.
1.ChannelHandlerContext 的主要功能是管理 ChannelHandler 和 ChannelPipeline 的交互,ChannelHandlerContext 负责传递消息.
2.ChannelHandlerContext 参数贯穿 ChannelPipeline,将信息传递给每个 ChannelHandler。如下图:
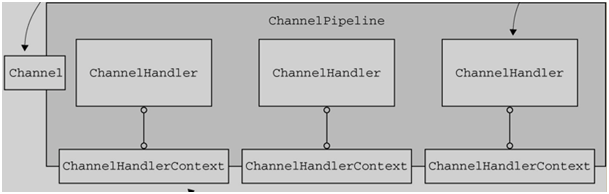
4.netty核心组件关系图:
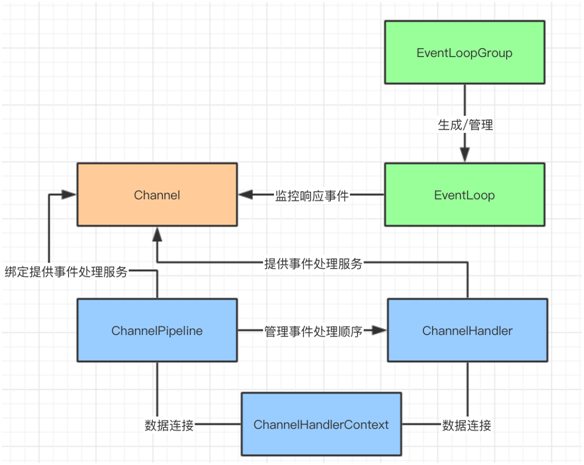
5.Netty 的数据容器:
1.ByteBuf 工作原理:
1.从结构上来说,ByteBuf 由一串字节数组构成。数组中每个字节用来存放信息。
2.ByteBuf 提供了两个索引,一个用于读取数据,一个用于写入数据。这两个索引通过在字节数组中移动,来定位需要读或者写信息的位置。
3.如果 readerIndex 超过了 writerIndex 的时候,Netty 会抛出 IndexOutOf-BoundsException 异常。
2.ByteBuf 使用模式:
1.堆缓冲区:
1.ByteBuf 将数据存储在 JVM 的堆中,通过数组实现,可以做到快速分配。
2.由于在堆上被 JVM 管理,在不被使用时可以快速释放。可以通过 ByteBuf.array() 来获取 byte[] 数据。
2.直接缓冲区:
1.在 JVM 的堆之外直接分配内存,用来存储数据。其不占用堆空间,使用时需要考虑内存容量。
2.它在使用 Socket 传递时性能较好,因为间接从缓冲区发送数据,在发送之前 JVM 会先将数据复制到直接缓冲区再进行发送。
3.直接缓冲区的数据分配在堆之外,通过 JVM 进行垃圾回收,并且分配时也需要做复制的操作,因此使用成本较高。
3.复合缓冲区:
1.顾名思义就是将上述两类缓冲区聚合在一起。Netty 提供了一个 CompsiteByteBuf,可以将堆缓冲区和直接缓冲区的数据放在一起,让使用更加方便。
3.ByteBuf 的分配
Netty 提供了两种 ByteBufAllocator 的实现
1.PooledByteBufAllocator,实现了 ByteBuf 的对象的池化,提高性能减少内存碎片。
1.对象池化的技术和线程池,比较相似,目的是提高内存的使用率。
2.池化技术简单实现思路:是在 JVM 堆内存上构建一层内存池,通过 allocate 方法获取内存池中的空间,通过 release 方法将空间归还给内存池。
3.池化技术算法优化:伙伴系统
1.用完全二叉树管理内存区域,左右节点互为伙伴,每个节点代表一个内存块。内存分配将大块内存不断二分,直到找到满足所需的最小内存分片。
2.内存释放会判断释放内存分片的伙伴(左右节点)是否空闲,如果空闲则将左右节点合成更大块内存。
2.Unpooled-ByteBufAllocator,没有实现对象的池化,每次会生成新的对象实例。
1.对象的生成和销毁,会大量地调用 allocate 和 release 方法,因此内存池面临碎片空间回收的问题,在频繁申请和释放空间后,内存池需要保证连续的内存空间,用于对象的分配。
2.对象生成和销毁算法优化:slab 系统,主要解决内存碎片问题,将大块内存按照一定内存大小进行等分,形成相等大小的内存片构成的内存集。
1.按照内存申请空间的大小,申请尽量小块内存或者其整数倍的内存,释放内存时,也是将内存分片归还给内存集。
6.Bootstrap 对象
1.描述:Bootstrap 的作用就是将 Netty 核心组件配置到程序中,并且让他们运行起来。
2.结构:从 Bootstrap 的继承结构来看,Bootstrap 和 ServerBootstrap,一个对应客户端的引导,另一个对应服务端的引导
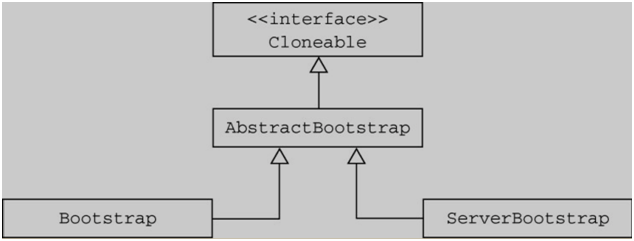
3.客户端引导 Bootstrap:
主要有两个方法 bind() 和 connect()。
1.Bootstrap 通过 bind() 方法创建一个 Channel。
2.在 bind() 之后,通过调用 connect() 方法来创建 Channel 连接。
3.Bootstrap(客户端引导)只要知道服务端 IP 和 Port 建立连接就可以了.
4.Bootstrap(客户端引导)需要一个 EventLoopGroup.
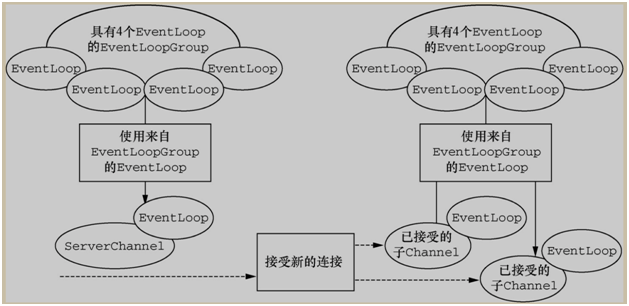
4.服务端引导 ServerBootstrap:
1.与客户端不同的是在 Bind() 方法之后会创建一个 ServerChannel;
2.这个ServerChannel不仅会创建新的 Channel 还会管理已经存在的 Channel。
3.ServerBootstrap(服务端引导)绑定一个端口,用来监听客户端的连接请求.
4.ServerBootstrap(服务端引导)则需要两个 EventLoopGroup.
因为服务器需要两组不同的 Channel.
1.第一组 ServerChannel 自身监听本地端口的套接字。
2.第二组用来监听客户端请求的套接字。
3.netty调用流程,代码实现
假设有一个客户端去调用一个服务端,假设服务端叫做 EchoServer,客户端叫做 EchoClient,用 Netty 架构实现代码如下。
1.服务端代码:
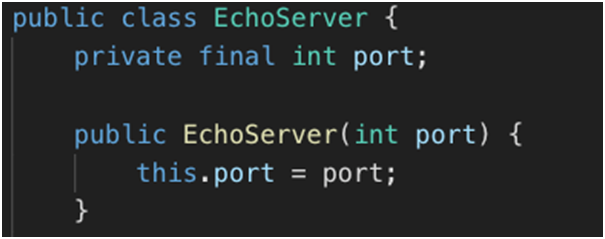
1.构建服务器端,假设服务器接受客户端传来的信息。在构造函数中传入需要监听的端口号。
2.接下来就是服务的启动方法:
1.启动 NettyServer 的 Start 方法
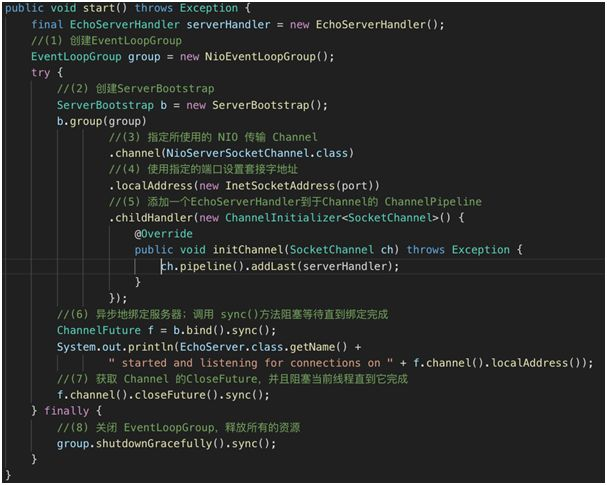
2.方法做了如下事:
1.创建 EventLoopGroup。
2.创建 ServerBootstrap。
3.指定所使用的 NIO 传输 Channel。
4.使用指定的端口设置套接字地址。
5.添加一个 ServerHandler 到 Channel 的 ChannelPipeline。
6.异步地绑定服务器;调用 sync() 方法阻塞等待直到绑定完成。
7.获取 Channel 的 CloseFuture,并且阻塞当前线程直到它完成。
8.关闭 EventLoopGroup,释放所有的资源。
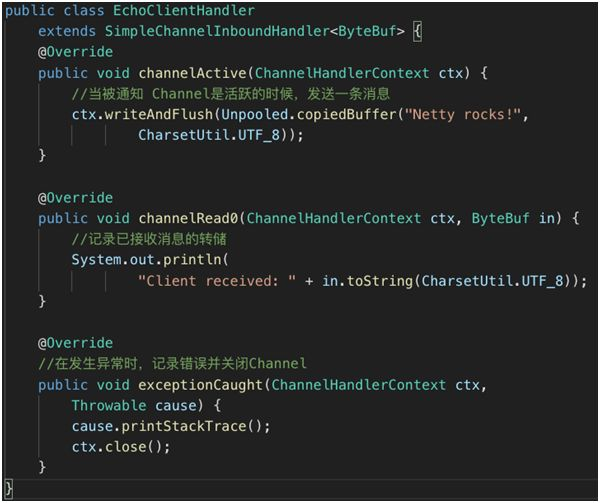
3.NettyServer 启动以后会监听某个端口的请求,当接受到了请求就需要处理了。
1.可以通过 ChannelInboundHandlerAdapter 实现
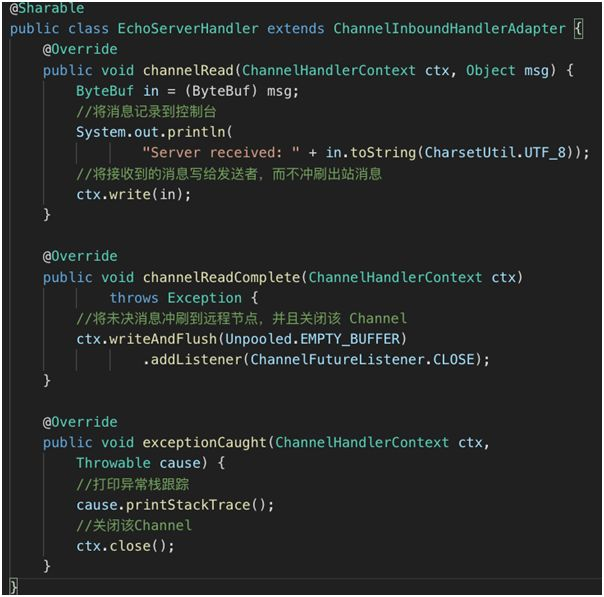
2.上图这三个方法都是根据事件触发的
1.当接收到消息时的操作,channelRead。
2.消息读取完成时的方法,channelReadComplete。
3.出现异常时的方法,exceptionCaught。
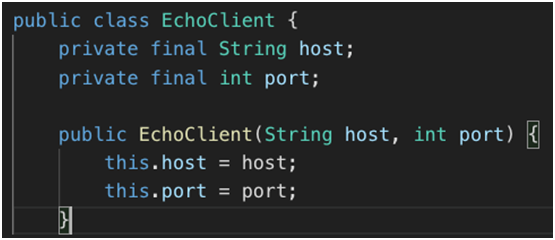
2.客户端代码:
1.客户端和服务端的代码基本相似,在初始化时需要输入服务端的 IP 和 Port。如下图
2.同样在客户端启动函数中包括以下内容:如下图
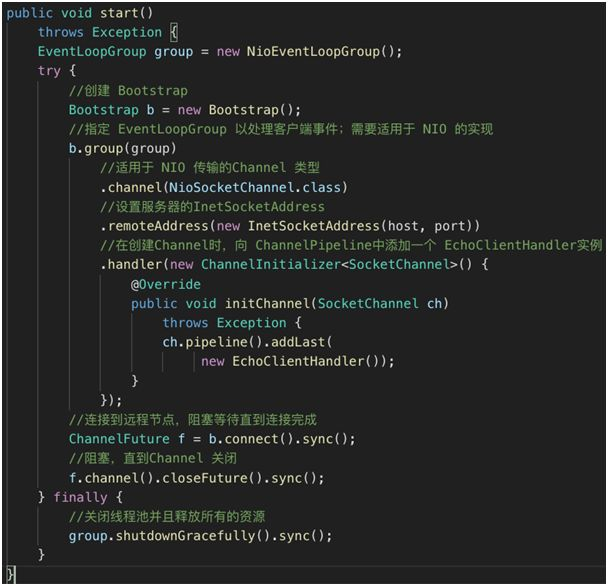
1.上图客户端启动程序的顺序如下:
1.创建 Bootstrap。
2.指定 EventLoopGroup 用来监听事件。
3.定义 Channel 的传输模式为 NIO(Non-BlockingInputOutput)。
4.设置服务器的 InetSocketAddress。
5.在创建 Channel 时,向 ChannelPipeline 中添加一个 EchoClientHandler 实例。
6.连接到远程节点,阻塞等待直到连接完成。
7.阻塞,直到 Channel 关闭。
8.关闭线程池并且释放所有的资源。
3.客户端在完成以上操作以后,会与服务端建立连接从而传输数据。同样在接受到 Channel 中触发的事件时,客户端会触发对应事件的操作。
4.io/nio/bio/reactor(多路复用模式)/netty的区别:
原文网址:https://www.cnblogs.com/crazymakercircle/p/10225159.html
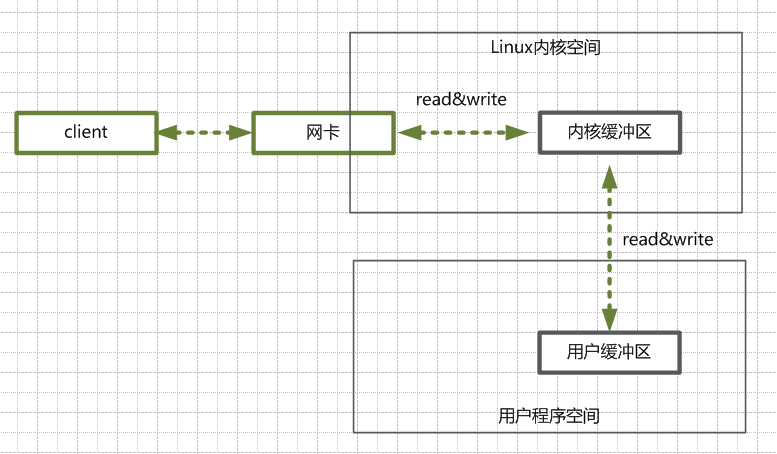
java IO读写的底层流程:
阻塞io:
1.含义:指的是需要内核IO操作彻底完成后,才返回到用户空间,执行用户的操作.
2.描述:阻塞指的是用户空间程序的执行状态,用户空间程序需等到IO操作彻底完成。
非阻塞io:
1.含义:指的是用户程序不需要等待内核IO操作完成后,内核立即返回给用户一个状态值,用户空间无需等到内核的IO操作彻底完成,可以立即返回用户空间。
2.描述:执行用户的操作,处于非阻塞的状态。
1.同步阻塞io(blocking io)-bio:
1.优点:程序简单,在阻塞等待数据期间,用户线程挂起。用户线程基本不会占用 CPU 资源。
2.缺点:BIO模型在高并发场景下是不可用的。
2.同步非阻塞io(Non-blocking IO)-nio:
1.优点:每次发起的 IO 系统调用,在内核的等待数据过程中可以立即返回。用户线程不会阻塞,实时性较好。
2.缺点:需要不断的重复发起IO系统调用,这种不断的轮询,将会不断地询问内核,这将占用大量的 CPU 时间,系统资源利用率较低。NIO模型在高并发场景下,也是不可用的。
3.io多路复用(io Multiplexing):经典的Reactor设计模式。
1.异步阻塞IO,Java中的Selector和Linux中的epoll都是这种模型。
2.目前支持IO多路复用的系统调用有 select,epoll等等。
3.基本原理:IO多路复用模型的基本原理就是select/epoll系统调用,单个线程不断的轮询select/epoll系统调用所负责的成百上千的socket连接,当某个或者某些socket网络连接有数据到达了,就返回这些可以读写的连接。
4.优点:用select/epoll的优势在于,它可以同时处理成千上万个连接(connection),系统不必创建线程,也不必维护这些线程,从而大大减小了系统的开销。
4.异步Io:
1.描述:有点类似于Java中比较典型的模式是回调模式。
5.select/poll/epoll的区别:
原文链接:https://blog.csdn.net/h2604396739/article/details/82534253
三种方式区别
1..select的几大缺点:
1.每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大;
2.同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大;
3.select支持的文件描述符数量太小了,默认是1024.
2.poll实现
poll的实现和select非常相似,只是描述fd集合的方式不同,poll使用pollfd结构而不是select的fd_set结构.
3.epoll(reference Link)
epoll既然是对select和poll的改进,就应该能避免上述的三个缺点。那epoll都是怎么解决的呢?在此之前,我们先看一下epoll和select和poll的调用接口上的不同,select和poll都只提供了一个函数——select或者poll函数。而epoll提供了三个函数, epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄;epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。
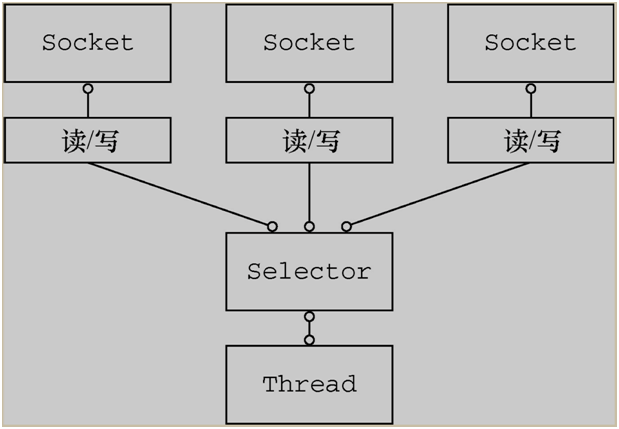
6.Java的NIO(new io)技术,使用的就是IO多路复用模型,在linux系统上,使用的是epoll系统调用。
1.new io原理:https://www.cnblogs.com/funyoung/p/11810581.html
1.NIO主要有三个核心部分:Selector、Channel、Buffer
2.数据总是从Channel读取到Buffer或者从Buffer写入到Channel中。
3.Selector可以监听多个Channel的多个事件。
2.传统的IO与Channel的区别:
1.传统的IO是BIO的,而Channel是NIO的。
*当流调用了read()、write()方法后会一直阻塞线程直到数据被读取或写入完毕。
2.传统IO流是单向的,而Channel是双向的。
7.Reactor模式原理:
1.Reactor模式是在NIO下实现的
2.Reactor有三种模式:
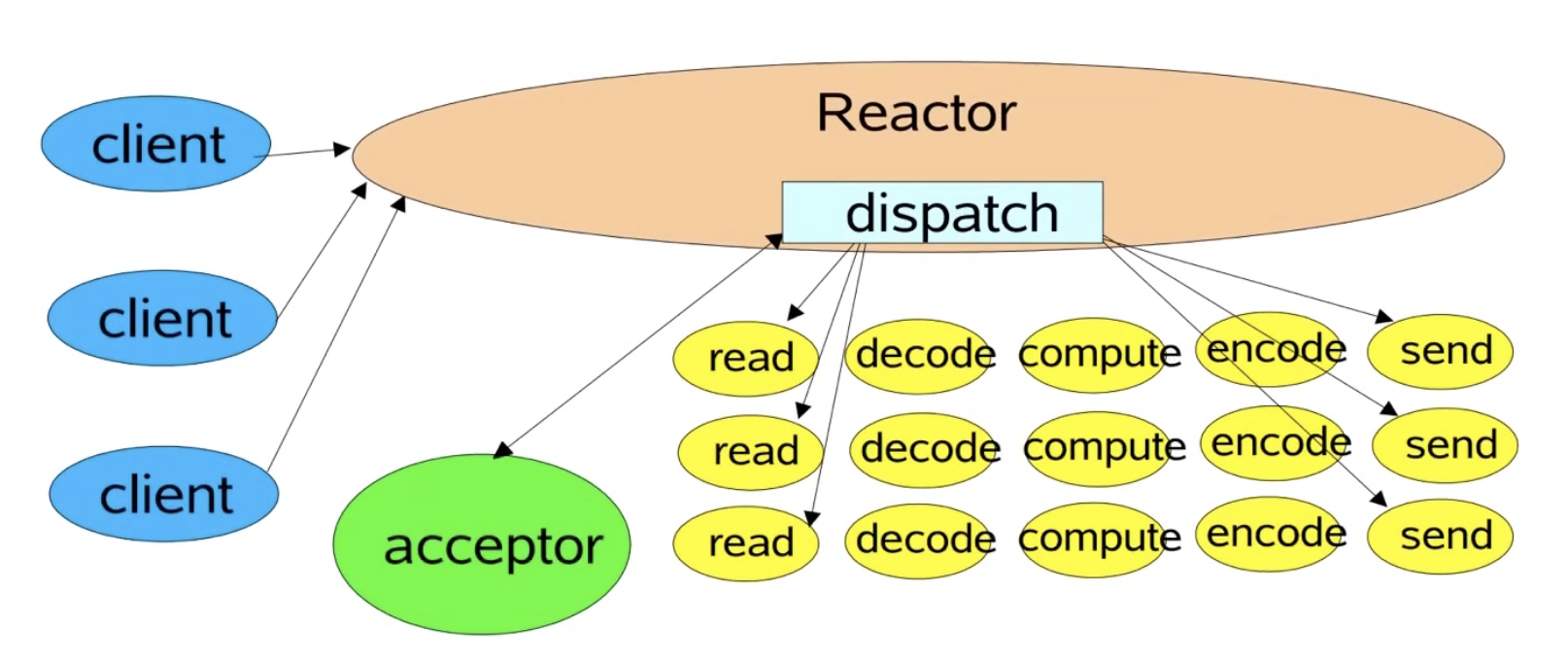
1.Reactor单线程模式
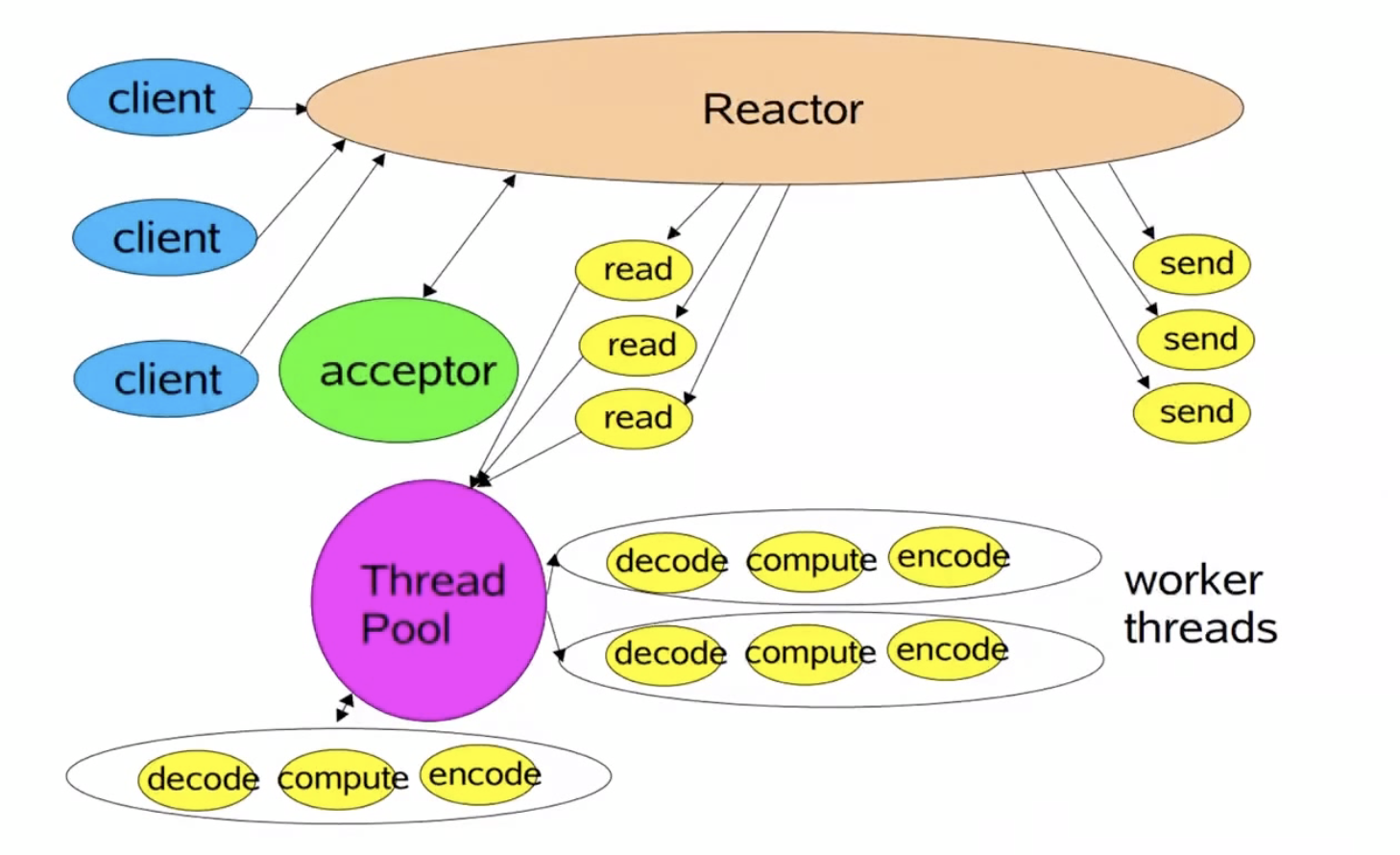
2.Reactor多线程模式
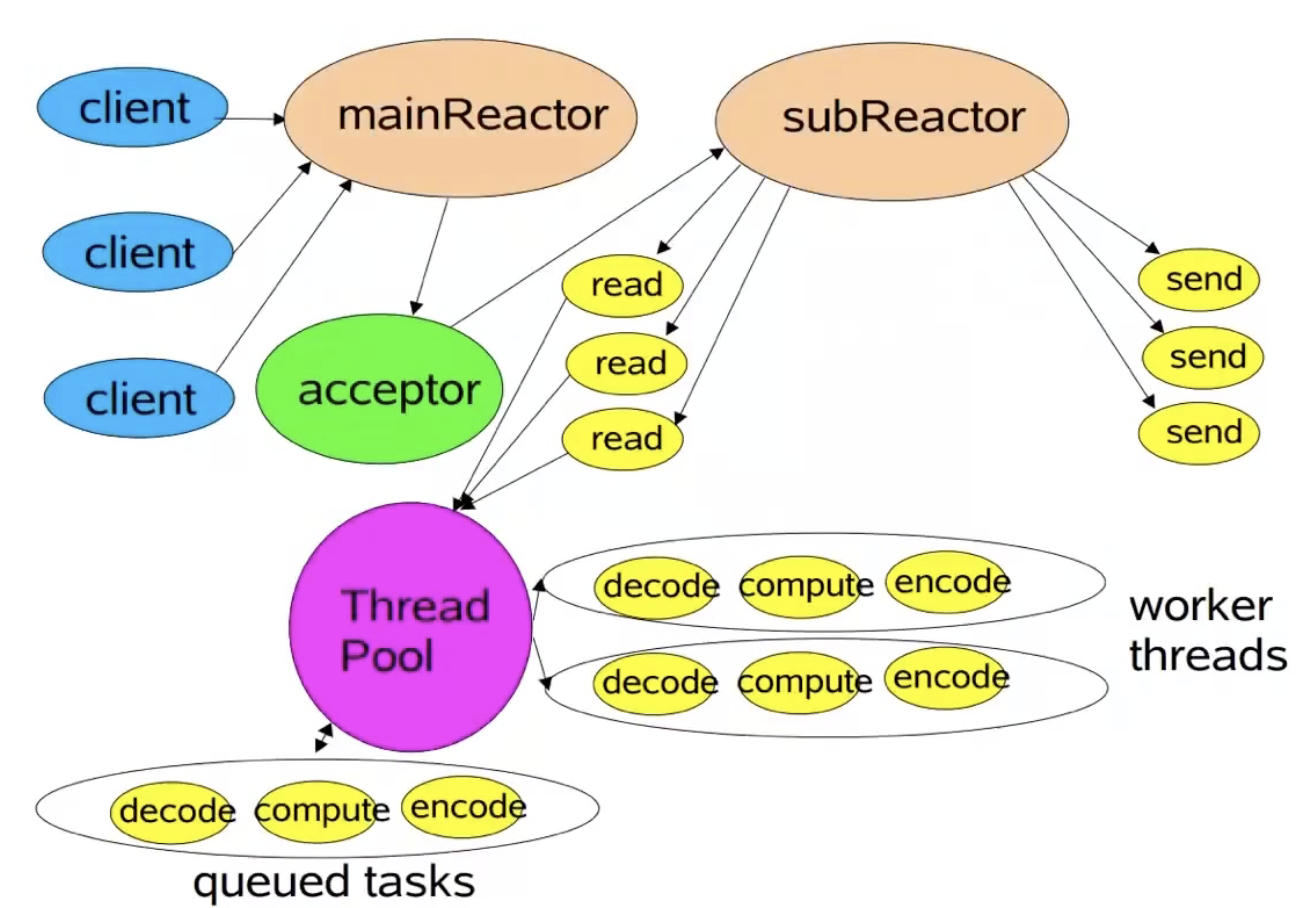
3.主从Reactor多线程模式