
1.框架设计:原文链接http://www.cnblogs.com/cyfonly/
1.框架整体流程:
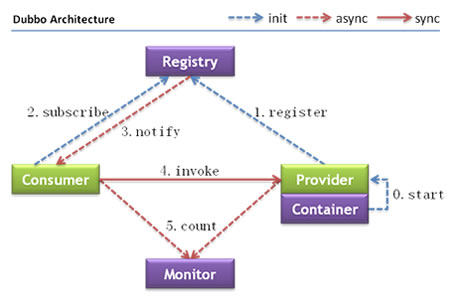
2.整体设计图:
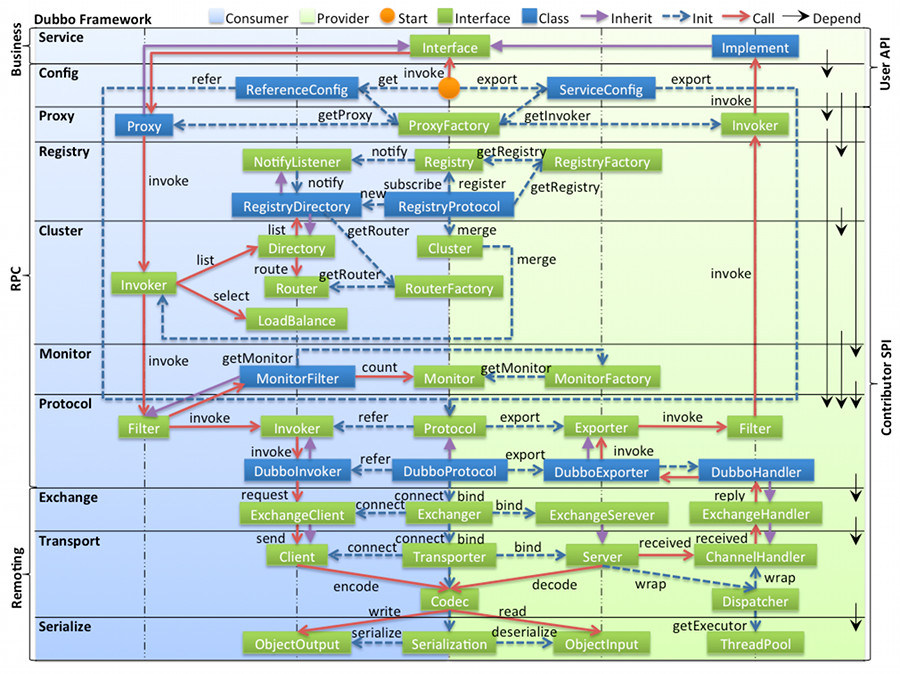
2.服务引用:
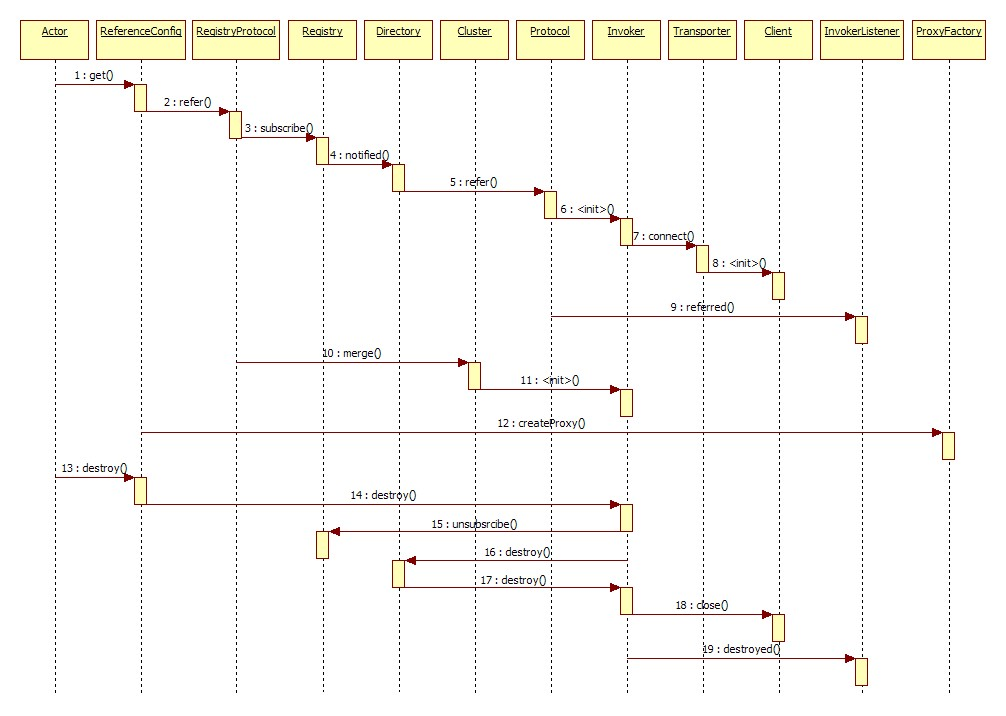
1服务引用时序图:
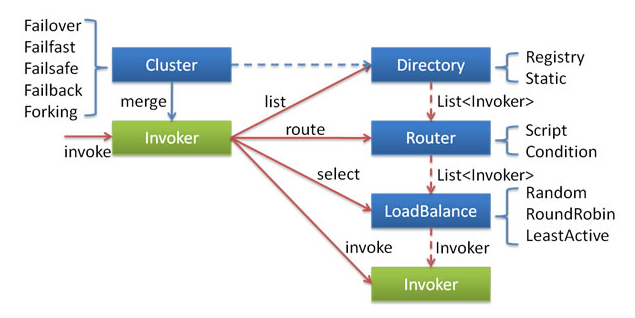
2.服务引用得各功能组件关系图:
3.源码和原理解析:
1.创建代理:
1,描述
1.Dubbo 基于 Spring 的 Schema 扩展实现 XML 配置解析,
2.DubboNamespaceHandler 会将 <dubbo:reference> 标签解析为 ReferenceBean,ReferenceBean 实现了 FactoryBean,
3.当它在代码中有引用时,会调用 ReferenceBean#getObject() 方法进入节点注册和服务发现流程。
2.ReferenceBean.java

3.ReferenceConfig.java
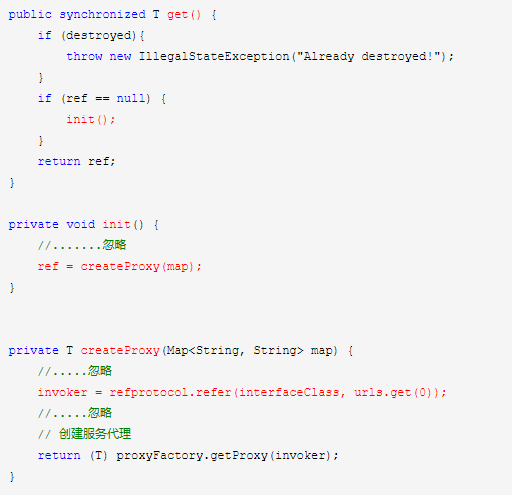
2.服务发现:
1.描述:因为通过注册中心,因此在 ReferenceConfig.java#createProxy() 方法中,进入 RegistryProtocol.java#refer() 方法。
2.RegistryProtocol.java
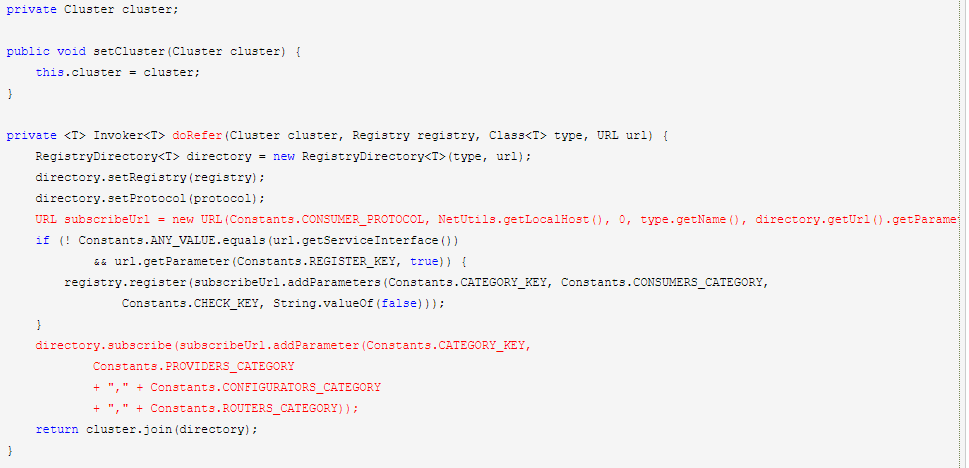
3.Invoker选取:
1.cluster:
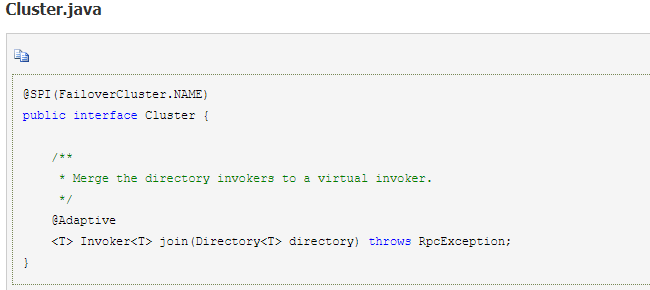
1.cluster 的类型是 Cluster$Adaptive,实际上是一个通用的代理类;
2.它会根据 URL 中的 cluster 参数值定位到实际的 Cluster 实现类(默认是 FailoverCluster);
3. 由于 ExtensionLoader 在实例化对象时,会在实例化完成之后自动套上 Wrapper 类,而 MockerClusterWrapper 就是这样一个 Wrapper。
2.MockerClusterWrapper.java

1.实例化出来的 FailoverCluster 会作为参数赋予 MockerClusterWrapper#cluster,而 MockClusterWrapper 会作为参数赋予 RegistryProtocol#cluster。
2. RegistryProtocol#doRefer() 中调用 cluster.join(directory) 实际上是调用的 MockClusterWrapper#join(directory)。 使用这种机制,可以把一些公共的处理放在 Wrapper 类中,实现代码和功能收敛。
3.MockClusterInvoker.java

1.Dubbo 另外一个核心机制——Mock:
1.Mock 可以在测试中模拟服务调用的各种异常情况,还用来实现服务降级。
2.从 MockClusterWrapper.join() 方法可知,实际创建的 ClusterInvoker 是封装了 FailoverClusterInvoker 的 MockerClusterInvoker。
3.调用步骤:
1.调用之前 Dubbo 会先检查 URL 中是否有 mock 参数(通过服务治理后台 Consumer 端的屏蔽和容错进行设置,或者直接动态设置 mock 参数值);
2.如果存在且以 force 开头,则不发起远程调用直接执行降级逻辑;
3.如果存在且以 fail 开头,则在远程调用异常时才会执行降级逻辑。
4.Directory:
1.在 RegistryProtocol#doRefer() 中可以看到,服务发现过程是通过 RegistryDirectory 向 Zookeeper 订阅来实现的;
2.Directory 类之间的关系:

1. ReferenceConfig#createProxy() 方法可知,StaticDirectory 主要用于多注册中心引用的场景,它的 invoker 列表是通过参数传入的、固定的。
2.RegistryDirectory 用于使用单注册中心发现服务的场景。
3.AbstractDirectory.java
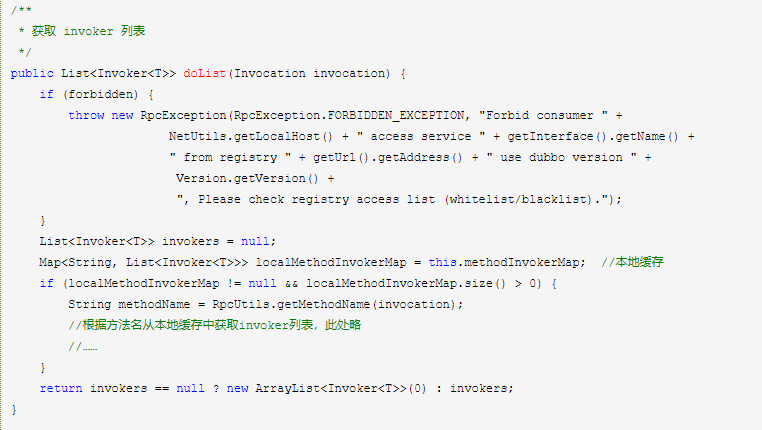
4.RegistryDirectory
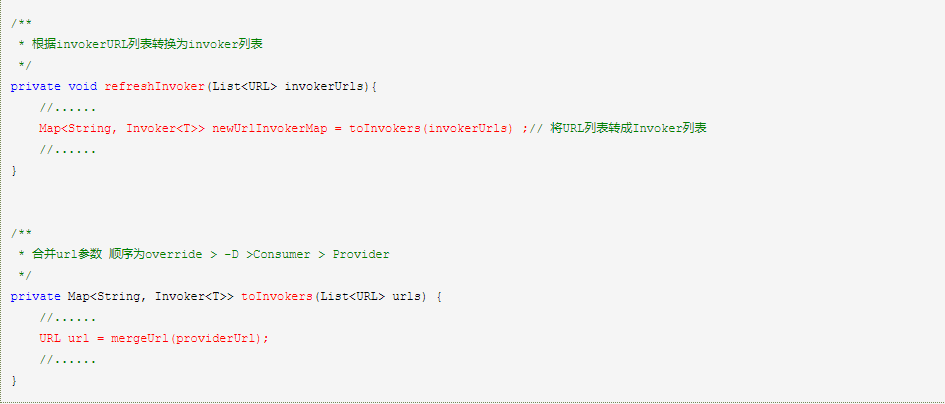
RegistryDirectory 实现了 NotifyListener,在 ZK 节点变化时能收到通知更新内存缓存,其中 RegistryDirectory#mergeUrl() 方法中会按照优先级合并参数(动态配置在此处生效)。
1.
2.

3.
3.Router
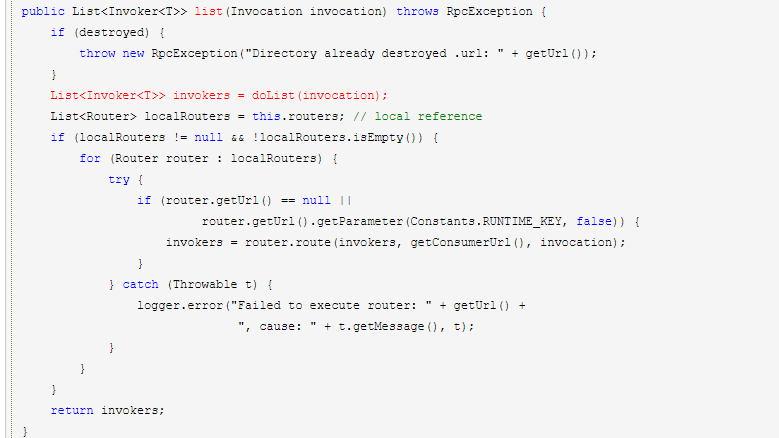
1.Router 的作用就是从 Directory 的 invoker 列表中刷选出符合路由规则的 invoker 子集。目前 Dubbo 提供了基于IP、应用名和协议等的静态路由功能,功能和实现比较简单,在此不做过多解释。
4.LoadBalance
1.通过 Direcotry 和 Router 之后,返回的是可用的 invoker 子集;在发起服务调用时,需要通过 LoadBalance 选择最终的一个目标 invoker。
2.调用时首先会经过 MockerClusterInvoker 拦截 Mock 设置,然后再根据配置调用实际的 Invoker(默认是 FailoverClusterInvoker);
3.FailoverClusterInvoker 继承 AbstractClusterInvoker
1.AbstractClusterInvoker

2.FailoverClusterInvoker

3.配置方式:
1。XML 配置:基于 Spring 的 Schema 和 XML 扩展机制实现
1.Dubbo 配置相关的代码在 dubbo-config 模块。
2.配置步骤:
1.定义 Schema(编写 .xsd 文件)
2.定义 JavaBean
3.编写 NamespaceHandler 和 BeanDefinitionParser 完成 Schema 解析
4.编写 spring.handlers 和 spring.schemas 文件串联解析部件
5.在 XML 文件中应用配置
3、Schema :Schema定义体现在 .xsd 文件上,文件位于 dubbo-config-spring 子模块下
4.javaBean:dubbo-config-api 子模块中定义了 Dubbo 所有标签对应的 JavaBean,JavaBean 里面的属性一一对应标签的各配置项
5.Schema的解析通过 DubboNamespaceHandler 和 DubboBeanDefinitionParser 实现
1.DubboNamespaceHandler 扩展了 Spring 的 NamespaceHandlerSupport,通过重写它的 init() 方法给各个标签注册对应的解析器:
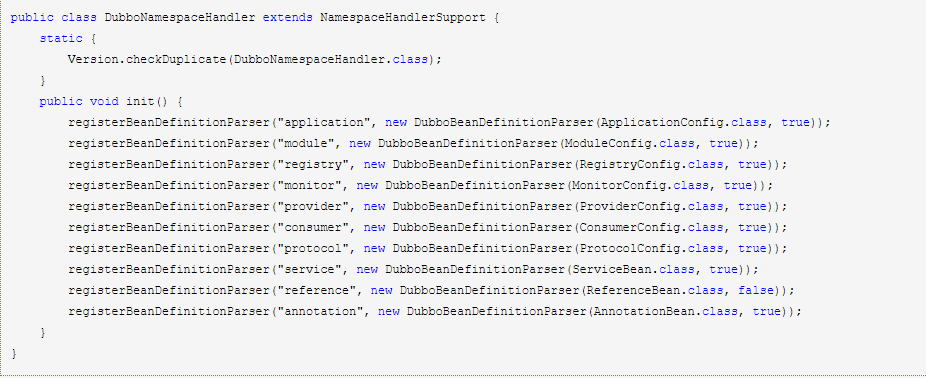
2.DubboBeanDefinitionParser 实现了 Spring 的 BeanDefinitionParser,通过重写 parse() 方法实现将标签解析为对应的 JavaBean:

2.属性配置:加载 classpath 根目录下的 dubbo.properties
3.API 配置:通过硬编码方式配置(不推荐使用)
4.注解配置:通过注解方式配置(Dubbo-2.5.7及以上版本支持,不推荐使用)
4.串联部件
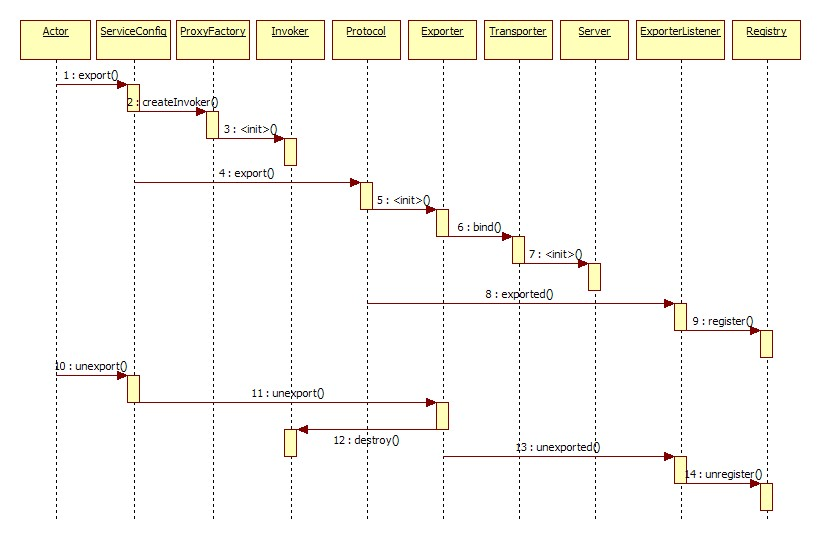
5.服务暴露流程:
1.服务暴露时序图
2.ServiceBean:
1.ServiceBean 实现了 InitializingBean,在类加载完成之后会调用 afterPropertiesSet() 方法。在 afterPropertiesSet() 方法中,依次解析以下标签信息:
1.<dubbo:provider>
2.<dubbo:application>
3.<dubbo:module>
4.<dubbo:registry>
5.<dubbo:monitor>
6.<dubbo:protocol>
2。ServiceBean 还实现了 ApplicationListener,在 Spring 容器初始化的时候会调用 onApplicationEvent 方法。ServiceBean 重写了 onApplicationEvent 方法,实现了服务暴露的功能。
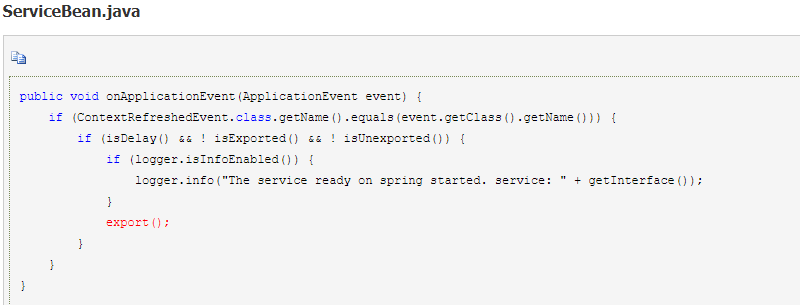
3.延迟暴露
1.ServiceBean 扩展了 ServiceConfig,调用 export() 方法时由 ServiceConfig 完成服务暴露的功能实现。
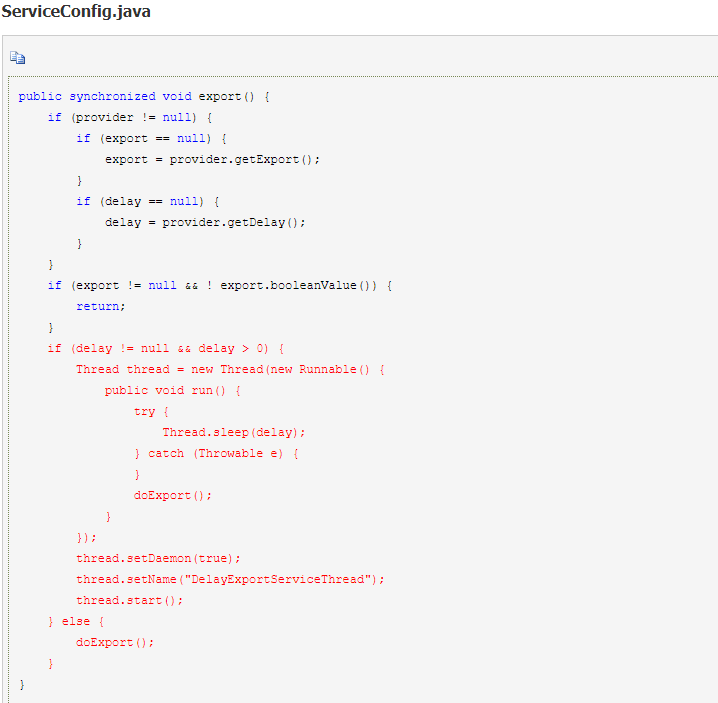
4.参数检查:
1.在 ServiceConfig 的 doExport() 方法中会进行参数检查和设置:
1.泛化调用
2.本地实现
3.本地存根
4.本地伪装
5.配置(application、registry、protocol等)
2.ServiceConfig


5. 多协议、多注册中心
1.在检查完参数之后,开始暴露服务。Dubbo 支持多协议和多注册中心;
2.
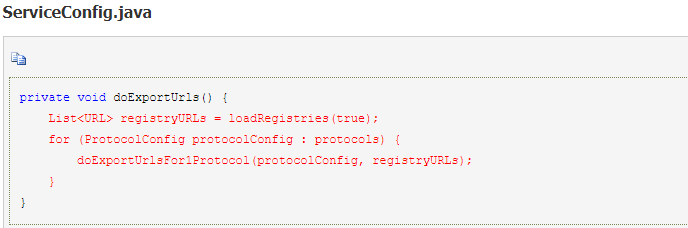
6.组装URL
1.针对每个协议、每个注册中心,开始组装 URL。
2.
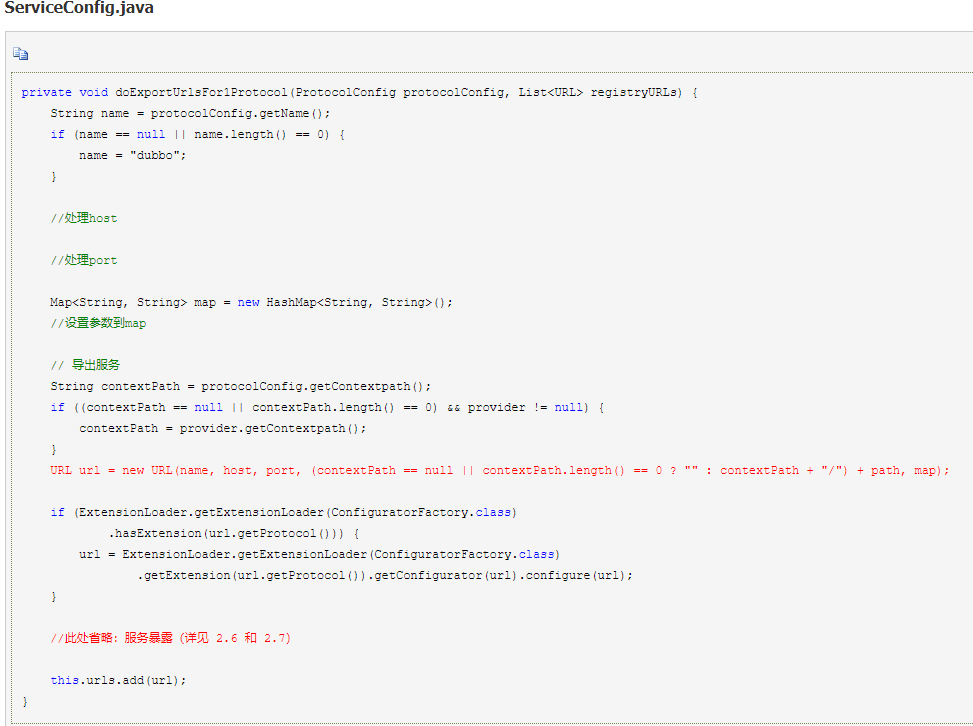
7.本地暴露:
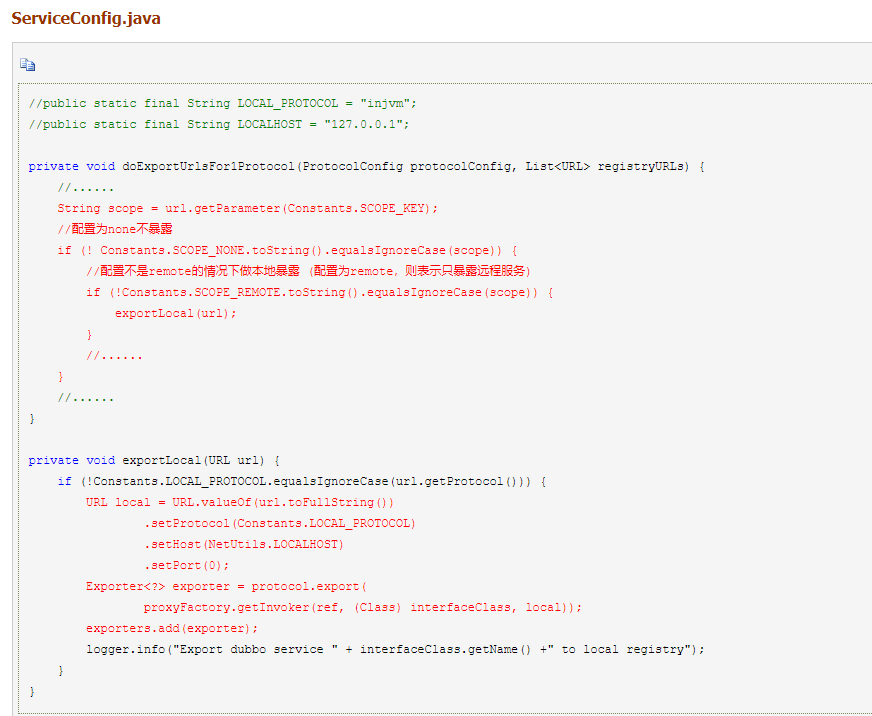
1,如果配置 scope=none, 则不会进行服务暴露;如果没有配置 scope 或者 scope=local,则会进行本地暴露。
2. 暴露服务的时候,会通过代理创建 Invoker;
3.. 本地暴露时使用 injvm 协议,injvm 协议是一个伪协议,它不开启端口,不能被远程调用,只在 JVM 内直接关联,但执行 Dubbo 的 Filter 链。
4.
8.远程暴露:
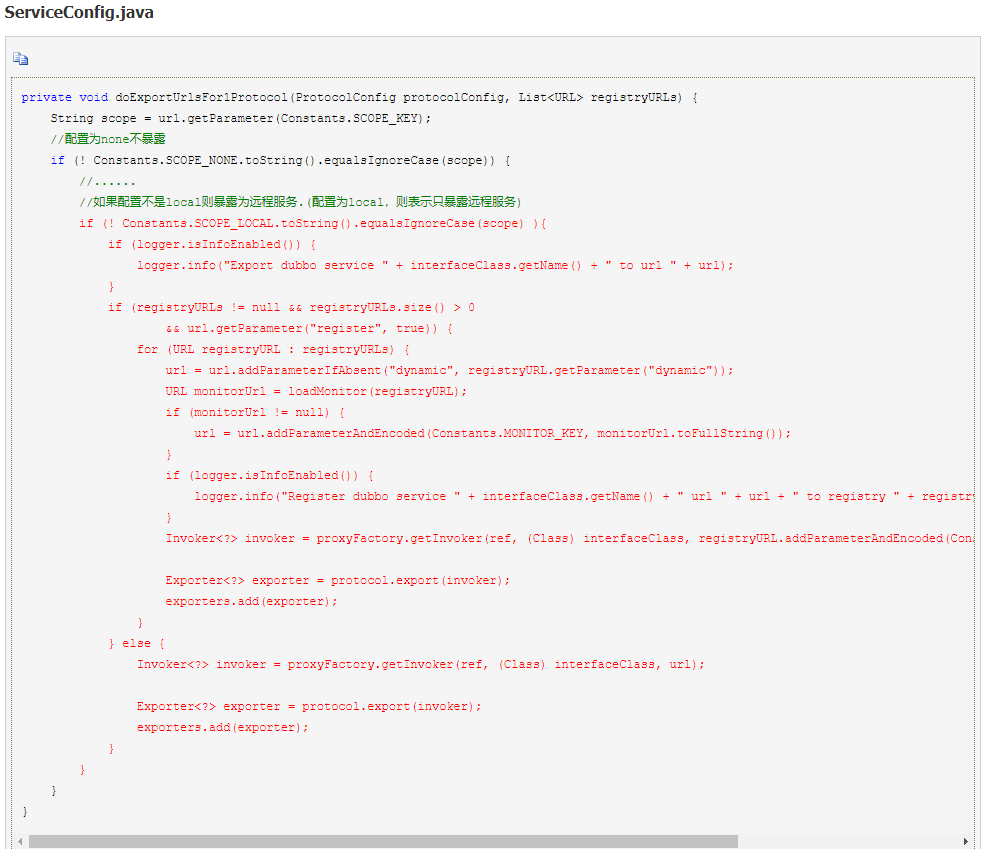
1.如果没有配置 scope 或者 scope=remote,则会进行远程暴露。
2.在服务暴露时,有两种情况:
1.不使用注册中心:直接暴露对应协议的服务,引用服务时只能通过直连方式引用
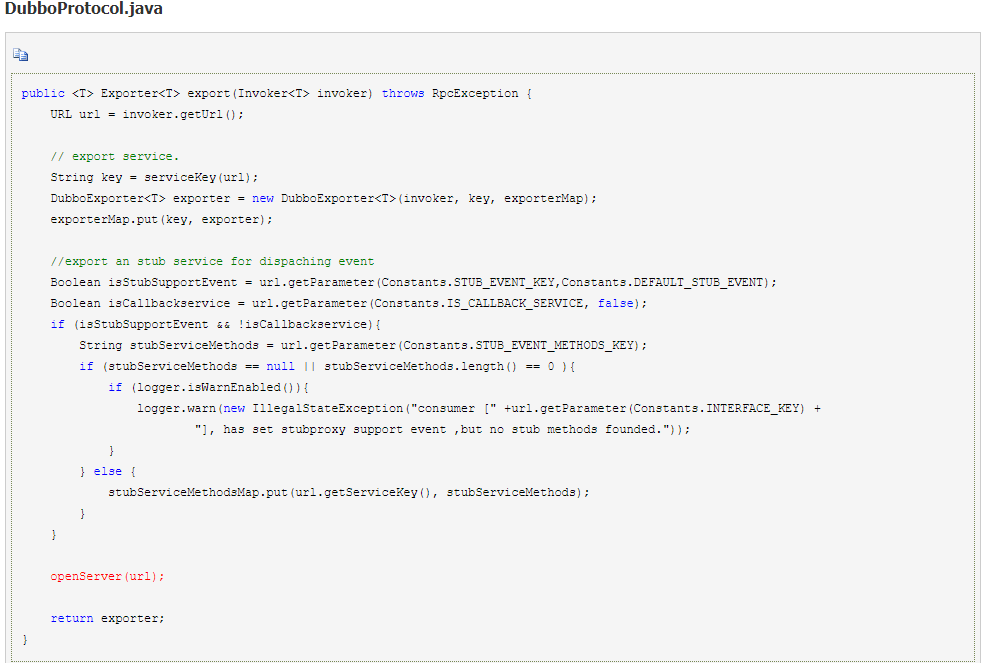
1.以 Dubbo 协议为例:直接调用对应协议的 export() 暴露服务
2.
3.调用 openServer() 方法创建并启动 Server:
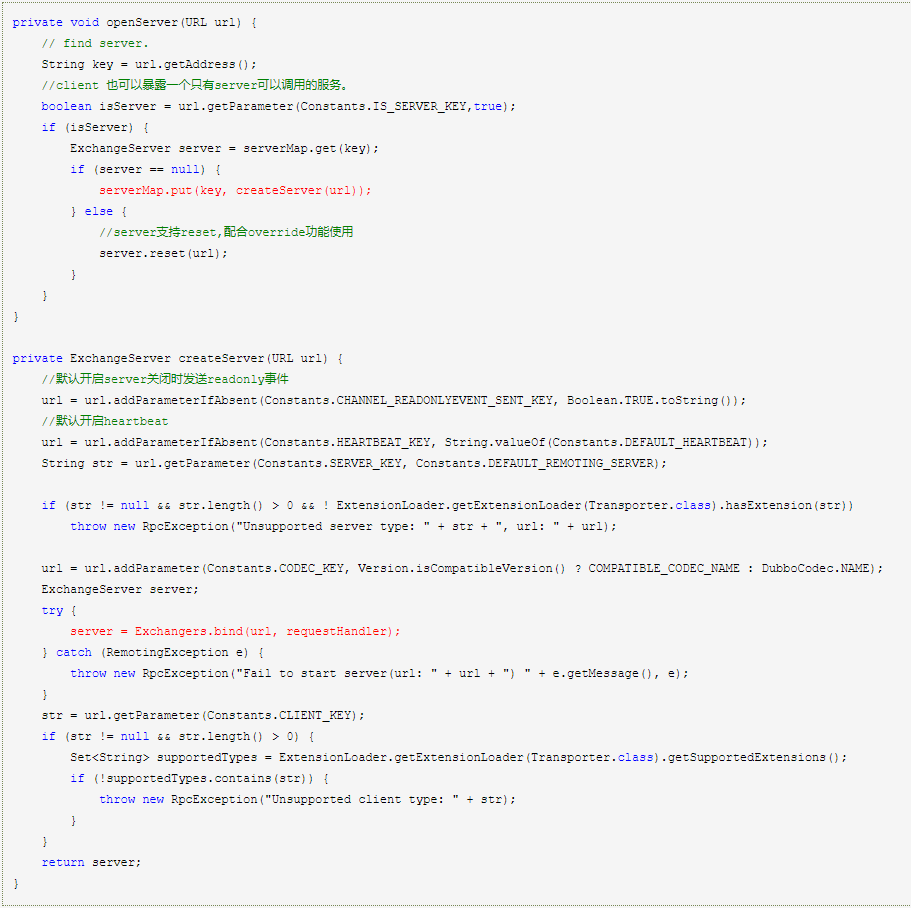
4.
5.Exchanger (默认 HeaderExchanger)封装请求响应模式,同步转异步,以 Request、Response 为中心:

6.Transporters.java
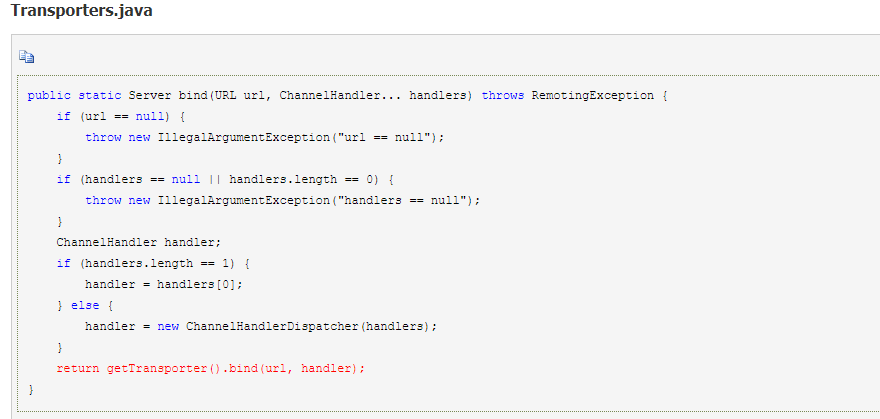
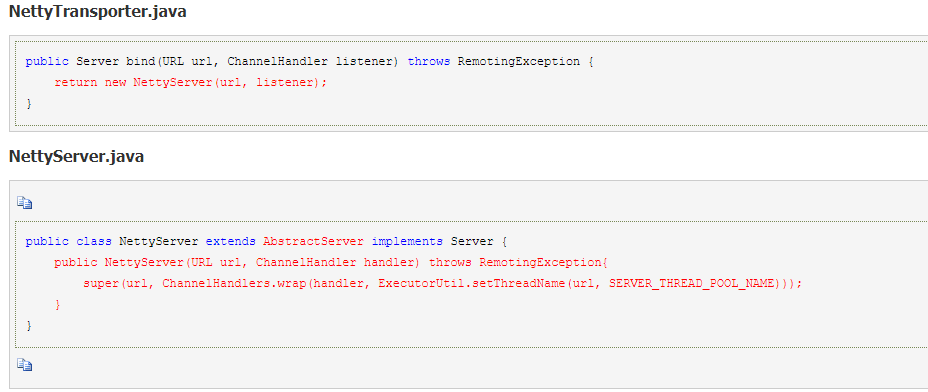
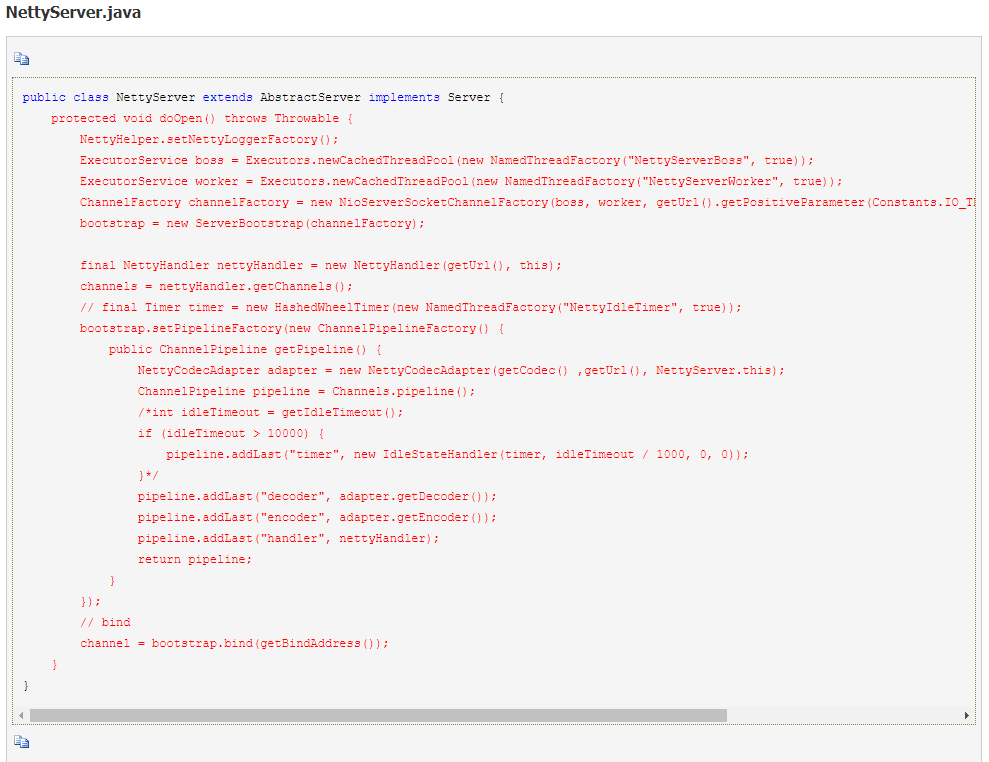
7.底层传输默认使用 NettyTransporter,最终是创建 NettyServer:

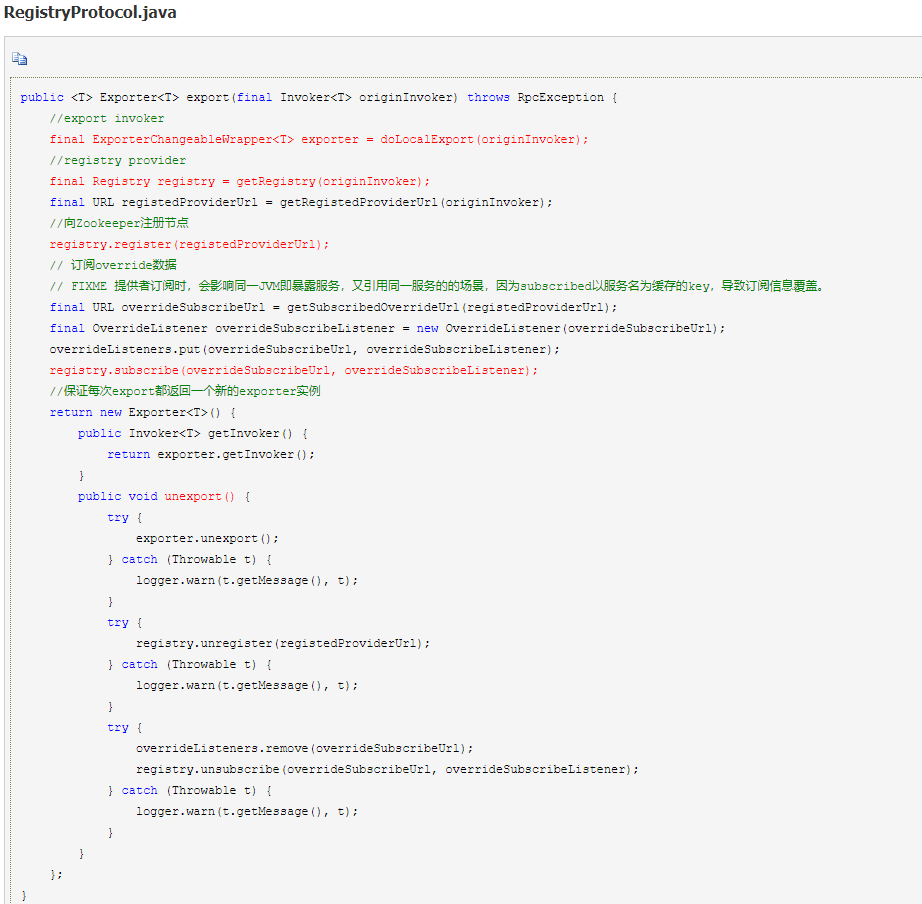
2。使用注册中心:暴露对应协议的服务后,会将服务节点注册到注册中心,引用服务时可以通过注册中心动态获取服务提供者列表,也可以通过直连方式引用;
1.getRegistry() 方法根据注册中心类型(默认 Zookeeper)获取注册中心客户端,由注册中心客户端实例来进行真正的服务注册。
2.注册中心客户端将节点注册到注册中心,同时订阅对应的 override 数据,实时监听服务的属性变动实现动态配置功能。
3.最终返回的 Exporter 实现了 unexport() 方法,这样在服务下线时清理相关资源。

1.Dubbo 服务框架的基本设计原则是:
1.采用 URL 作为配置信息的统一格式,所有扩展点都通过传递 URL 携带配置信息;
2.采用 Microkernel + Plugin 模式,Microkernel 只负责组装 Plugin,Dubbo 自身的功能也是通过扩展点实现的,也就是 Dubbo 的所有功能点都可被用户自定义扩展所替换;
2.API 和 SPI
框架或组件通常有两类客户,一个是使用者,一个是扩展者。
1.API (Application Programming Interface) 是给使用者用的
2.SPI (Service Provide Interface) 是给扩展者用的
1.为了实现在模块装配的时候能不在程序里动态指明,这就需要一种服务发现机制。
2.JAVA SPI 就提供了这样的一个机制——为某个接口寻找服务实现的机制。
3。有点类似 IOC 的思想,将装配的控制权移到程序之外,在 模块化设计 中这个机制尤其重要。
3.JAVA SPI
1.JAVA SPI 实际上是 ”基于接口编程+策略模式+配置文件“ 组合实现的动态加载机制。
2.实现步骤:https://www.cnblogs.com/cyfonly/p/9474125.html
1.定义一个接口;
2.编写接口的一个或多个实现;
3.在 src/main/resources/ 下建立 /META-INF/services 目录, 新增一个以接口命名的文件,内容是实现类类名;
4.使用 ServiceLoader 来加载配置文件中指定的实现。
4.Dubbo Microkernel + Plugin
1.Dubbo “微内核+插件“机制的整体特性如下:
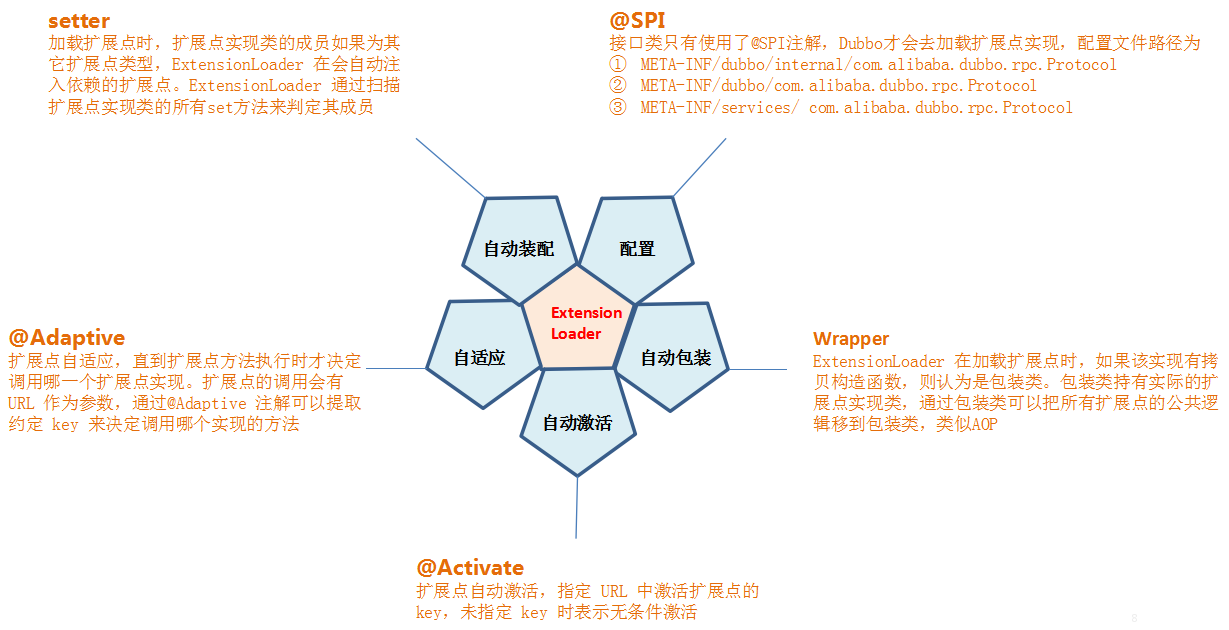
2.ExtensionLoader:
1.Dubbo 实现 “微内核+插件“机制的核心是 ExtensionLoader,它取代了 JDK 自带的 ServiceLoader。
2. 在 Dubbo 官方文档中提到,ExtensionLoader 改进了 JAVA ServiceLoader 的以下问题:
1.JDK 标准的 SPI 会一次性实例化扩展点所有实现,没用上也加载,如果有扩展实现初始化很耗时,会很浪费资源。
2.如果扩展点加载失败,连扩展点的名称都拿不到了。比如:JDK 标准的 ScriptEngine,通过 getName() 获取脚本类型的名称,但如果 RubyScriptEngine 因为所依赖的 jruby.jar 不存在,导致 RubyScriptEngine 类加载失败,这个失败原因被吃掉了,和 ruby 对应不起来,当用户执行 ruby 脚本时,会报不支持 ruby,而不是真正失败的原因。
3.增加了对扩展点 IoC 和 AOP 的支持,一个扩展点可以直接 setter 注入其它扩展点。
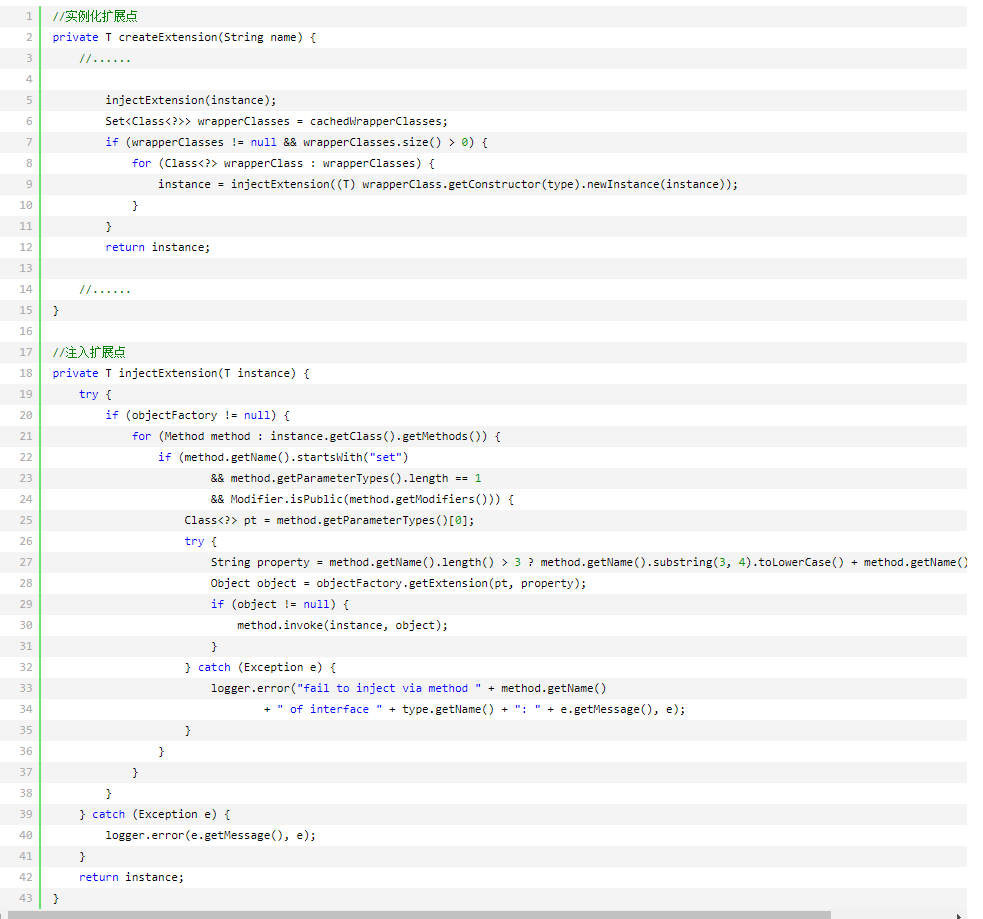
3.以 LoadBalance 为例,
1.文件 com.alibaba.dubbo.rpc.cluster.LoadBalance 中内容为:

2.用户使用时,在 XML 中配置 loadbalance="random",那么 Dubbo 将加载(且仅加载)RandomLoadBalance。
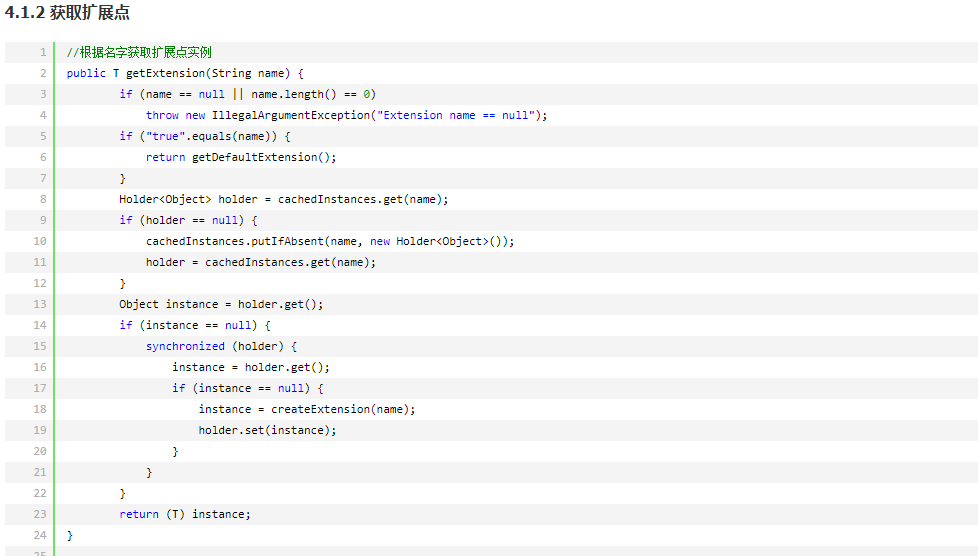
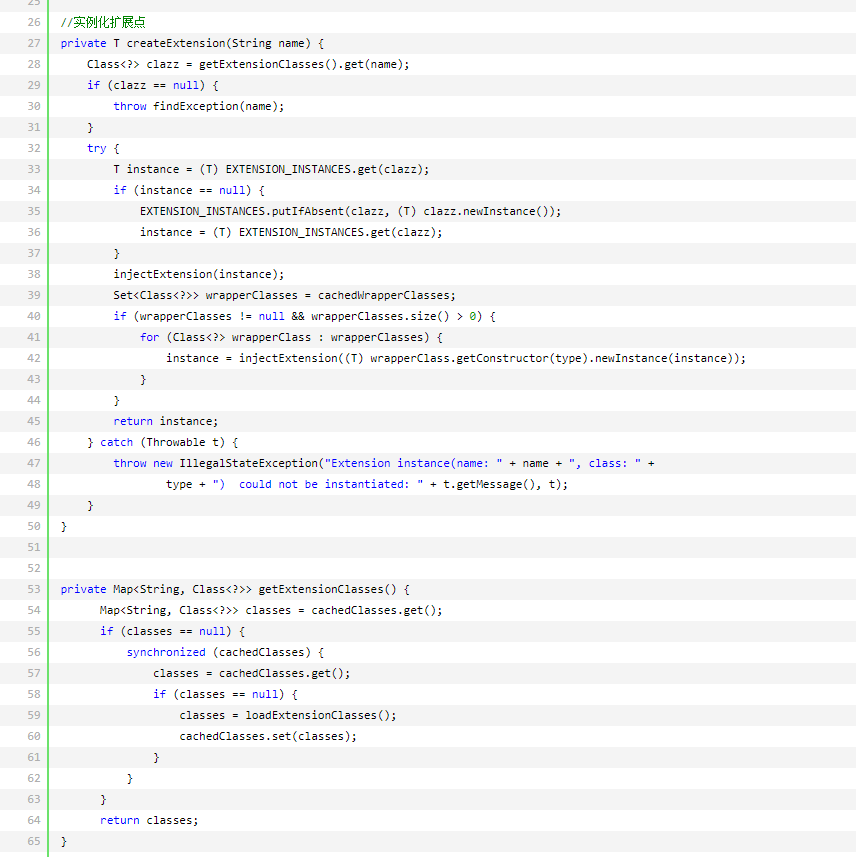
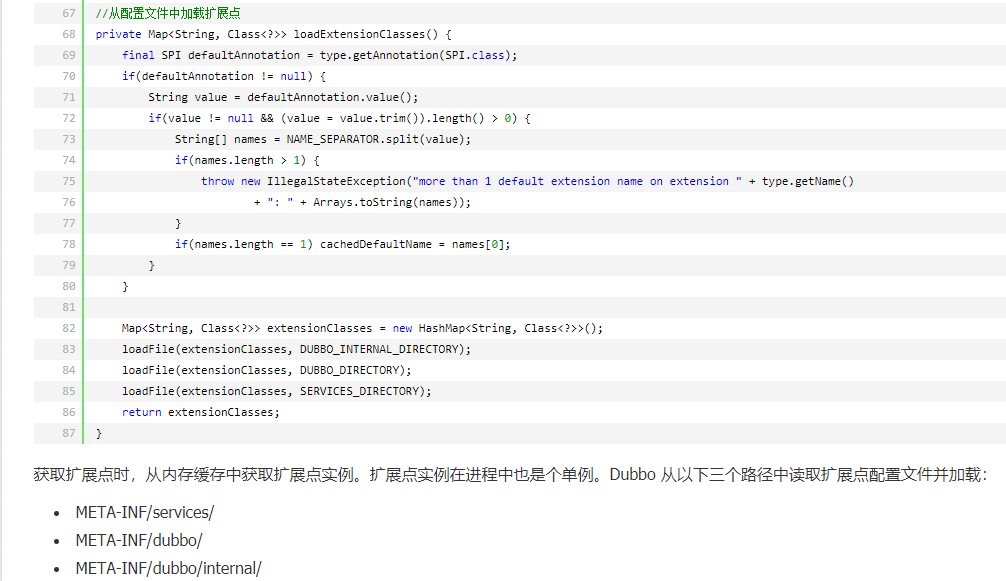
3.ExtensionLoader 加载扩展点流程


3.setter & Wrapper
1.setter:扩展点实现类的成员如果为其它扩展点类型,ExtensionLoader 在会自动注入依赖的扩展点。ExtensionLoader 通过扫描扩展点实现类的所有set方法来判定其成员。
2.Wrapper :如果扩展点实现类有拷贝构造函数,则认为是包装类。包装类持有实际的扩展点实现类,通过包装类可以把所有扩展点的公共逻辑移到包装类,类似AOP。
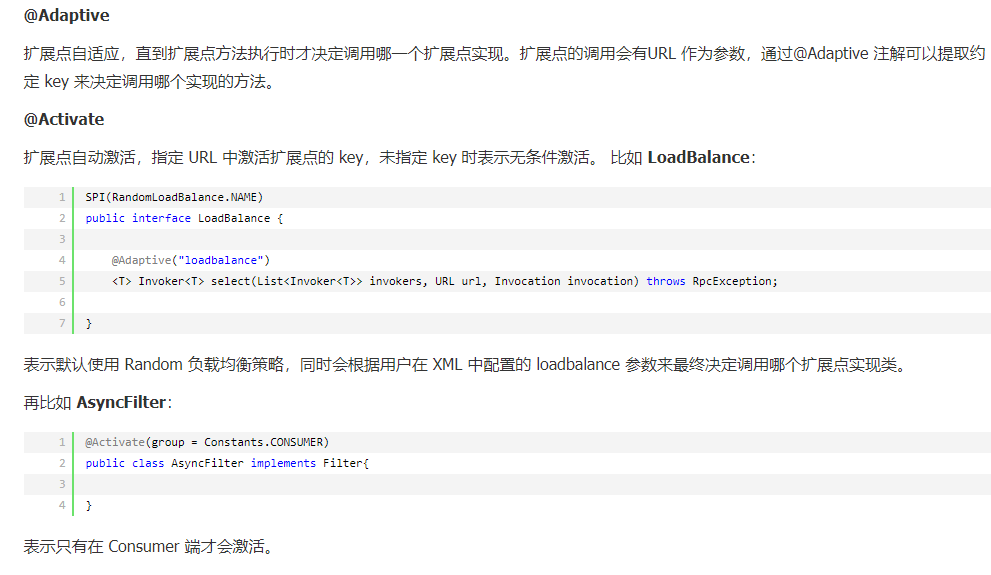
4.Adaptive & Activate
6.dubbo原理简单分析:
原文:https://blog.csdn.net/he90227/article/details/70157046
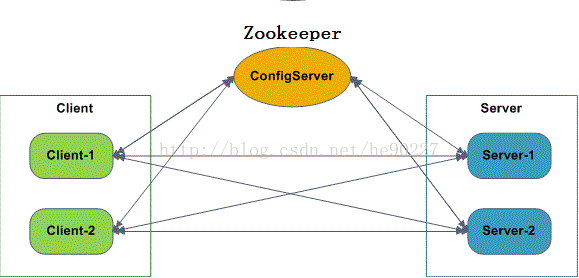
1.这个框架/工具/产品在实现的时候,都考虑到了容灾,扩展,负载均衡,于是出现一个配置中心(ConfigServer)的东西来解决这些问题。分布式框架。
基本原理如图:
2.ConfigServer
1.配置中心, 和每个Server/Client之间会作一个实时的心跳检测( 因为它们都是 建立的Socket长连接 ) ,比如几秒钟检测一次。 收集每个Server提供的服务的信息,每个Client的信息,整理出一个服务列表,如:

2.当某个 Server不可用,那么就 更新受影响的服务对应的 serverAddressList,即把这个Server从serverAddressList中踢出去 (从地址列表中删除) ,同时将 推送 serverAddressList 给这些受影响的服务的 clientAddressList里面的所有Client 。
如:192.168.0.3挂了,那么UserService和ProductService的serverAddressList都要把192.168.0.3删除掉,同时把新的列表告诉对应的Client 172.16.0.1,172.16.0.2, 172.16.0.3 ;
3.当 某 个Client挂了,那么 更新受影响的服务对应的clientAddressList
4.ConfigServer根据服务列表,就能提供一个web管理界面,来查看管理服务的提供者和使用者。
5.新加一个Server时,由于它会主动与ConfigServer取得联系,而ConfigServer又会将这个信息主动发送给Client,所以 新加一个Server时,只需要启动Server,然后几秒钟内,Client就会使用上它提供的服务
3.Client
1.调用服务的机器,每个Client启动时,主动与ConfigServer建立Socket长连接,并将自己的IP等相应信息发送给ConfigServer。
2.Client在使用服务的时候根据服务名称去ConfigServer中获取服务提供者信息(这样ConfigServer就知道某个服务是 当前 哪几个Client在使用),Client拿到这些服务提供者信息后,与它们都建立连接,后面就可以直接调用服务了,当有多个服务提供者的时候,Client根据一定的规则来进行负载均衡,如轮询,随机,按权重等。
3.一旦Client使用的服务它对应的服务提供者有变化(服务提供者有新增,删除的情况),ConfigServer就会把最新的服务提供者列表推送给Client,Client就会依据最新的服务提供者列表重新建立连接,新增的提供者建立连接,删除的提供者丢弃连接
4.Server:
真正提供服务的机器,每个Server启动 时 ,主动与ConfigServer建立Scoket长连接,并将自己的IP,提供的服务名称,端口等信息直接发送给ConfigServer,ConfigServer就会收集到每个Server提供的服务的信息。
5.优点:
1,只要在Client和Server启动的时候,ConfigServer是好的,服务就可调用了,如果后面 ConfigServer挂了,那只影响 ConfigServer挂了以后服务提供者有变化,而Client还无法感知这一变化。
2,Client每次调用服务是不经过ConfigServer的,Client只是与它建立联系,从它那里获取提供服务者列表而已
3,调用服务- 负载均衡: Client调用服务时,可以根据规则在多个服务提供者之间轮流调用服务。
4, 服务提供者- 容灾:某一个Server挂了,Client依然是可以正确的调用服务的,当前提是这个服务有至少2个服务提供者,Client能很快的感知到服务提供者的变化,并作出相应反应。
5,服务提供者-扩展:添加一个服务提供者很容易,而且Client会很快的感知到它的存在并使用它。
