
11 | “万金油”的String,为什么不好用了?
String 类型并不是适用于所有场合的,它有一个明显的短板,就是它保存数据时所消耗的内存空间较多。

用什么数据结构可以节省内存?
Redis 有一种底层数据结构,叫压缩列表(ziplist),这是一种非常节省内存的结构。
如何用集合类型保存单值的键值对?
以图片 ID 1101000060 和图片存储对象 ID 3302000080 为例,我们可以把图片 ID 的前 7 位(1101000)作为 Hash 类型的键,把图片 ID 的最后 3 位(060)和图片存储对象 ID 分别作为 Hash 类型值中的 key 和 value。
12 | 有一亿个keys要统计,应该用哪种集合?
要想选择合适的集合,我们就得了解常用的集合统计模式
所谓的聚合统计
就是指统计多个集合元素的聚合结果,包括:统计多个集合的共有元素(交集统计);把两个集合相比,统计其中一个集合独有的元素(差集统计);统计多个集合的所有元素(并集统计)。
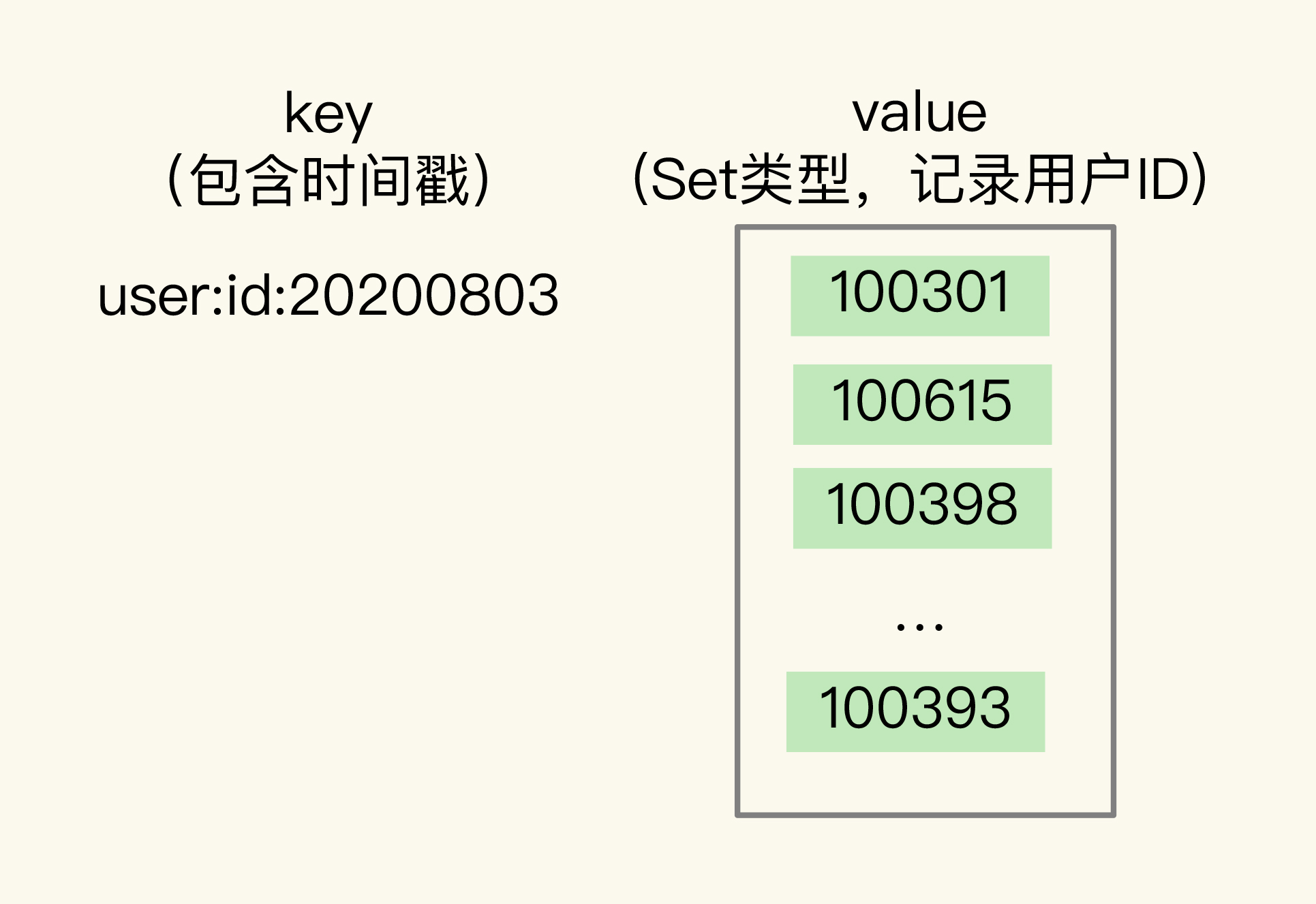
排序统计
List 是按照元素进入 List 的顺序进行排序的,而 Sorted Set 可以根据元素的权重来排序
二值状态统计
bitmap 三百六五天,设置每天的状态0 ,1. setbit userkey1 1 (第二天) 1(状体0,1)
16 | 异步机制:如何避免单线程模型的阻塞?
Redis 的各种关键操作,以及其中的阻塞式操作,我们来总结下刚刚找到的五个阻塞点:
集合全量查询和聚合操作;
bigkey 删除;
清空数据库;
AOF 日志同步写;
从库加载 RDB 文件。
17 | 为什么CPU结构也会影响Redis的性能?
每调度一次,一些请求就会受到运行时信息、指令和数据重新加载过程的影响,这就会导致某些请求的延迟明显高于其他请求
我们要避免 Redis 总是在不同 CPU 核上来回调度执行。于是,我们尝试着把 Redis 实例和 CPU 核绑定了,让一个 Redis 实例固定运行在一个 CPU 核上。我们可以使用 taskset 命令把一个程序绑定在一个核上运行。
25 | 缓存异常(上):如何解决缓存和数据库的数据不一致问题?
数据的一致性:这里的“一致性”包含了两种情况:
缓存中有数据,那么,缓存的数据值需要和数据库中的值相同;
缓存中本身没有数据,那么,数据库中的值必须是最新值。
1. 新增数据
属于第一种情况,不需要操作缓存。
2. 删改数据
属于第二种请情况:
先删除缓存,缓存数据缺失
先删除数据库,缓存删除失败,可以重试。
26 | 缓存异常(下):如何解决缓存雪崩、击穿、穿透难题?
缓存雪崩:redis节点异常,或者大量key同时失效,导致数据库压力暴增。
缓存击穿:热点数据,在缓存失效的那一刻,大量请求请求到数据库,造成数据库压力。
缓存穿透:数据库不存在的值,没有被缓存下来,请求直接到达数据库,造成数据库压力。
