
开篇词 | 这样学Redis,才能技高一筹
0.如何设计缓存?
高性能,存储,高可用,可扩展,持久化,空间利用最大化,过期策略。
解决问题:数据一致性问题,雪崩,穿透,击穿等问题。
1.高性能:C语言,nio多路复用,单线程
2.高可用:集群--主从,RedisPlus,哨兵模式。
3.可扩展:hash槽13864个,分片。
4.持久化:aof,rdb
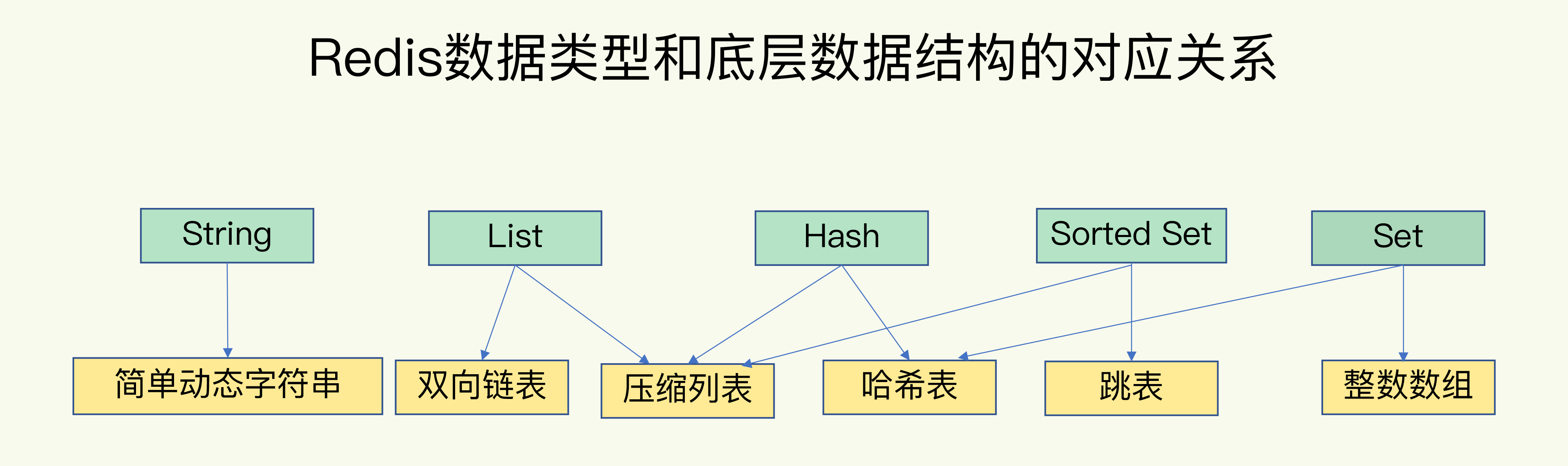
5.空间利用最大化:丰富的数据类型,不同的数据类型采用不同的数据结构存储。
6.过期策略:luf最近最少使用。删除key时,在空闲时删除,或者设置过期执行更新修改删除。
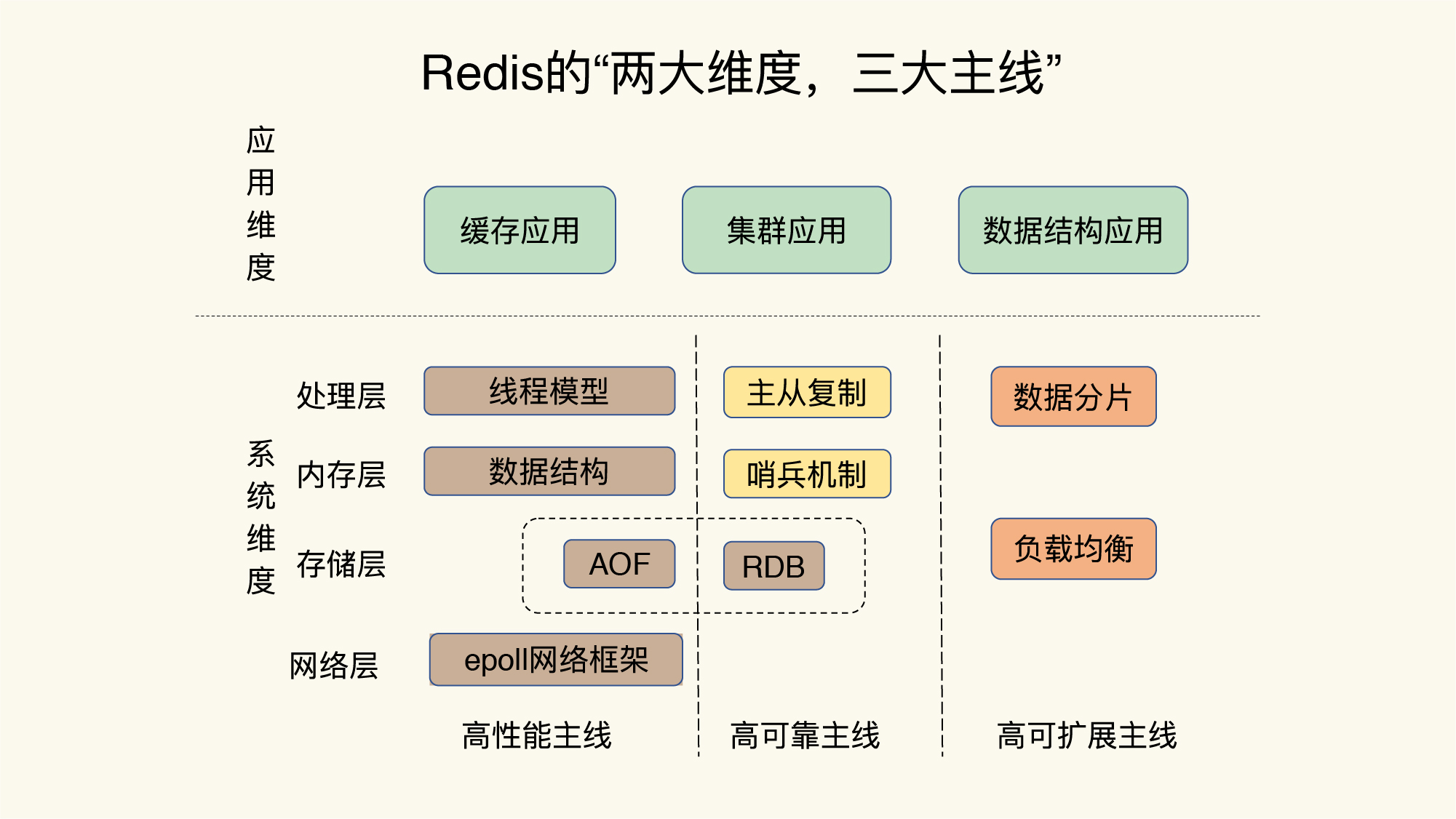
01 | 基本架构
1.基于内存得KV数据库,
2.单线程,
3.多路复用机制,
4.内存模型:https://mp.weixin.qq.com/s/GaCpNatAII4iBIUlwVdYOA
1.内存统计
命令:info memory
2.内存划分
1.数据库本身
2.进程运行占用
3.缓冲内存,包含AOF缓冲区
4.内存碎片
3.数据存储的细节:
dicEntry->redisObject=6个属性;
embStr :RedisObject(16)+sdshdr((int)8+(str)39+1=48)=64(一个存储单元);
raw:在不同存储单元。raw=n个(RedisObject+sdshdr),数据是不连续的。‘
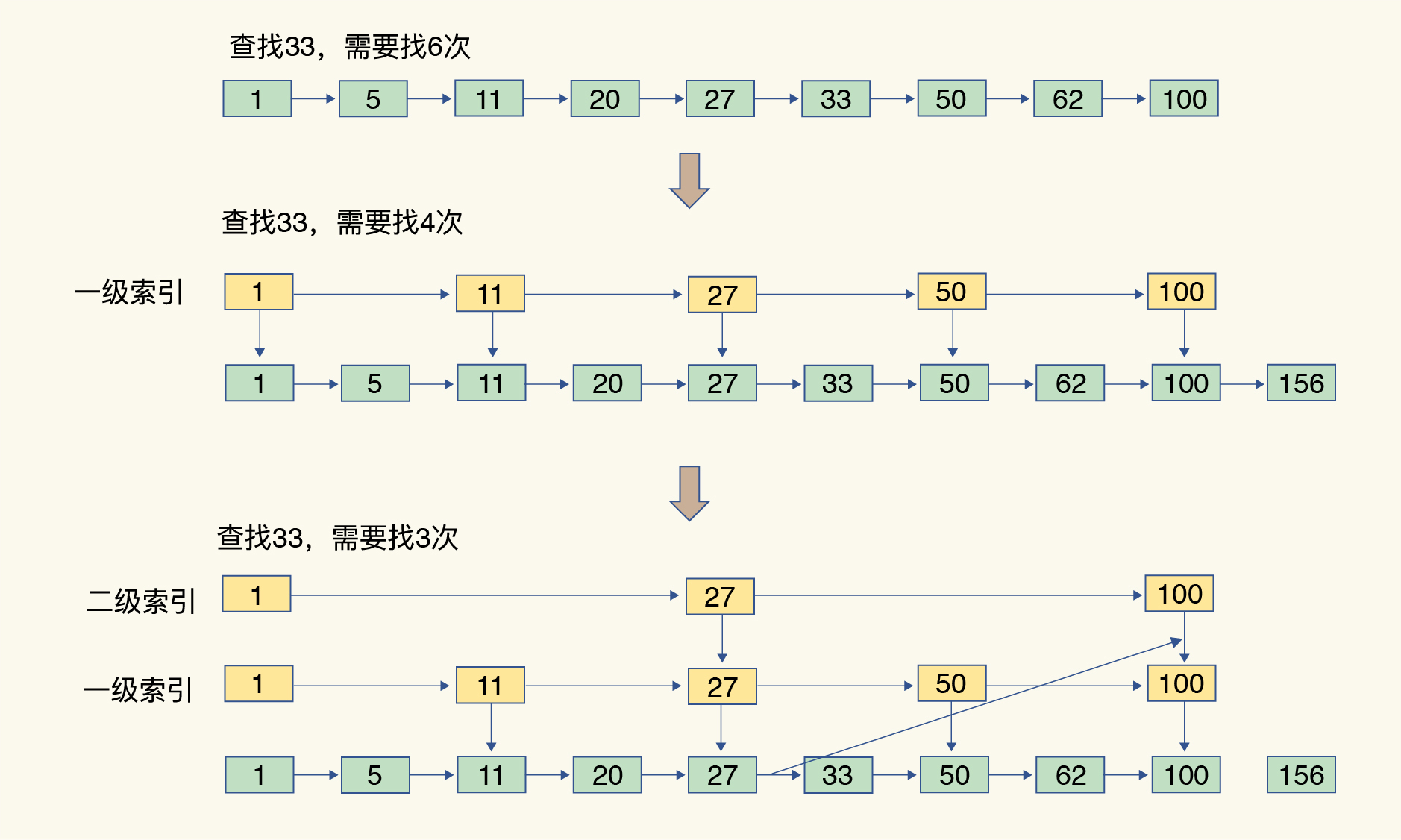
skiplist:顺序排序,多级索引,每层索引比较,查询时间复杂度为O(logn)。
1.跳表的索引高度: h = log2n
2.每次遍历三个元素:即O(3*log2n)约等于O(logn)
h的计算:
假设原始的链表有n个元素;
则一级索引有n/2 个元素、二级索引有 n/4 个元素、h级索引就有 n/2h次方个元素;
即:最高级索引 h 满足 2 = n/2h次方,即 h = log2n。
set hello world 时,所涉及到的数据模型:
1.dictEntry:每个键值对都会有一个 dictEntry,里面存储了指向 Key 和 Value 的指针;next 指向下一个 dictEntry,与本 Key-Value 无关
2.Key:Key(”hello”)并不是直接以字符串存储,而是存储在 SDS 结构中。
3.RedisObject:Value(“world”)既不是直接以字符串存储,也不是像 Key 一样直接存储在 SDS 中,而是存储在 RedisObject 中。
1.RedisObject 中的 type 字段指明了 Value 对象的类型,ptr 字段则指向对象所在的地址。
2.Redis 对象的类型、内部编码、内存回收、共享对象等功能,都需要 RedisObject 支持。
3.RedisObject对象结构:
1.type:
2.encoding:支持多种编码
3.lru:最后一次访问的时间
4.refcount:记录对象的引用次数。
5、ptr:指针指向的数据
4.一个 RedisObject 对象的大小为 16 字节:4bit+4bit+24bit+4Byte+8Byte=16Byte
4.jemalloc:内存分配器
1.jemalloc 在 64 位系统中,将内存空间划分为小、大、巨大三个范围;
每个范围内又划分了许多小的内存块单位;
当 Redis 存储数据时,会选择大小最合适的内存块进行存储。
4.Redis 的对象类型与内部编码
1.字符串:
1.int 8 个字节的长整型,字符串值是整型时,这个值使用 long 整型表示.
2.embStr:<=39 字节的字符串
3.raw: raw:大于 39 个字节的字符串
1.redisObject占16个字节,当buf内的字符串长度是39时,sdshdr的大小为8+39+1=48。加起来刚好64。jemalloc会分配8,16,32,64等字节的内存。
2.embstr和raw都使用redisObject结构和sdshdr结构来表示字符串对象,但是raw会分别两次创建redisObject结构与sdshdr结构,内存不一定是连续的,而embstr直接创建一块连续的内存
3.embstr开辟连续的内存可以带来的优势:
1.内存释放是embstr只需要释放一次,而raw需要释放两次
2.emstr查找的更快
2.List(列表)
1.压缩列表(ziplist)
2.双端链表(linkedlist)
3.hash:
1.压缩列表(ziplist)和哈希表(hashtable)
4.集合:
整数集合(intset)或哈希表(hashtable)
五、有序集合
压缩列表(ziplist)或跳跃表(skiplist)
02 | 数据结构:快速的Redis有哪些慢操作?
1. 键和值用什么结构组织?
2.为什么哈希表操作变慢了?
有哪些底层数据结构?
集合类型的底层数据结构主要有 5 种:整数数组、双向链表、哈希表、压缩列表和跳表。
其中,哈希表的操作特点我们刚刚已经学过了;整数数组和双向链表也很常见,它们的操作特征都是顺序读写,也就是通过数组下标或者链表的指针逐个元素访问,操作复杂度基本是 O(N),操作效率比较低;压缩列表和跳表我们平时接触得可能不多,但它们也是 Redis 重要的数据结构,所以我来重点解释一下。
不同操作的复杂度

在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了。
我们再来看下跳表。
有序链表只能逐一查找元素,导致操作起来非常缓慢,于是就出现了跳表。
跳表在链表的基础上,增加了多级索引处理,通过比较索引位置的大小,判断元素位置在该位置左侧还是右侧,几个跳转,实现数据的快速定位.
单元素操作,是指每一种集合类型对单个数据实现的增删改查操作。例如,Hash 类型的 HGET、HSET 和 HDEL,Set 类型的 SADD、SREM、SRANDMEMBER 等。这些操作的复杂度由集合采用的数据结构决定,例如,HGET、HSET 和 HDEL 是对哈希表做操作,所以它们的复杂度都是 O(1);Set 类型用哈希表作为底层数据结构时,它的 SADD、SREM、SRANDMEMBER 复杂度也是 O(1)。
范围操作,是指集合类型中的遍历操作,可以返回集合中的所有数据,比如 Hash 类型的 HGETALL 和 Set 类型的 SMEMBERS,或者返回一个范围内的部分数据,比如 List 类型的 LRANGE 和 ZSet 类型的 ZRANGE。这类操作的复杂度一般是 O(N),比较耗时,我们应该尽量避免
03 | 高性能IO模型:为什么单线程Redis能那么快?
Redis 为什么用单线程?
多线程的开销
单线程 Redis 为什么那么快?
基本 IO 模型与阻塞点
06 | 数据同步:主从库如何实现数据一致?
主从使用rdb同步,首次全量同步,后面使用增量同步,掉线重连也是增量同步
优秀原文链接:https://www.cnblogs.com/daofaziran/p/10978628.html
1.全量同步:
1.Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。
1. 从服务器连接主服务器,发送SYNC命令;
2.主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
3.主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
4.从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
5.主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
6.从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;

7.完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求。
2.增量同步:
1.Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
2.增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
07 | 哨兵机制:主库挂了,如何不间断服务?
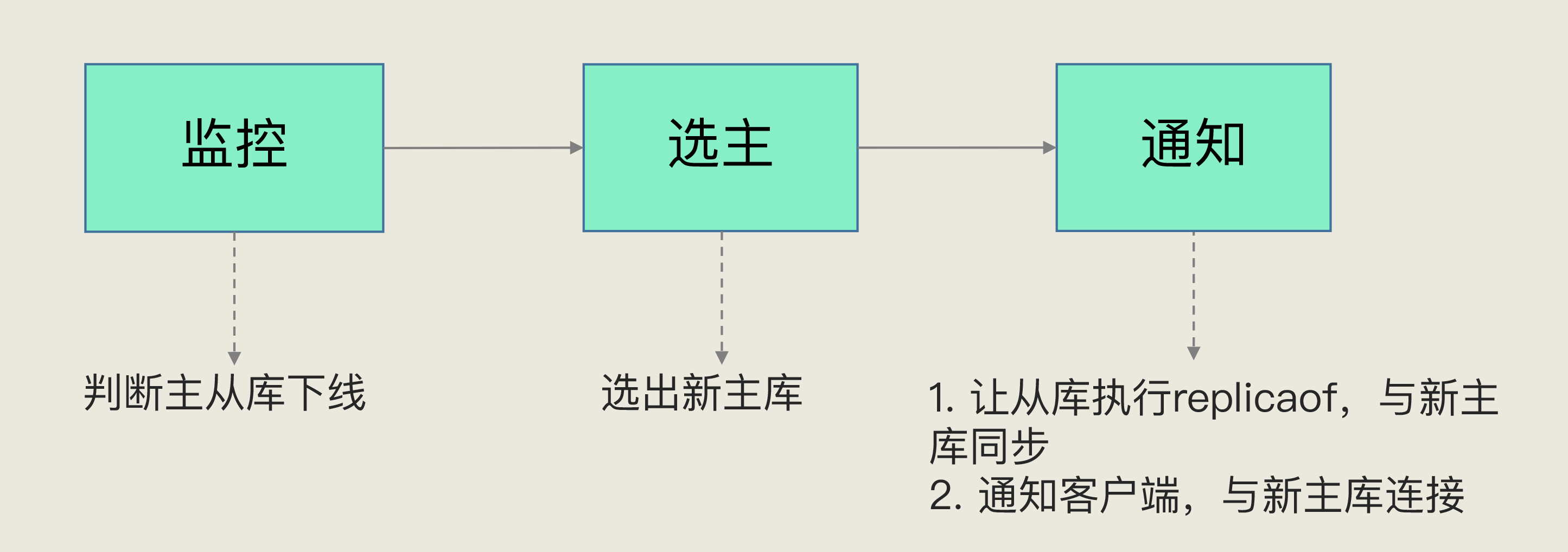
08 | 哨兵集群:哨兵挂了,主从库还能切换吗?
哨兵集群 节点互相同步。
09 | 切片集群:数据增多了,是该加内存还是加实例?
横向扩展:增加容量,cpu核数,磁盘容量,操作较为简单。但同同时也因为数据量大,导致单机压力过大,出现性能瓶颈。
纵向扩展:分片扩容,增加单机实例。分摊节点压力到多个实例上。
分槽:共有16384个hash槽,按照实例取模分配hash槽,自定义分配hash槽。将模映射到实例上。
数据迁移:
redis cluster的重定向机制:客户端向原实例发送没有数据时,会返回一个move:数据,重新请求move实例。
ask:正在迁移过程中,客户端发送指令时,会返回ask错误,客户端需要发送asking指令(新实例),get正在迁移的数据(旧实例)。
ask和move的区别:ask不会更新客户端hash槽分配缓存,move会更新。
