
OpenVLA - 将大语言模型 Llama 应用到机器人
VLA 全称 Vision Language Action(视觉语言动作模型), 广泛用于自动驾驶, 机器人控制等;
OpenVLA 是斯坦福开源的 VLA 模型, 由视觉语言模型 Prismatic 演化而来, 最新版本是 OpenVLA-OFT;
OpenVLA 对标 Google 的 RT2X;
下面是3个演示视频:
Google RT2X 例子:
输入: Move Coke Can near Taylor Swift(把可乐罐移到泰勒·斯威夫特旁边)

OpenVLA 物理环境例子:
输入: Flip Pot Upright(把锅翻正)

OpenVLA 虚拟环境例子(LIBERO虚拟环境)
输入: turn on the stove and put the moka pot on it(打开炉子,把摩卡壶放上去)

下面讲讲 OpenVLA-OFT 代码实现:
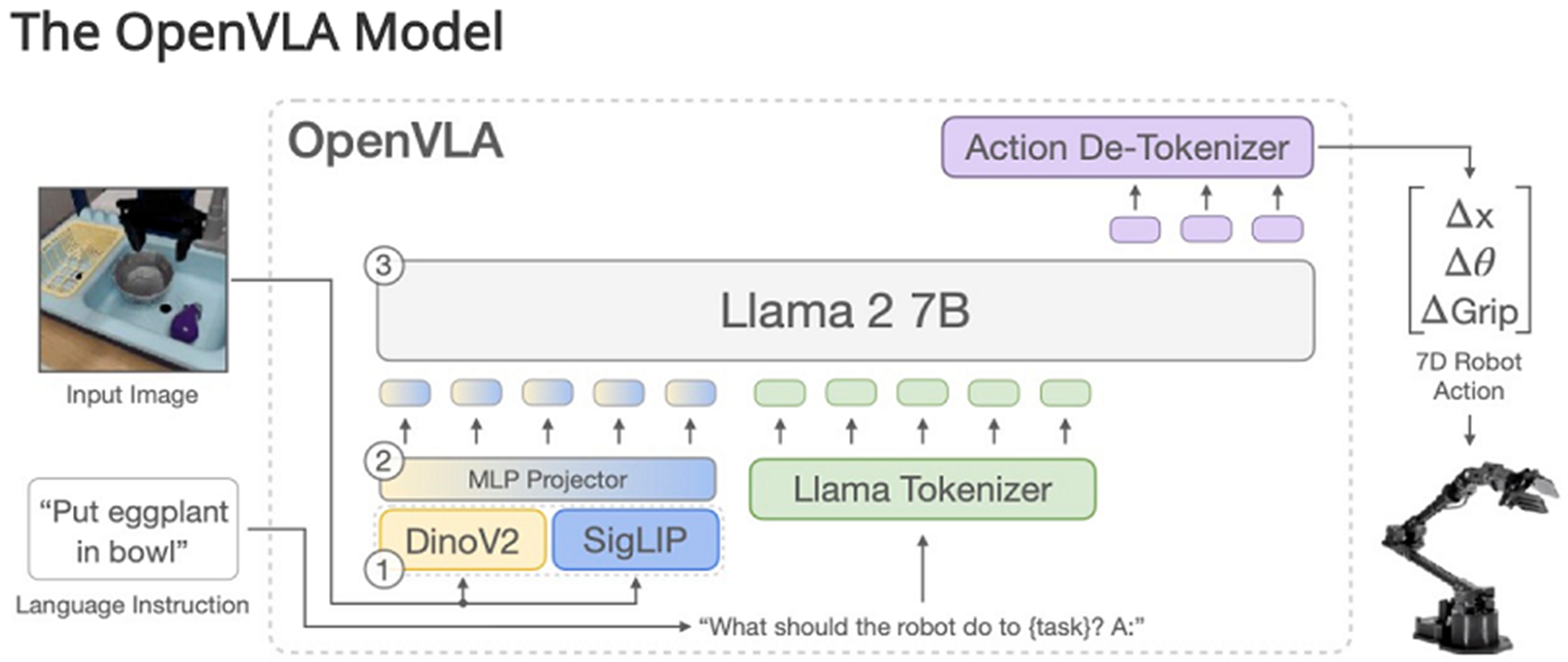
--- 图片来自于 OpenVLA-OFT 官网
OpenVLA 将 Llama 词典表不常用的 256个 token 映射到机械臂的动作空间 (-1, 1), 在 ActionTokenizer 实现;
为什么要用 Llama 词典表不常用的 256 个词来表示动作呢, 因为训练时输入的自然语言格式是这样的:

输入到 Llama 的句子是: What action should the robot take to pick up the black bowl next to the cookie box and place it on the plate?
需要 Llama 预测的结果是: ន들丁Ħ项ヨŸ助들재Ħ飛ヨŸ종ḷ교ĦŸഞŸ타编計Ħ達每Ÿპ编음Ħ̍败Ÿ仮看재非ව음Ÿ米만재右1음Ÿ连❯两判現進Ÿ
上面的乱码就是 Llama 预测的机械臂的动作, 例如在 LIBERO 虚拟环境, 一个机械臂, 7个关节, 8个未来动作, 则会预测出 7x8=56 个词;
大概的处理逻辑如下:
- LlamaTokenizerFast 将语言转成 Llama 的 token
- 文本 token 嵌入到 Llama 的4096维空间
- 视觉处理模块调用 PrismaticVisionBackbone(SigLIP和DINOv2) 将图像分成16 x 16 的 patch, 也映射到 Llama 的4096维空间
- 生成 sequence: [BOS 图像 提示词 动作 EOS]
- 对动作做 mask, 防止 Llama 因果推理关注序列中的动作
- 对整个 sequence 做注意力计算 --- Llama 因果推理有32个 transformer decoder layer
- 最后一层 decoder layer 的输出预测 action
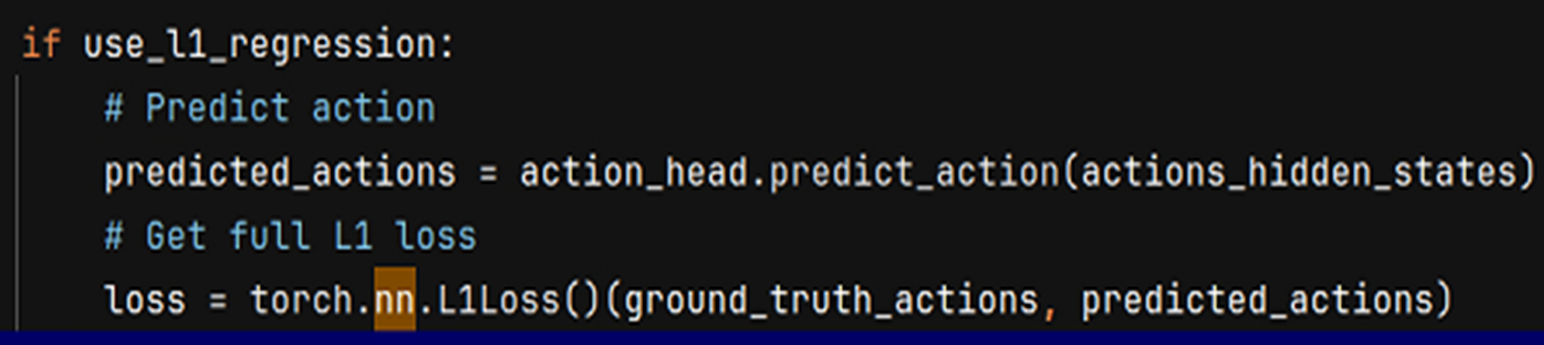
- 和真实的 action 计算 L1 损失值
对比一下自回归语言建模的文本预测:
序列: 中国的首都是哪儿?
预测下一个 token: 北
序列: 中国的首都是哪儿?北
预测下一个 token: 京
序列: 中国的首都是哪儿?北京
预测下一个token: EOS
每次都是用 1-n 个 token 来预测第 n+1 个 token;
所以当你用 deepseek 或者 copilot 的时候, 发现他是一个词一个词的挤出来
OpenVLA 中, 不是只预测一个 token, 而是预测固定数量的 token;
下面是 Llama 因果推理(LlamaForCausalLM)的前向传播函数, 看看自回归语言建模预测和 OpenVLA 动作预测的区别:
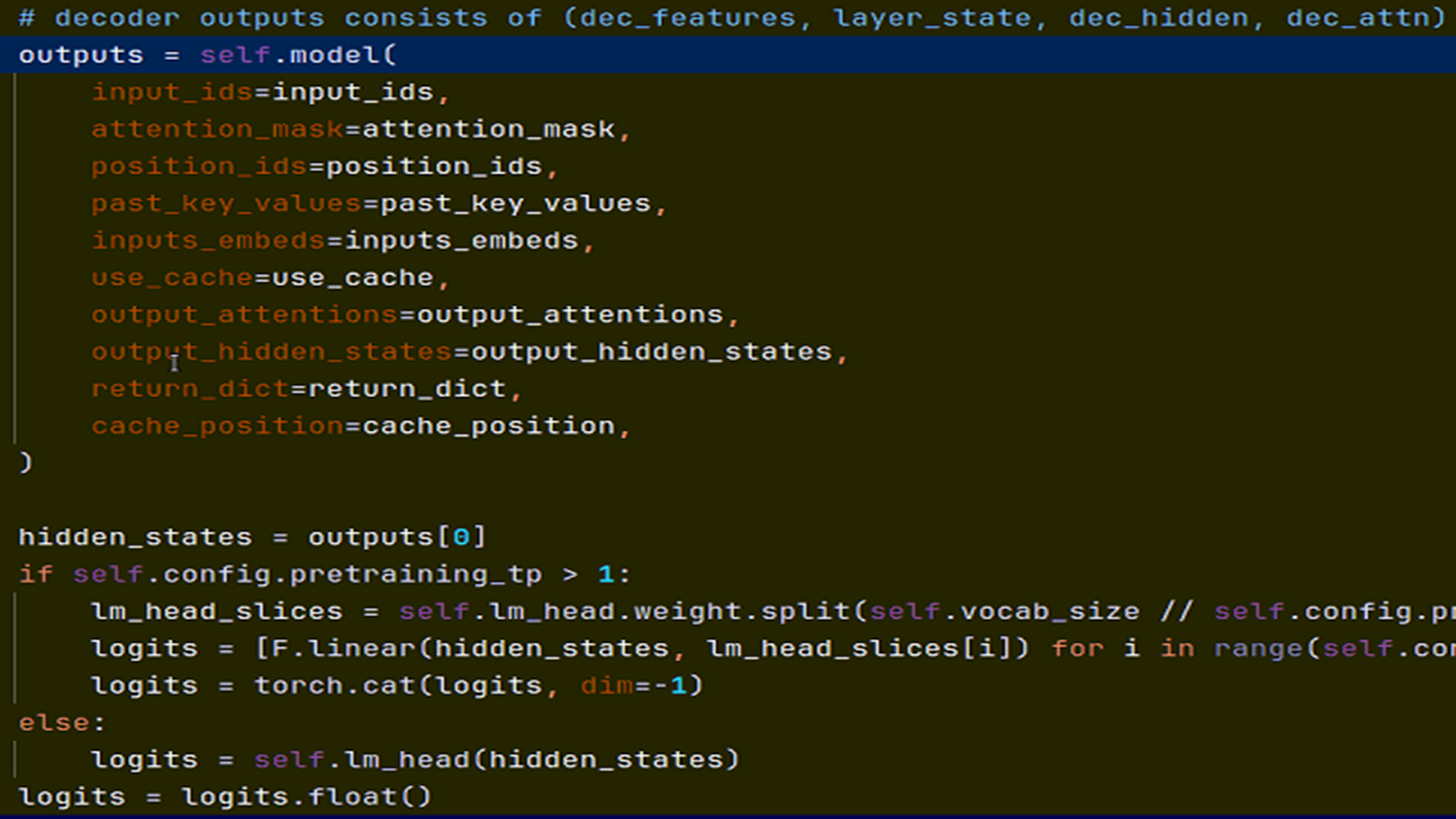
第一个参数 input_ids 是用于输入文本序列, 得到的 hiden_states, 用于预测下一个 token 出现的概率(即 Llama 词典表中每一个词出现的概率);
在 OpenVLA 中, 参数 input_ids 置空, 使用第5个参数: inputs_embeds;
inputs_embeds 序列包含: 嵌入到 Llama 的4096维空间的词, 嵌入到 Llama 的4096维空间的图像, 以及动作;
在计算损失值做梯度更新和反向传播时的区别:
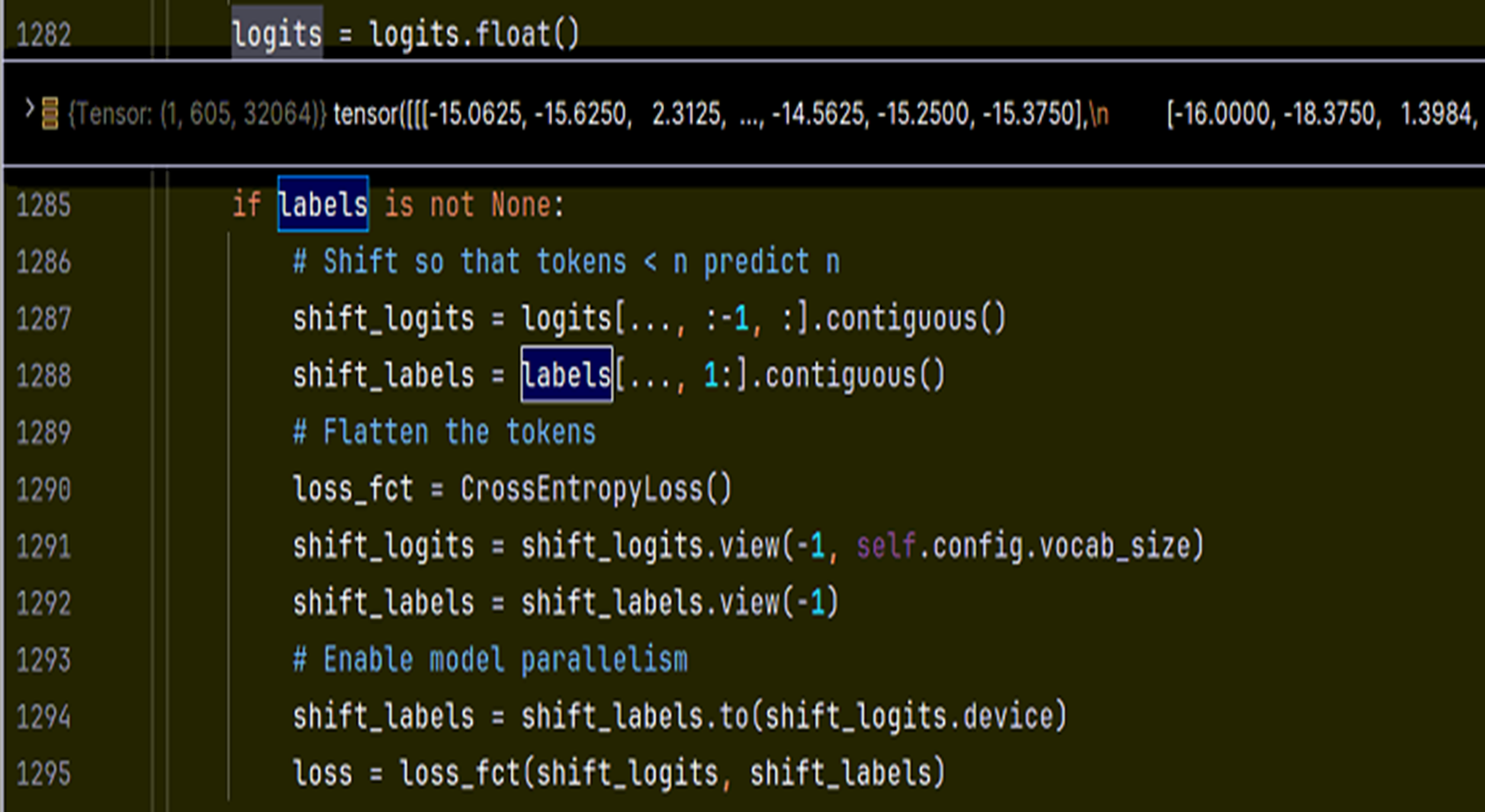
下面是传统自回归语言建模文本预测损失值计算, 用 sequence 预测的下一个 token 和下一个真实的 token 做比较计算损失值
而在 OpenVLA 中, 一次要预测多个 token, 且是定长;
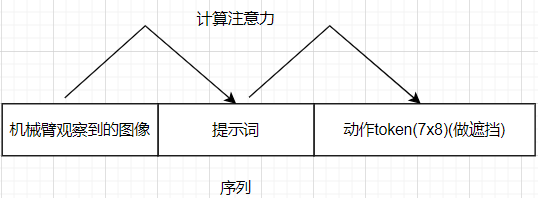
LIBERO 单机械臂场景为 7x8 个动作 token, ALOHA 物理环境为 7x2x25 个动作 token
在经过 Llama因果推理后, 序列中的动作和其他位置的信息产生了注意力, 把最后一层的 hiden_states 中的 action 序列取出来, 预测 action, 计算L1损失, 如下代码:

完


 浙公网安备 33010602011771号
浙公网安备 33010602011771号