
对照论文讲讲 Mobile ALOHA 代码
今天对照论文讲讲 Mobile ALOHA 的代码:
https://arxiv.org/pdf/2304.13705
训练
第一步是采样演示数据
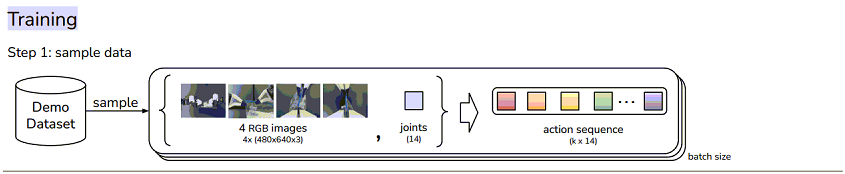
机械臂手腕摄像头(2个), 顶部摄像头(1个);
当前关节位置(joints): 14维向量, 2个机械臂每个关节的值;
动作序列 action sequence(k * 14) - 100个序列的 action;
第二步是推理隐变量z
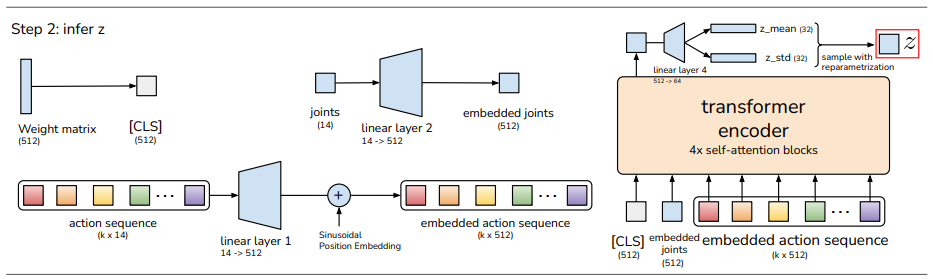
从左到右讲一下上图中各个步骤对应的代码:
- 获取 CLS, CLS 是输入到 transformer encoder 神经网络序列中的第一个 token, 用于关注整个序列的信息:
- cls_embed = self.cls_embed.weight # (1, hidden_dim)
- 将关节信息 (joints) 嵌入到 512维, 得到 embedded joints:
- qpos_embed = self.encoder_joint_proj(qpos) # (bs, hidden_dim)
- 将动作序列 (action sequence) 嵌入到 512维, 得到 embedded action sequence:
- action_embed = self.encoder_action_proj(actions) # (bs, seq, hidden_dim)
- 从正弦位置编码表 (Sinusoidal Position Embedding) 获得 ([CLS], qpos, a_seq) 的位置编码:
- pos_embed = self.pos_table.clone().detach()
- 正弦位置编码表由 get_sinusoid_encoding_table(1+1+num_queries, hidden_dim) 生成, 保存了 ([CLS], qpos, a_seq) 的位置信息, 并注册到模型中;
- self.register_buffer('pos_table', get_sinusoid_encoding_table(1+1+num_queries, hidden_dim)) # [CLS], qpos, a_seq
- 正弦位置编码是在512个维度上分别用正弦函数和余弦函数来对序列的位置进行编码
- num_queries 是100, 前面附上 CLS 和 关节信息, 总共是 102 长度的序列
- 将 CLS, joints, embedded action sequence 拼接;
- encoder_input = torch.cat([cls_embed, qpos_embed, action_embed], axis=1) # (bs, seq+1, hidden_dim)
- 将拼接后的 encoder_input 和 位置编码 pos_embed 输入到 transformer encoder
- encoder_output = self.encoder(encoder_input, pos=pos_embed, src_key_padding_mask=is_pad)
- mask 填 None, encoder 时不需要 mask
- src_key_padding_mask 表示序列中的哪些位置是填充的(无效的token)
-
- transformer encoder 是由 4 层 transformer encoder layer 构成, 加上位置编码并计算自注意力:
-
q = k = self.with_pos_embed(src, pos)
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
- 经过 transformer encoder 之后:
- encoder_input 序列里面每个向量都重新调整了 512 维空间上的位置, 和序列的其他元素有了注意力关系
- 取出第一个位置的值(即 CLS token): encoder_output = encoder_output[0] # take cls output only
- 将 CLS 线性变换, 512维转到64维: latent_info = self.latent_proj(encoder_output)
- 获取32维的均值向量(z_mean): mu = latent_info[:, :self.latent_dim]
- 获取32维的对数方差向量(z_std): logvar = latent_info[:, self.latent_dim:]
- 重参数化(sample with reparametrization)得到隐变量 z: latent_sample = reparametrize(mu, logvar)
- 把隐变量 z 再转换到 512维, 供 CVAE 解码器使用
- 总结一下:
- 用 transformer encoder 实现 CVAE 的编码器
- z 是为了描述机械臂关节信息(joints) 和 100 个 action 的某种抽象表示;
- Mobile ALOHA 中, 训练用的演示数据是由50个人生成, 每个人的 action 序列 不同, z 是为了描述这些 "不同风格的操作"
第三步是预测 action sequence (动作序列)

- 左边所示, 先用 ResNet18 处理 3 个摄像头的图像序列, 提取特征值
- 生成位置编码 - (Sinusoidal PosEmb)正弦位置编码
- features, pos = self.backbones[cam_id](image[:, cam_id])
- features 和 pos 分别是特征值和正弦位置编码
- 摄像头图像特征, 位置编码, 关节信息, 隐变量 z 输入到 transformer 中(完整的 transformer, 包含 encoder 和 decoder) :
- hs = self.transformer(src, None, self.query_embed.weight, pos, latent_input, proprio_input, self.additional_pos_embed.weight)[0]
- transformer encoder 由 4个 transformer encoder layer 构成 - (4x self-attention blocks), 生成自注意力
- transformer decoder 由 7个 transformer decoder layer 构成 - (7x cross-attention blocks), 通过交叉注意力查询
transformer encoder 的输出是 memory, 包含了自注意力信息, 可以供交叉注意力查询;
- memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
- 生成的 memory 输入到 transformer decoder, 供 query 向量查询, query 向量是 nn.Embedding(100, 512), 在512维空间查询 100 个动作序列
- 下面是 transformer decoder layer 代码, 先计算自注意力, 再和 encoder layer 的输出计算交叉注意力;
-
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask)[0]
-
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos), key=self.with_pos_embed(memory, pos), value=memory, attn_mask=memory_mask, key_padding_mask=memory_key_padding_mask)[0]
- 最后, transformer 的输出是 hiden state, 经过线性变化, 转换为动作序列 (100, 16)
总结一下, 用 transformer encoder 实现了 CVAE 的编码器, 输入为动作序列, 推理出动作序列的风格变量 z; 用 transformer encoder + transformer decoder 实现了推理, 输入为摄像头数据, 关节信息, 推测出动作序列;
测试和推理阶段
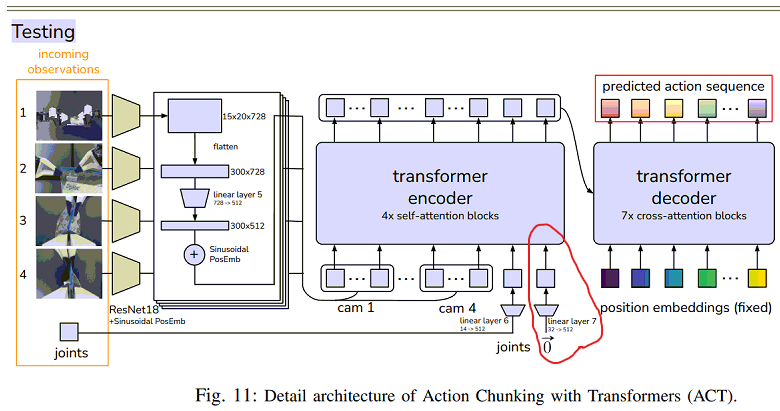
上图是测试和推理阶段的逻辑, 和训练阶段的预测类似, 去掉了 CVAE 编码器; 还有一个区别是上述红色的部分: 隐变量 z 取了0(先验均值)(mean of the prior);
稍微讲一下隐变量 z:
训练阶段使用的演示数据集是由 50 个不同的人操作生成的, 使用 CVAE编码器 是为了推测出不同人的动作序列的风格 z, 然后 z 输入到 transformer 神经网络, 使 transformer 神经网络掌握了多个风格的动作序列;
而在实际预测时, z 取 0, 表示动作风格选的是 "中规中矩" 的动作, 即论文中提到的 "确定性解码" (deterministically decode);
Hyperparameters
论文的最后, 作者列出了一些超参数:

- learning rate 是学习率
- bach size 是 批次
- encoder layers 和 decoder layers 是 transformer 神经网络的 encoder layer 层数和 decoder layer 层数, 需要改代码调整
- feedforward dimension 是 transformer encoder layer 中的前馈神经网络的维度
- self.linear1 = nn.Linear(d_model, dim_feedforward)
- self.linear2 = nn.Linear(dim_feedforward, d_model)
- hidden dimension 是 transformer 神经网络的维度
- heads 是注意力头数, 需要改代码调整
- chunk size 是动作序列的大小
- beta 是 CVAE 中的 kl_weight
- dropout 是 丢弃率
完.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号