
简单讲讲 mobile aloha 代码---训练阶段的encoder
简单讲讲 mobile aloha 代码---训练阶段的encoder

图片来源于 mobile aloha 论文;
训练和推理的核心的代码是这两个文件:
detr/models/detr_vae.py
detr/models/transformer.py
本文主要讲训练时推理隐变量z(latent z):
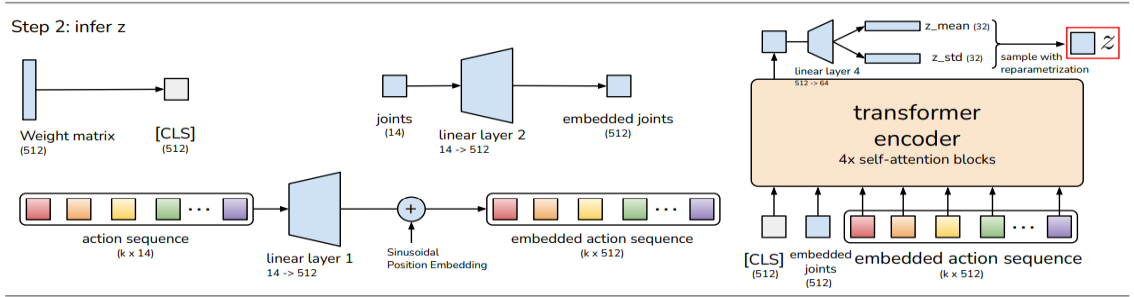
图片来源于mobile aloha 论文
代码是:
action_embed = self.encoder_action_proj(actions) # (bs, seq, hidden_dim)
actions是机械臂的操作, 形状是{Tensor: (8, 100, 16)}, 8是batch size, 100是sequence, 表示100帧对应的100个action, 16表示2个机械臂每个关节的动作;
每个action都会被嵌入到512维空间上, 转换为action_embed{Tensor: (8, 100, 512)};
qpos_embed = self.encoder_joint_proj(qpos) # (bs, hidden_dim)
qpos是机械臂在空间的绝对位置, 形状是{Tensor: (8, 14)}, 8是batch size, 14是14个关节的位置;
qpos会嵌入到512维空间, 转换为qpos_embed {Tensor: (8, 1, 512)}
cls_embed = self.cls_embed.weight # (1, hidden_dim)
cls_embed是512维空间的一个随机的点 {Tensor: (8, 1, 512)}
下面的语句会将cls_embed, qpos_embed, action_embed连接起来, cls_embed放在最开始的位置
encoder_input = torch.cat([cls_embed, qpos_embed, action_embed], axis=1)
连接之后的encoder_input是 {Tensor: (102, 8, 512)}, 之后encoder_input会通过Transformer神经网络, 计算注意力(Attention);
讲讲cls_embed这参数;
cls_embed
cls_embed的形状是{Tensor: (8, 1, 512)}, 8表示批次(batch size), 512表示维度, cls_embed是一个向量, 是512维空间上的一个点;
cls的灵感来源于自然语言处理(NLP)中的BERT模型, 在BERT中cls是一个句子的起始向量, 参与注意力计算, 与句子中每个词产生注意力关系;
举个例子:
在BERT模型中, 分别在句子的开头加cls, 结尾加seq:
[CLS] The cat sat on the mat [SEP]
这个句子的每个词(token), 包括cls和seq, 在768维空间随机分布; 然后进行注意力计算, 重新在高维空间分布, 产生注意力;

mobile aloha参考了BERT, 训练时取前100个帧和动作组成一个sequence, 在最前面加上cls, 让cls一起参与100帧的注意力运算, 产生注意力;

回到代码,
用Transformer神经网络计算注意力
encoder_output = self.encoder(encoder_input, pos=pos_embed, src_key_padding_mask=is_pad)
获取更新注意力之后的cls
encoder_output = encoder_output[0] # take cls output only
cls是512维空间上的一个点, 或者叫CAVE神经网络中的隐变量z(latent z);
再借用一下开头的图, z是右上角那个红色的东西
今天就写到这里, 未完待续


 浙公网安备 33010602011771号
浙公网安备 33010602011771号