
OO第一单元总结(表达式求导)
2019-03-26 23:14 Gentle_Conspiracy 阅读(260) 评论(0) 收藏 举报写在前边:第一次接触面向对象语言,编程思想仍然不可避免的有以前面向过程的影子。从第一次作业的完全面向过程,到第二次学会剥离各个类互不影响到第三次作业的先构思面向对象的基本程序架构再编程。虽然程序有些地方仍然显得很笨重,但是在面向对象编程这条道路上也算是迈出了实质性的一步。在这一过程中,真心感谢各位在讨论课上分享自己经验的同学和讨论区的大佬。从各位的分享中,自己get到很多的关于程序架构设计参考,关于面向对象的不同理解,自动评测的方法,以及很多小技巧。
历次作业程序分析
第一次作业(仅包含幂函数的求导):
初次接触面向对象编程,对于类的理解还是懵懵懂懂,第一次作业也不知不觉还是用面向过程的方式完成。第一次作业思路很简单也比较容易实现,但是存在着Main没有剥离出来输入模块,仍然有很多的输入处理方法。因此程序总体结构比较混乱,很大程度上也是因为面向过程的思维加上编程之前没有很好的思考程序的结构边匆忙开始编程。
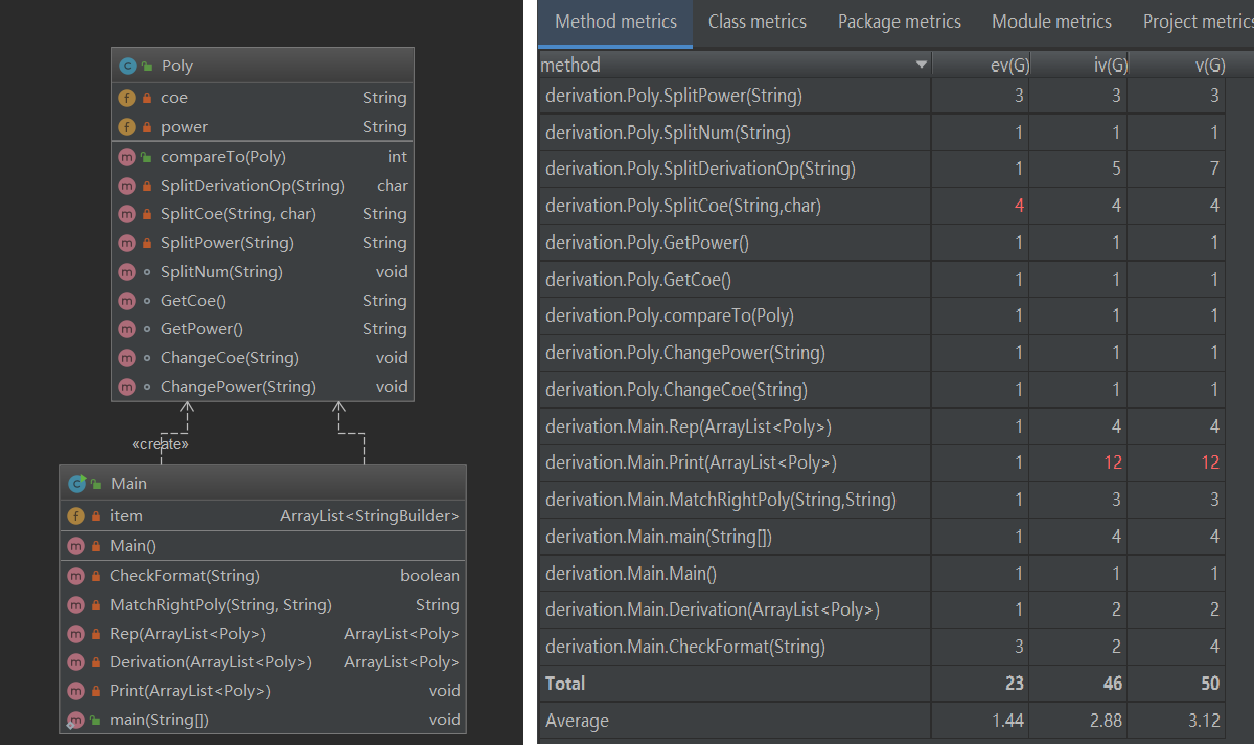
度量分析:
性能报告如上图,print方法的圈复杂度和模块设计复杂度高,表示这一方法的维护比较困难。在实际编程过程中也确实如此。由于把一个项分为系数(符号直接包含在系数中)和幂函数,其中为了使输出尽量优化(开头正项不输出正号、中间项正系数需要输出正号连接两项、幂指数为1不输出指数等等)使用大量的判断结构,有情况考虑不周就容易导致产生bug并且维护的时候很多重复判断的情况。而Poly中的SplitCoe方法由于嵌套的判断使得程序的结构化很弱,也进一步反映出整体作业结构设计的局部不合理。
代码量如图:第一次代码量不大,但是Main类的不精简表示结构设计的不合理。

Bug分析:
第一次作业中bug出现在空白符号没有处理完全,在判断完格式后去除空白符时没有去掉制表符,导致计算项的符号会出错。
互测找Bug:
第一次作业对于自动化测试还是不熟悉,所以通过建立语法树构建一些典型样例进行“盲狙”。另外通过查看他人程序进行白盒测试。找到最多的还是判断格式的错误,比如由于未检查非法字符使用trim方法去掉首尾不可见字符导致的格式判断错误。
第二次作业(包含幂函数三角函数的求导):
第二次作业首先把第一次作业的各个类提取出来各司其职,简单的把第一次作业的结构进行梳理,把第一次作业中Main的方法归到poly类。而一次作业的poly类其实作用是处理每个项,因此把poly类改为term类。由于当时对继承和接口并不熟练和了解,并且各类因子的共性比较大,对于因子建立类的时候只是统一的建立了一个Divisor类,用id的方式区分当前用到的因子类型。每一个项合并同类型之后都是可以归为一个幂函数正余弦函数三元组。对第二次作业我进行了部分的优化,即合并基本的三角函数平方和为1的情况(Simplify1)和1和一个相仿符号的三角函数平方的合并(Simplify2)。
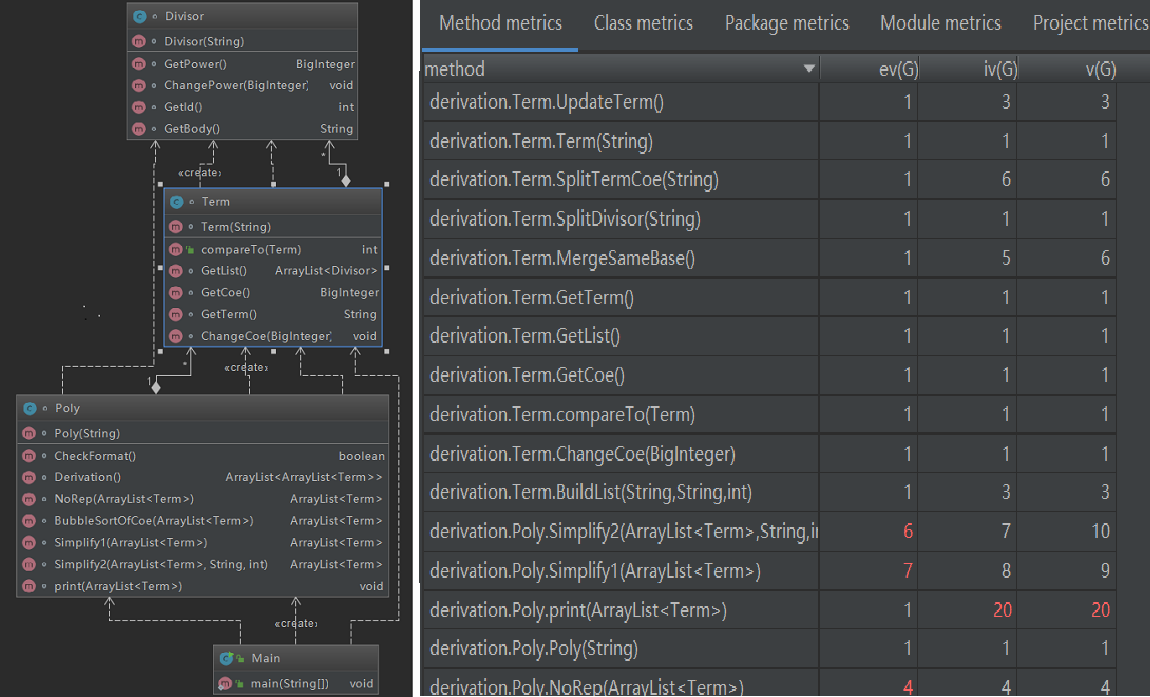
度量分析:
由于print方法是承接的第一次作业并没有进行大规模的修改,其模块的设计很依赖于Term和Poly的设计方法,不同的设计方法会导致Print很大不同,且大量的判断维护修改难。在优化函数(Simplify1,Simplify2)中由于判断和循环结构的嵌套,导致程序结构的复杂,结构化弱。
从第二次代码量的分布可以看出第二次的结构相比第一次有了明显的提升,从表达式到因子的层层深入代码量逐渐减少。但是本次作业的代码可扩展性仍然比较弱,结构还有很大的优化空间。

Bug分析:
自己的程序bug是在输出的时候盲目把"^1"替换为空串导致的当系数为1开头的多位数字的输出错误。在第二次作业的互测阶段找到的判断格式问题的明显减少。但是由于第二次作业的复杂性较第一次作业有所提升,在输出的问题上也有所增多,出现表达式中不合规范的输出。
互测找Bug:
在借鉴了讨论区同学分享的自动化方法,在此基础上进行改进(由于第二次加入了三角函数,对bc运算式进行了一定的修改),使用shell命令sed插入打包语句进行一个文件内java文件的打包工作,之后利用Xeger自动生成符合要求的字符串集合导入到test.txt中,在使用shell命令文件newtest.sh配合test.sh进行自动化测试:
#! bin/bash##newtest.sh chmod +x newtest.sh while read line do echo \n echo $line bash test.sh Alterego Alterego.Main $line bash test.sh ...... ...... done <test.txt
#! /bin/bash##test.sh
chmod +x test.sh
test="";
test=$3
Ans2=$(echo $test|java $2)
oAns2=$(echo "scale=2;$Ans2"|sed "s/cos/c/g"|sed "s/sin/s/g"|sed "s/x/3/g"|bc -l)
echo "$1: $Ans2"
echo $oAns2
该方法有一个不足,对于生成结果表达式中如果存在连续的加减号无法计算。需要另外特殊处理之后在计算。
第三次作业(支持嵌套因子的求导):
由于前面的作业都没有很大的可扩展空间,第三次作业进行了重构。最开始看到作业的题目,最直观的感受是表达式的嵌套构建的是一个树形的结构。
面临的第一个最大问题就是如何分离出来各个项。前两次作业都是直接使用正则表达式进行匹配,在检查格式的过程中把符合规范的项提取出来,出现不规范的项再报错。第三次作业显然无法使用正则匹配提取项。
注意到项之间使用加减号连接以及因子之间是使用乘法符号连接的特性,想到使用加减号切割项、使用乘号切割项内的因子。为了不会误切括号括起来的表达式因子,以及为了检查括号匹配问题,把两者结合到了一起,通过栈的方式找到正确的切割位置(该位置替换为空格,用空格切割)并且同时检查括号的匹配。对于因子建立一个Divisor父类,和三角函数因子(TriangleFunction)、常数因子(Constance)、表达式因子(PolyDivisor)、幂函数因子(PowerFunction)四个子类。并且在三角函数因子和表达式因子中包含一个PolyTree类,表示因子的嵌套。在以上建立表达式树过程中检查格式。求导的时候对于常数因子不进行求导。

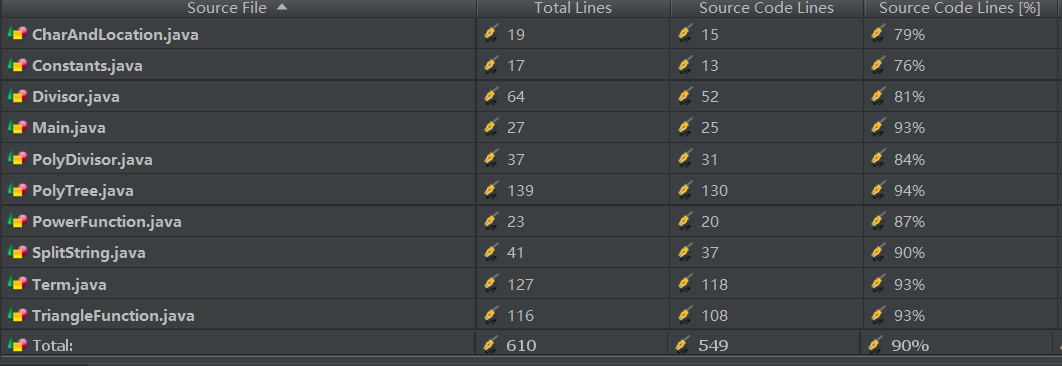
度量分析:
由于在建立树的过使用了很多的递归,程序的模块化弱化,模块之间的依赖关系更加复杂和紧密。最明显的是构建表达式树的方法(BuildPolyTree)、提取各个因子中的因子的各个部分的方法(MergeDivisor)和三角函数的求导方法(TriangleFunction.Derivation)。在项中提取因子的过程中,使用判断和递归,程序的结构化很弱。
从代码量来看,第二次到第三次代码量并没有增加很多。但是由于递归的调用,已经求导过程中的嵌套因子的存在,会递归的过程中产生了很多的多余括号。也显示者结构上的设计还有很多冗杂的地方。
Bug分析:
第三次作业虽然在强测没有bug,但是由于在预处理中的不完善,对于连续三个加减号的替换思考不周到,导致在符号处理上出错(和第一次一样栽在了符号上),在互测中被发现。
互测找Bug:
继续沿用了第二次的自动化测试脚本。但是由于嵌套因子的存在,导致生成随机测试数据更加困难。在第一次使用递归Xeger生成嵌套因子的测试数据的时候java程序爆栈。之后在听到课上赵梁煊同学的生成数据的方法后感觉很方便使用。即先把嵌套因子用标记符代替,在第一次生成表达式后,再用随机生成的表达式代替,直至表达式中不存在嵌套因子的标记符(到达字符数上限后停止替换,处理剩余的标记符)。
在找到别人的bug中最常见的是嵌套足够层数的括号之后,程序的工作异常。
对作业的重构
对于第一次作业的重构:第一次作业中没有使用因子层面的类,而是直接把幂函数当做项来处理,导致第二次作业修改和添加内容的工作量并不小。因此要划分出处因子层面的类,使得表达式的分析更加具体详细。并且要把程序的输入接口的Main类划分出来,使类的划分更加明确。
对于第二次作业的重构:第二次作业由于并没有使用继承和接口,使得因子的扩展性比较差。对与程序加上继承关系,从而可以省去使用id来判断因子类型的麻烦。
前两次作业中同样结构化和模块化弱的方法是print,因为采用大量判断结构输出结果。print方法的重构,前提是把Term存放方式重新构造,把项的符号和项的系数(常数项)分离开来,输出方法会有很大简化。
对于第三次作业的重构:第三次作业结构较前两次作业有所优化。但是其中由于没有采用接口方式进行求导,导致求导这一方法重写等等显得极为混乱。重构方法就是求导采用接口实现。对于输入处理可以采用构造多级的Parser,会省去利用栈来分割表达式中很多冗余的无用操作。
关于第一单元作业的感悟
第一单元过后,对于面向对象这一概念有了一个基本的认识。从面向过程向面向对象的转变也许是困难的,因为这改变的是一种编程思维方式。但是这一转变又是简单的,因为熟能生巧,大量的工程性练习会很快的打磨我们思维方式,在“计算机科学与工程”中的工程道路上越走越远也越走越顺畅。而科学能力也是需要高标准的工程能力做支撑。
在第一单元的作业中,可以看到自己会在一个很小地方犯错误,其中不乏带来了沉痛的代价,虽然这只是一个bug。而在完成作业的过程中,越来越凸显先做好设计的重要性。由于第一作业的架构的混乱,第二次作业沿用第一次作业的架构的时候,需要花很大的力气去扩展甚至重构。而第三次作业则是彻底的重构,其中的带来的时间代价是巨大的。这体现在直观感受上就是程序结构笨重,各个类划分不清晰,依赖度高,引发的就是debug难度不断提高。
总之,还需要进一步的理解现象对象的实质和一些编程思想。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号