YOLO 入门学习笔记
学习参考:https://www.youtube.com/watch?v=svn9-xV7wjk
YOLO -> You Only Look Once,只会对输入图片查看一次
What 做什么
YOLO 是一个目标检测算法,可以识别一张图片,中多目标多种类对象,并且很好的平衡了速度与准确率

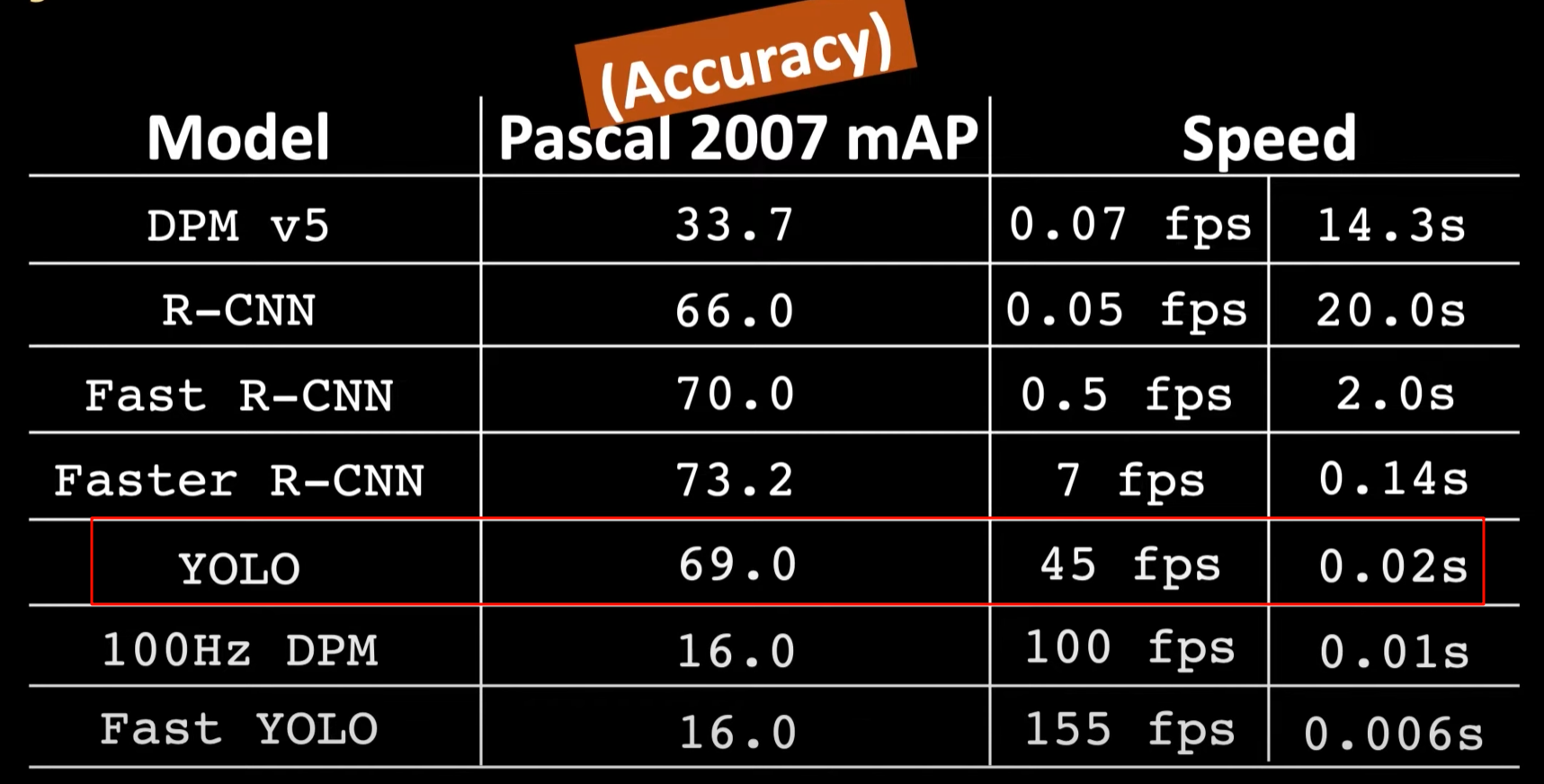
可以看到,YOLO 相比于最好算法准确性下降些许,但在速度上有极大提升
How? YOLO 如何进行
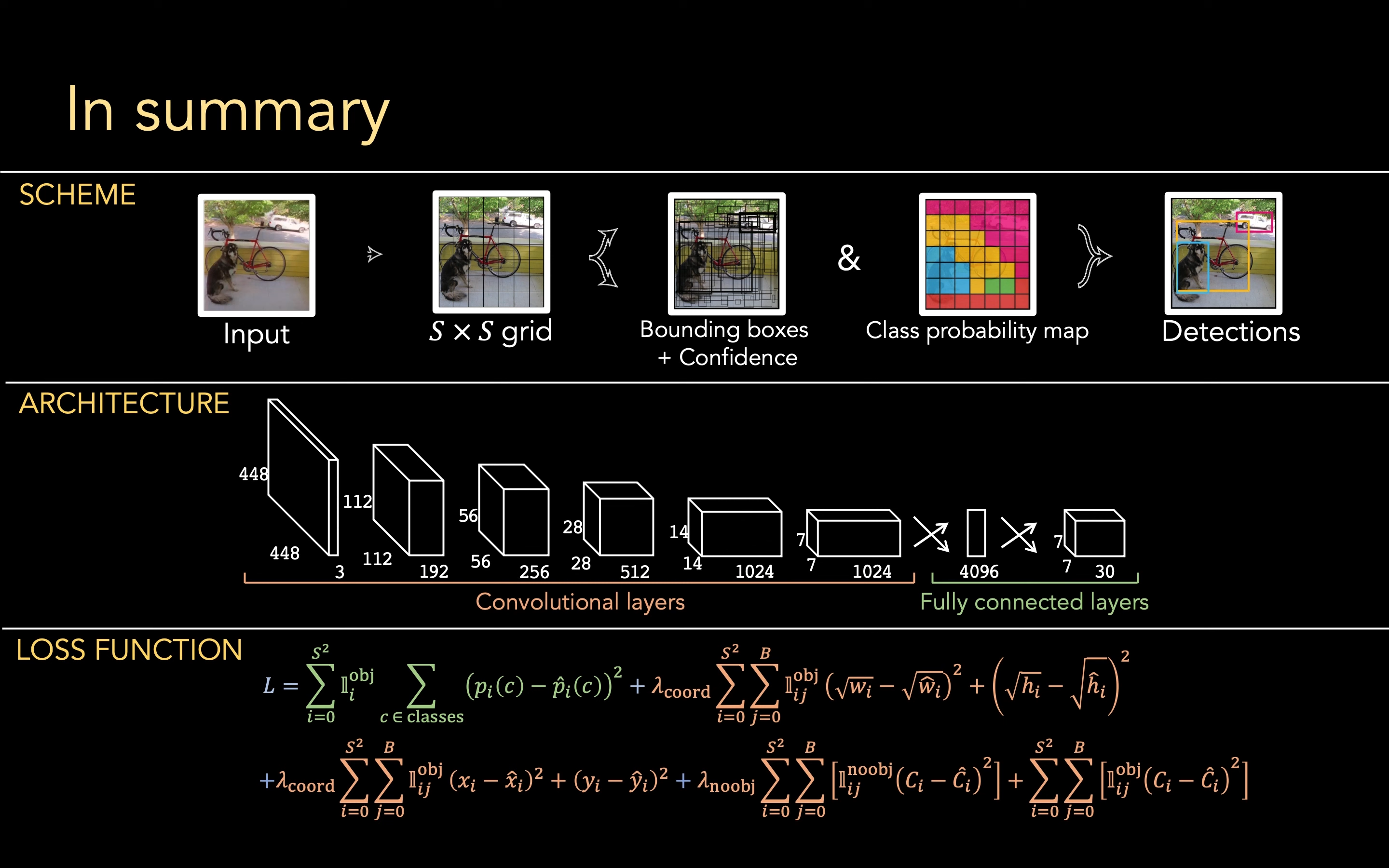
整体的思路而言,YOLO 就是将输入图片分为 \(S×S\) 个 grid:
- 对每个 grid 生成若干个 Bounding boxes,每个 box 有一个置信度(代表这个 box 有一个物体)
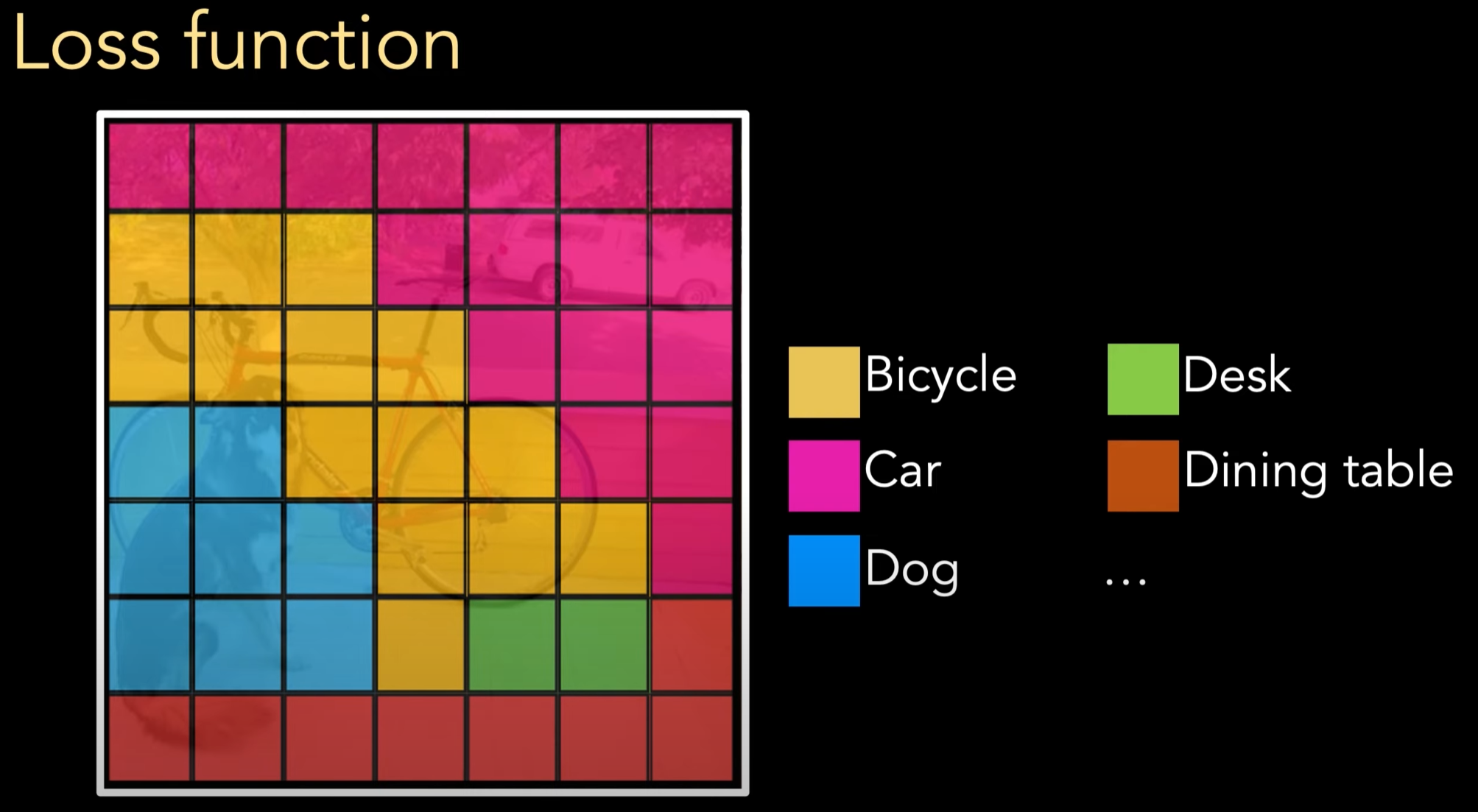
- 对每个 grid 赋予一个 class probability,属于哪个物体种类
将二者结合起来就是物体检测功能了
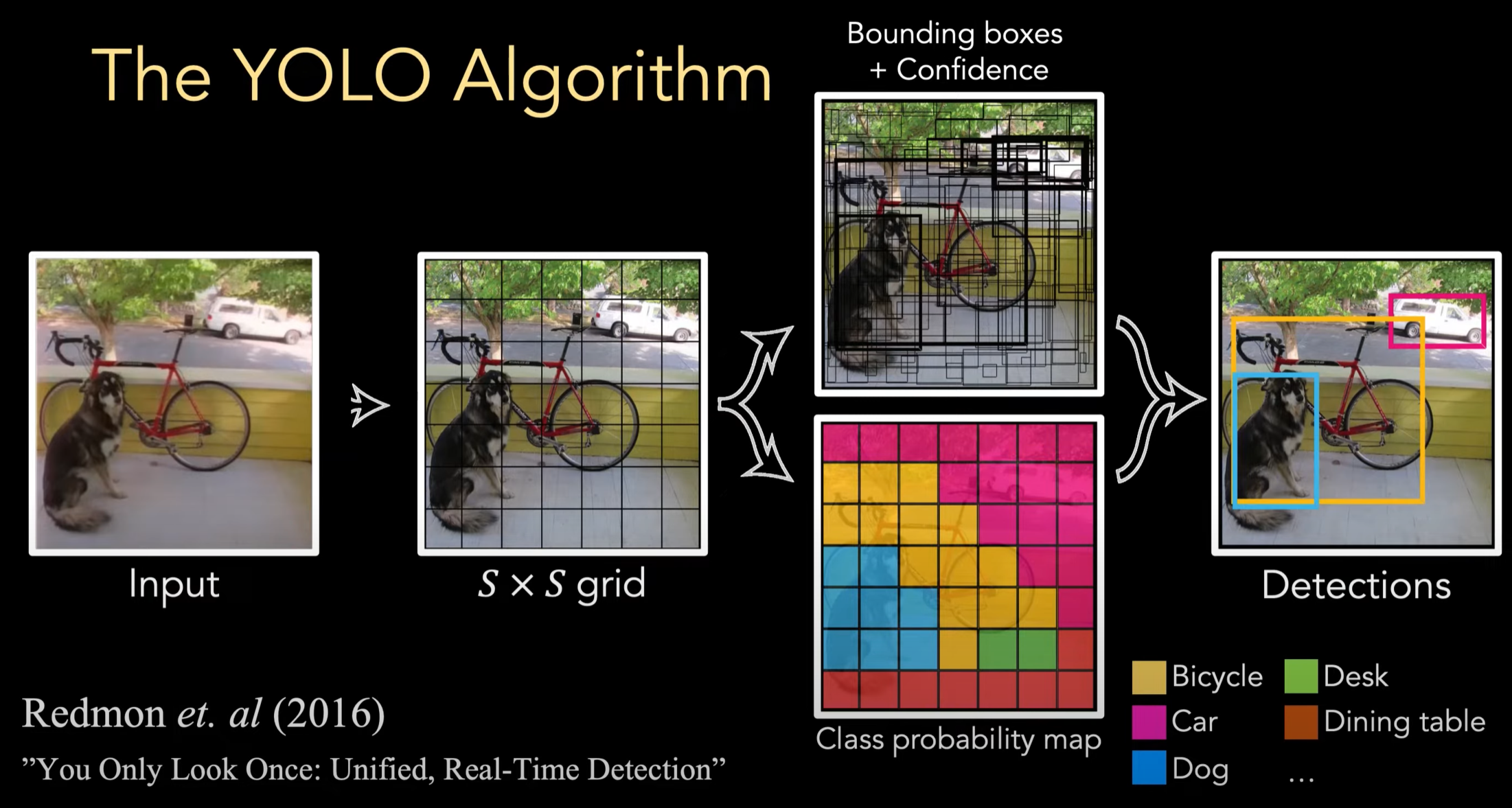
下面是一些符号:
- \(n\) 物体种类的个数
- \(S\) 一张图片总共分为 \(S×S\) 个 grid
- \(B\) 一个 grid 中 Bounding box 的数量
- \(x\ y\) 分别代表在一个 grid 中的位置, \(w\ h\) 分别表示 bounding box 的宽度、高度, \(C\) 代表 bounding box 中存在物体的置信度
在原论文中,S=7, B=2, n=20
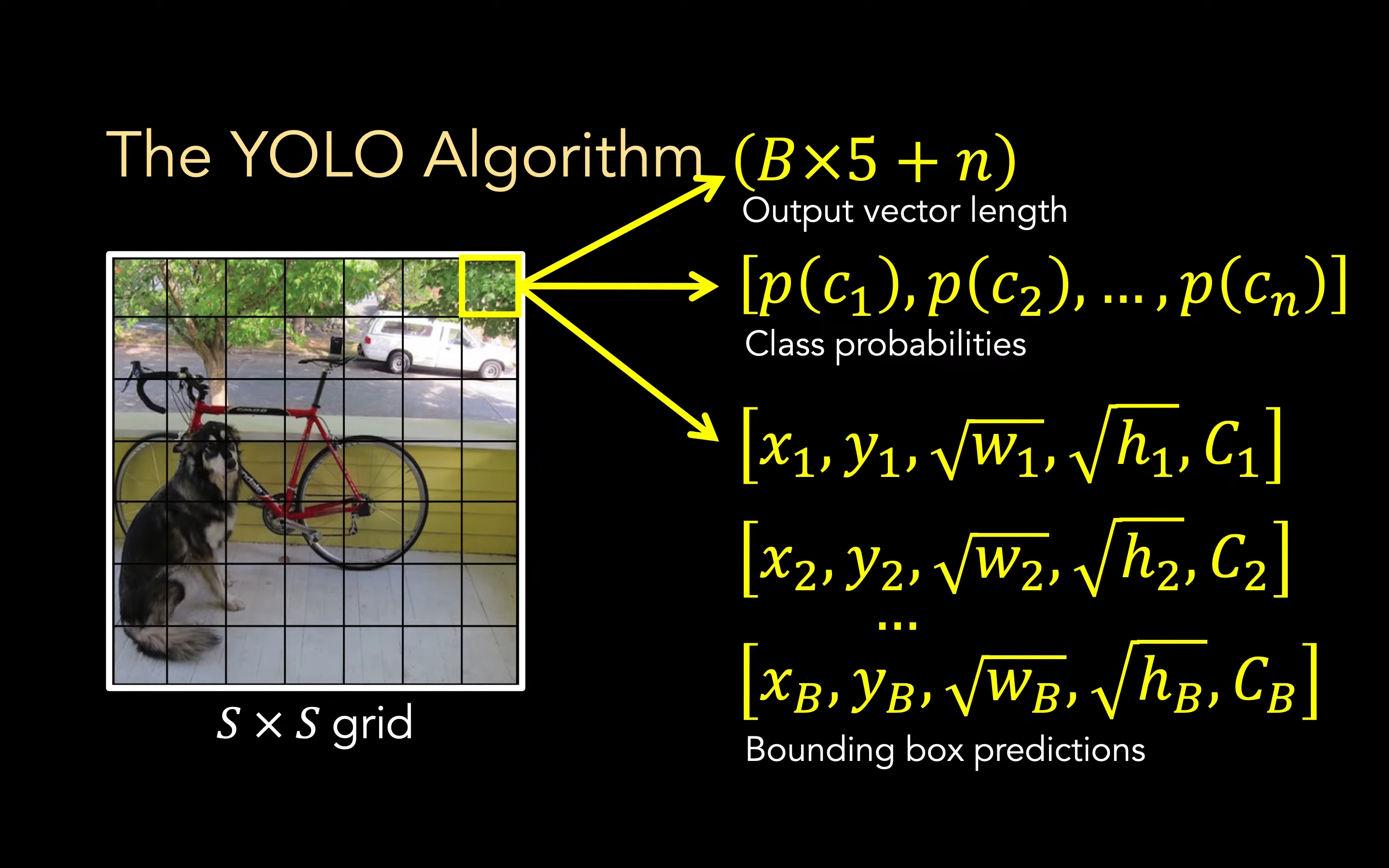
对于一个 grid 而言,我们的向量由以下构成:
- 分类概率,共有 \(n\) 项,即代表这个 grid 属于某个物体的概率,一共有 n 项
- Bounding box 预测 对于每个 bounding box 而言,我们要分别知道它的位置+框的大小+置信度,一共有 B 项,一项有 5 个
放进一个大向量中,长度即为 (B×5+n) 个,根据原论文数据共有 30 项
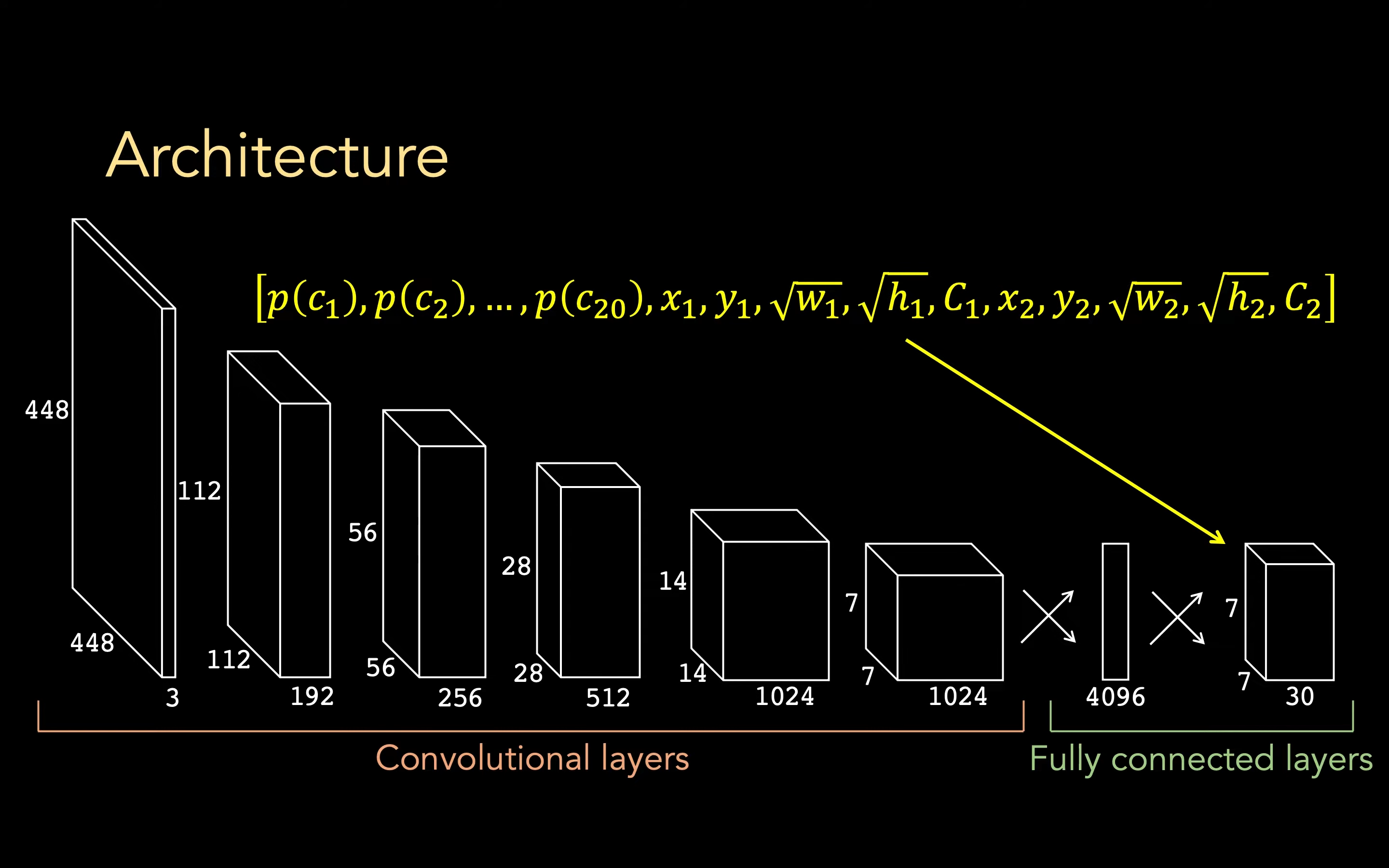
那么,对于一张图片输入而言,是如何转换为这样一个输出大向量的呢?YOLO 中就是使用 CNN来解决的:
可以看到,第一个输入的 448 _ 448 大小的图片,共有 RGB 3 个通道,经过若干层卷积变为 7 _ 7 _ 1024,然后摊平后通过一个 fc 变换为 4096,然后再通过一个 fc 变为 1470(7 _ 7 * 30)
这里的 30 即为一个 grid 中向量的个数,30 是论文的值
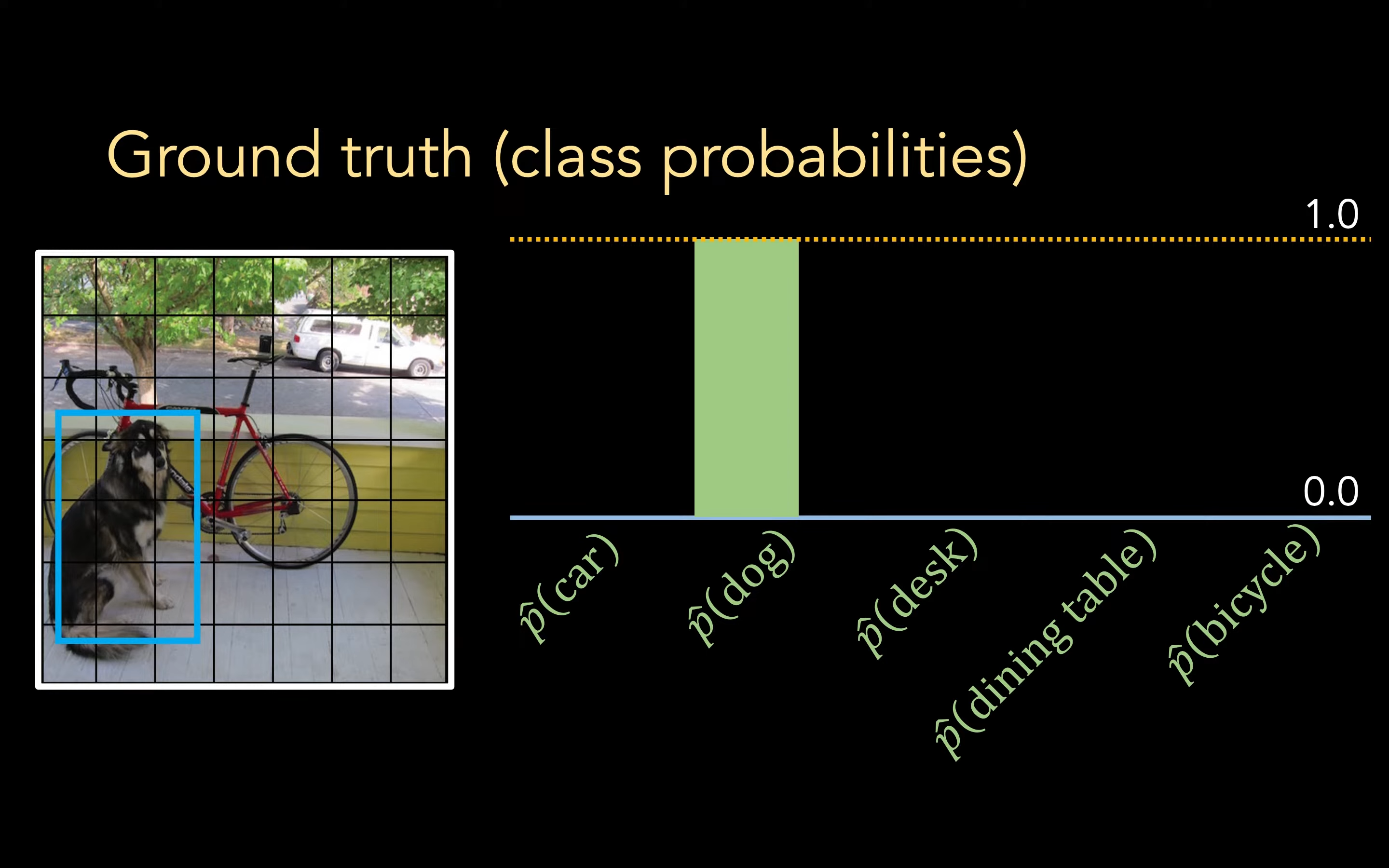
Ground Truth
对于分类概率而言,我们的 Ground truth 就是将正确的物体的概率设置为 1,YOLOv1 就是只支持在一个 grid 单个物体类别的识别(YOLOv3 后可以多类别)
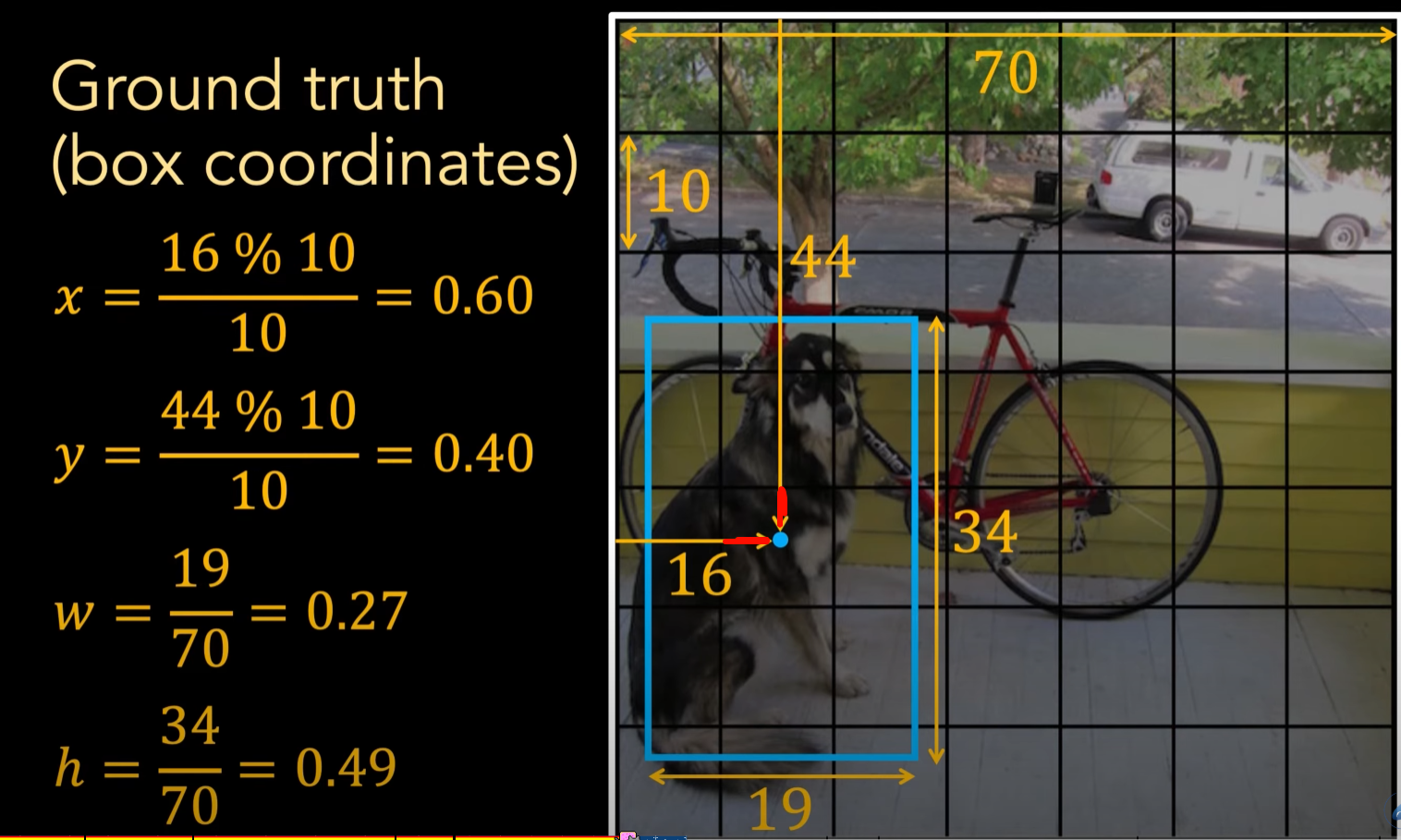
对于 x, y, w, h 这四个值而言(box coordinates),我们希望得到归一化的值:
- x、y 代表的是 bounding box 中心点位于 grid 的位置,所以我们用坐标系的位置对一个 grid 的边长取模即可得到(下图红色部分)
- w、h 是 bounding box 的宽度与长度,我们直接除以图片的宽度与长度即可得到归一化数值
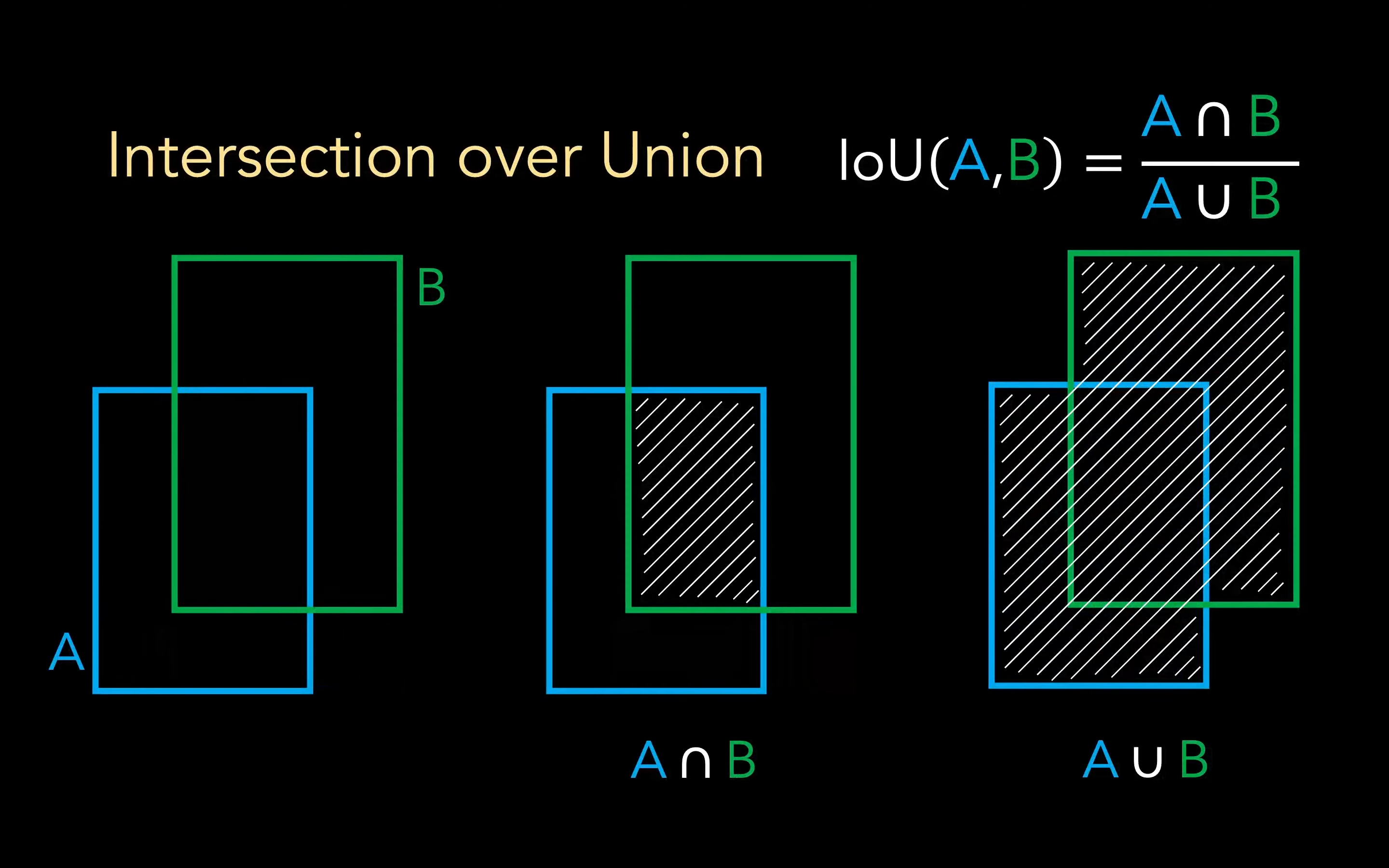
对于 Confidence 置信度 而言,一个 grid 的置信度等于预测部分与 Ground true 部分交叉面积 / 重叠面积,IoU 的意思是 Intersection over Union

Select box
During training
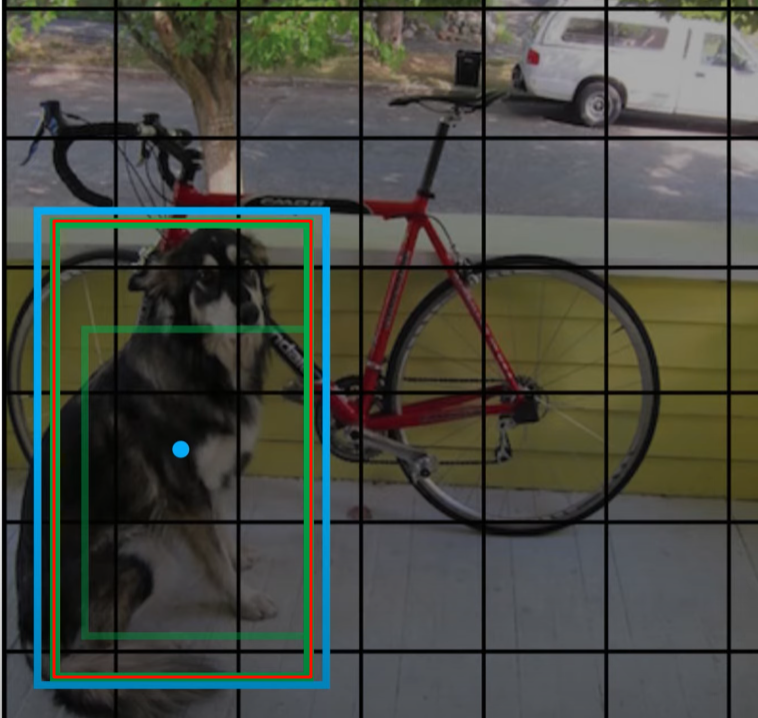
在训练的时候,我们知道,对于一个 grid 我们会有 \(B\) 个预测的 bounding box,那在训练的时候我们应该选择哪一个呢?YOLO 的方法是选择 IoU 最大的那一个,这样的选择可以提高分辨物体的能力。
比如下面这个,就是选择红色的那个 bouding box 而不是内部更小的绿色 bounding box:
During inference
在推理的时候,倘若我们有若干个 bounding box 都高于阈值(代表他们都可能是正确区域),我们会选择 置信度最大的那个,也就是希望我们选择 bounding box 更有可能有物体存在
这一操作叫做 Non max suppression

损失函数分析
这里 \(L_{cls}\) 指的是 class probability loss,分类方面的损失, \(L_{loc}\) 是 localization loss,是 bounding box 定位方面的损失
分类方面
这方面的损失仅在 grid 中有物体的时候才进行计算,如果是背景这类是不会计算的
YOLO 并没有使用交叉熵等方法,只是简单的用了一个 MSE 来表示这个的 loss
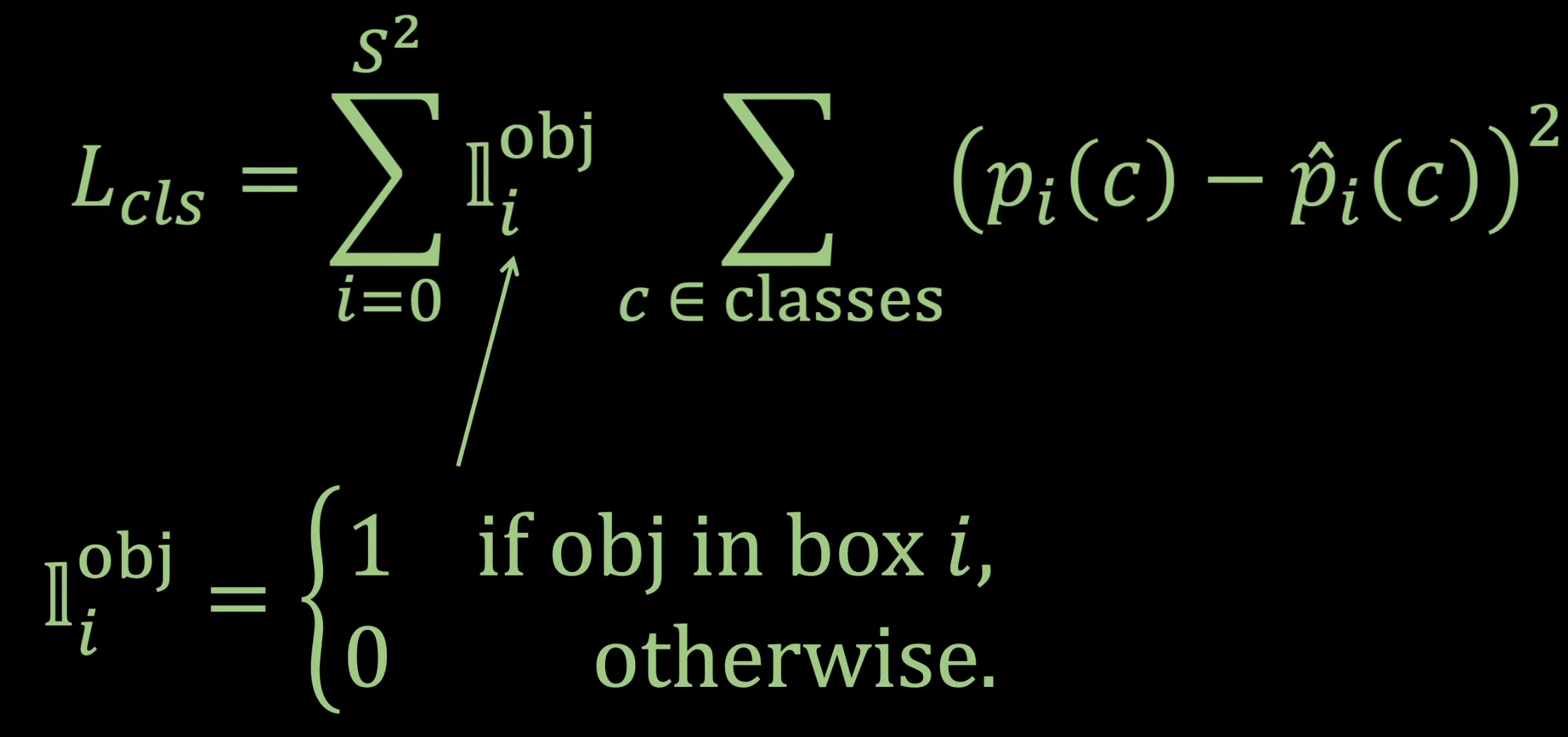
比如这张图,虽然我们给每个 grid 都分类为其中一个物体,但是我们不会对背景部分进行计算
定位方面
localization loss 又可以细分为
coord 指的是 coordinate,坐标方面的损失,conf 指的是 confidence,置信度方面的损失
坐标损失
我们先讲 \(L_{coord}\) ,coordinate 即为坐标方面的 loss,看下文公式中
这里的 \(\mathbb{I}_{ij}^{obj}\) :
这个是一个指示函数,表示:
- 当第
i个 grid 中第j个 bounding box负责预测某个 ground truth object 时为 1 - 否则为 0
意思是:我们只计算那些真正负责预测目标的框的误差。
为什么要引入 \(\lambda_{coord}\) 呢?这是用来调整坐标损失的相对重要性的,我们希望坐标方面的损失显得更加重要,让框框的位置跟大小更加合理
而 \(l\) 则是坐标方面真正的误差计算部分,同样是一个MSE 的损失计算
关键点在于 为何 YOLO 在 w 与 h 的计算要用到平方根来算呢?
因为 YOLO 的损失计算无法区分大框与小框相同差异下 小框的损失其实远远更高:
比如:
- 一个大框,
w = 200, 预测为 210,误差是 10 - 一个小框,
w = 10, 预测为 20,误差也是 10;
然而实际上小框实际上是很严重的误差
所以通过引入一个平方根,可以让大框的损失显得没那么大,变相限制了小框的更严重的损失
置信度损失
\(\mathbb{I}_{ij}^{obj}\) 的含义与上面介绍的相同,\(\mathbb{I}_{ij}^{noobj}\) 也就是相反的含义,代表第 i 个 grid 中第 j 个 bounding box 中没有 ground truth object 的情况
这部分的 loss 的目标是让预测的 confidence 趋近于目标的真实 confidence
前半部分很好理解,就是对有物体的部分作出置信度不相同的惩罚
但是为何要把后半部分没有物体的单独分开来呢?
因为我们的图片中实际上有大部分都是背景,而加入我们将这部分没有任何规律的背景也平等算入 loss 的计算中,就无法学到有效的模型,模型会趋向于只预测 noobj,全是背景,所以我们需要降低背景带来的影响,这里的 \(\lambda_{noobj}=0.5\) 就是原论文的数据,小于一代表希望减少影响
所以这部分的 loss 代表 没有目标的框预测出较大的置信度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号