谁是python上最快的xlsx writer
由于工作需要,需要使用pandas对几个csv进行筛选,并将筛选结果合并成一个xlsx。
生成的xlsx较大(10-30M)
最开始使用了pandas本身支持的openpyxl和xlsxwriter(those with a .xlsx extension will be written usingxlsxwriter (if available) or openpyxl.)
性能都不理想,输出要等好几分钟。
在google上找到了pyExcelerate,号称是Accelerated Excel XLSX writing library for Python
看了官方提供的benchmark,因为数值较小,当时觉得比起前两者提高有限,没有在意。

转而寻求C++动态库的方案,找到了libxl。
libxl动态库是C/C++语言直接操作excel文档的工具,看主页的benchmark
High performance
Writing speed is about 2 100 000 cells per second for numbers and 240 000 cells per second for 8-character random strings in binary xls format (CPU 3.2 GHz).
加上C的光环,感觉性能很猛的样子(现在回头看,发现人家说的是xls并非xlsx。)
但libxl是需要付费的,$199。
试用的话有读取行数的限制,会在输出的excel文件第一行插入
Created by LibXL trial version. Please buy the LibXL full version for removing this message.
因为需要生成的xlsx都在几十M,打开-删掉第一行-保存,还是比较不方便的。
遂寻找了好几个版本的破解版,貌似都不起作用,都有购买信息。。。
期间也被compile的事搞得团团转
//网上找一个libxl的python wrapper--“libxlpy”,为了解决在64位win8上完成lib编译,
//先后安装了VSE2008 ,Microsoft Visual C++ Compiler for Python 2.7 , WIN SDK。
//一直没能通过,随后放弃
各位爬虫,麻烦转载请注明来自博客园好吗?
http://www.cnblogs.com/lightwind/
目光重新回到pyExcelerate上,看到该库的作者是在Google工作的两位华人
Authors: Kevin Wang and Kevin Zhang
Copyright 2015 Kevin Wang, Kevin Zhang. Portions copyright Google, Inc.
随便找了一个文件试了试,感觉应该跟libxl不相上下,随即冒出了写一个脚本测试一下三者的性能的想法
开搞!
系统环境:
CPU i5 3337U, RAM 8GB, SSD
Win 8.1 64bit
Python 2.7.9
PyExcelerate 0.6.7
libxl 3.6.2
XlsxWriter 0.7.3
import time,ctypes import pandas as pd import pyexcelerate,xlsxwriter def test_pyexcelerate(fn_prefix,data): wb = pyexcelerate.Workbook() wb.new_sheet("sheet name", data=data) wb.save(fn_prefix+"_pyexcelerate.xlsx") def test_libxl(fn_prefix,data): dll = ctypes.windll.LoadLibrary('bin64_libxl_362.dll') book = dll.xlCreateXMLBookCA() sheet= dll.xlBookAddSheetA(book, "Sheet10", 0) for nrow,rec in enumerate(data, start = 1): # reserverd the first line for 'Created by LibXL trial version... ' for ncol,val in enumerate(rec, start = 0): #print 'row: %s , col: %s %s' % (nrow,ncol,type(val)) if isinstance(val,float): dll.xlSheetWriteNumA(sheet, nrow, ncol, ctypes.c_double(val), 0) else: dll.xlSheetWriteStrA(sheet, nrow, ncol, ctypes.c_char_p(val), 0) dll.xlBookSaveA(book, fn_prefix+"_libxl.xlsx") dll.xlBookReleaseA(book) def test_xlsxwriter(fn_prefix,data): workbook = xlsxwriter.Workbook(fn_prefix+"_xlsxwriter.xlsx") worksheet = workbook.add_worksheet() for nrow,rec in enumerate(data): for ncol,val in enumerate(rec): worksheet.write(nrow, ncol, val) workbook.close() def bench1(): for nline in (1000,10000,len(csv_data)): fn_prefix=fn[:-4]+'_'+str(nline) data = csv_data[:nline] print '*** %s lines xlsx benchmark ***' %nline for func in (test_pyexcelerate, test_libxl, test_xlsxwriter): t1=time.time() apply(func,(fn_prefix,data)) tm=time.time()-t1 print '%s: %0.3f' % (func.__name__, tm) print ' ' def bench2(func,fn,nline,csv_data): fn_prefix=fn[:-4]+'_'+str(nline) data = csv_data[:nline] print '*** %s lines xlsx benchmark ***' %nline t1=time.time() apply(func,(fn_prefix,data)) tm=time.time()-t1 print '%s: %0.3f' % (func.__name__, tm) print ' ' def test_xlsxwriter_to_excel(df,fn): print '*** to_excel xlsx benchmark ***' t1=time.time() df.to_excel(fn+'.xlsx', sheet_name='Sheet1',index=False) tm=time.time()-t1 print 'pandas to_excel(%s): %0.3f' % (pd.get_option('io.excel.xlsx.writer'),tm) if ( __name__ == "__main__"): fn ='EutranCellTdd.csv' df = pd.read_csv(fn,encoding='gbk',na_values=["no value"]) #,nrows=1000 df = df.fillna(0) #test_xlsxwriter_to_excel(df,fn) csv_data=df.values.tolist() #bench1() #for monitoring process memory usage. func=(test_pyexcelerate, test_libxl, test_xlsxwriter) bench2(func[2],fn,len(csv_data),csv_data)
测试的样本是1个有50列97613行的csv文件,其中5列是英文字符串,其余是数值。
测试结果如下:
*** 1000 lines xlsx benchmark *** test_pyexcelerate: 0.633 test_libxl: 0.531 test_xlsxwriter: 1.456 *** 10000 lines xlsx benchmark *** test_pyexcelerate: 5.974 test_libxl: 5.475 test_xlsxwriter: 13.685 *** 97613 lines xlsx benchmark *** test_pyexcelerate: 54.461 内存峰值 644M test_libxl: 51.090 内存峰值 1070M test_xlsxwriter: 117.300 内存峰值 930M *** to_excel xlsx benchmark *** pandas to_excel(xlsxwriter): 239.821 内存峰值922M
结果显示pyExcelerate与libxl速度差距很小,且内存占优。
由于此前看过的pyExcelerate官方提供的benchmark测试中,pyExcelerate速度差不多是xlsxwriter的2倍,因为最先用pandas的to_excel方法来生成excel文件很慢,所以误以为pyExcelerate也慢。
所以加入了最后一个测试项,结果说明虽然用的是xlsxwriter引擎,pandas在各个方面总是考虑周到,开销较大,所以尽量避免使用to_excel方法生成大文件。
总结:推荐使用pyExcelerate
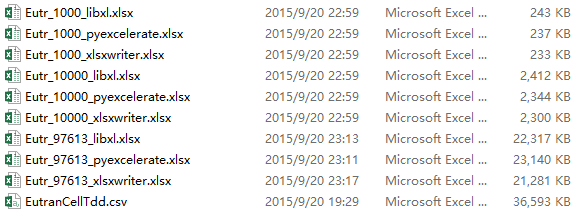
pyExcelerate 的文件是最大的,解压后发现其没有用SharedStrings,字符串是直接内联到xml中的,默认作弊,哈哈
XlsxWriter也是可以设置参数来取消SharedStrings,默认是使用SharedStrings
不使用SharedStrings貌似更省内存,但会使最终的生成文件变大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号