NL2API、NL2SQL、NL2CODE
NL2API、NL2SQL、NL2CODE
https://segmentfault.com/a/1190000044813098#item-3
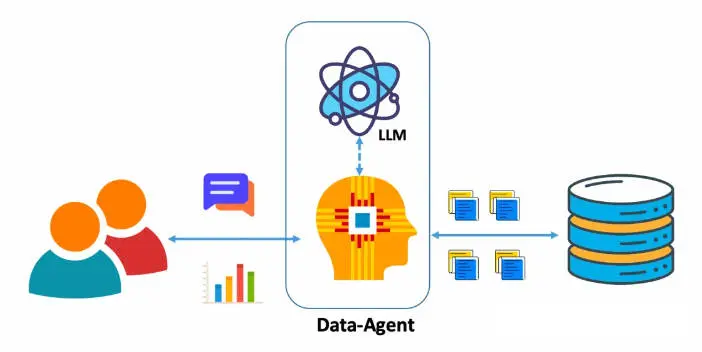
大模型之NL2SQL、数据智能分析简介

NL2SQL任务的目标是将用户对某个数据库的自然语言问题转化为相应的SQL查询。随着LLM的发展,使用LLM进行NL2SQL已成为一种新的范式。在这一过程中,如何利用提示工程来发掘LLM的NL2SQL能力显得尤为重要。
现状:大语言模型虽然在不断的迭代过程中越来越强大,但类似商业智能这样的企业级应用要远比分析一个 Excel 文件、总结一个 PDF 文件的问题要复杂的多:
- 数据结构复杂:企业信息系统的数据结构复杂性远远超过几个简单的 Excel 文件,一个大型企业应用可能存在几百上千个数据实体,所以在实际应用中,大型 BI 系统会在前端经过汇聚、简化与抽象成新的语义层,方便理解。
- 数据量较大:分析类应用以海量历史数据为主,即使一些数据在分析之前会经过多级汇总处理。这决定了无法在企业应用中把数据简单的脱机成文件进行分析处理。
- 分析需求复杂:企业应用的数据分析需求涵盖及时查询、到各个维度的报表与指标展现、数据的上下钻、潜在信息的挖掘等,很多需求有较复杂的后端处理逻辑。
这些特点决定了,当前大语言模型在企业数据分析中的应用无法完全的取代目前所有的或者部分的分析工具。其合适的定位或许是:作为现有数据分析手段的一种有效补充,在部分需求场景下,给经营决策人员提供一种更易于使用与交互的分析工具。
具体的应用场景包括:
- 及时数据查询。提供对运营或统计数据的简单自定义查询,当然你只需要使用自然语言。
- 传统 BI 工具能力的升级。很多传统 BI 工具会定义一个抽象的语义层,其本身的意义之一就是为了让数据分析对业务人员更友好。而大模型天然具有强大的语义理解能力,因此将传统 BI 中的一些功能进化到基于自然语言的交互式分析,是非常水到渠成的。
- 简单的数据挖掘与洞察。在某些场景下的交互式数据挖掘与洞察,可以利用大语言模型的 Code 生成能力与算法实现对数据隐藏模式的发现。
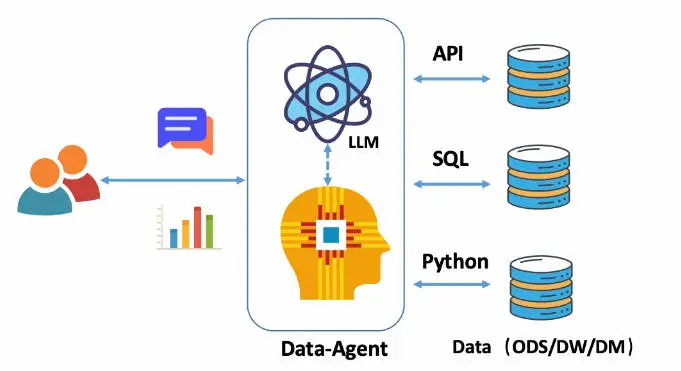
1.1 三种基础技术方案介绍

-
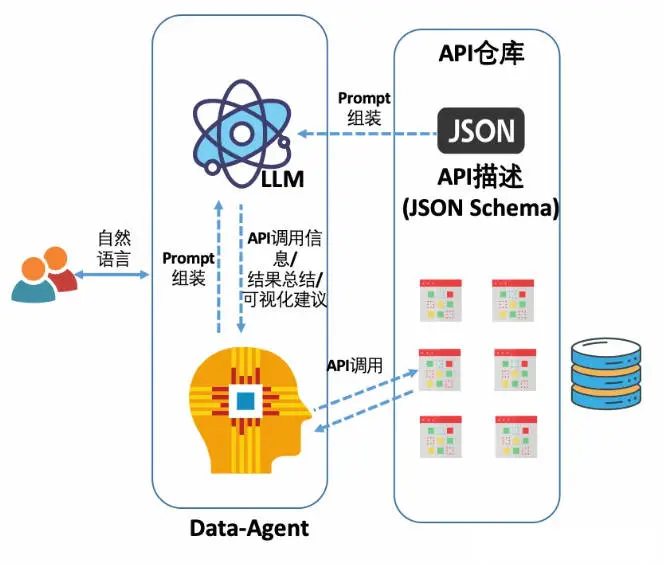
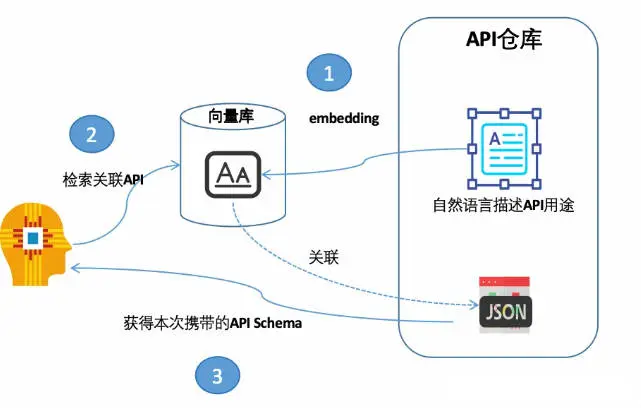
自然语言转数据分析的 API,text2API
类似现有的一些 BI 工具会基于自己的语义层开放出独立的 API 用于扩展应用,因此如果把自然语言转成对这些数据分析 API 的调用,是一种很自然的实现方式。当然完全也可以自己实现这个 API 层。
这个方案的特点是受到 API 层的制约,在后面我们会分析。
-
-
自然语言转关系数据库 SQL,text2SQL
这也是目前最受关注的一种大模型能力(本质上也是一种特殊的 text2code)。由于 SQL 是一种相对标准化的数据库查询语言,且完全由数据库自身来解释执行,因此把自然语言转成 SQL 是最简单合理、实现路径最短的一种解决方案。
-
自然语言转数据分析的语言代码,即 text2Code
即代码解释器方案。简单的说,就是让 AI 自己编写代码(通常是 Python)然后自动在本地或者沙箱中运行后获得分析结果。当然目前的 Code Interpreter 大多是针对本地数据的分析处理(如 csv 文件),因此在面对企业应用中的数据库内数据时,需要在使用场景上做特别考虑。
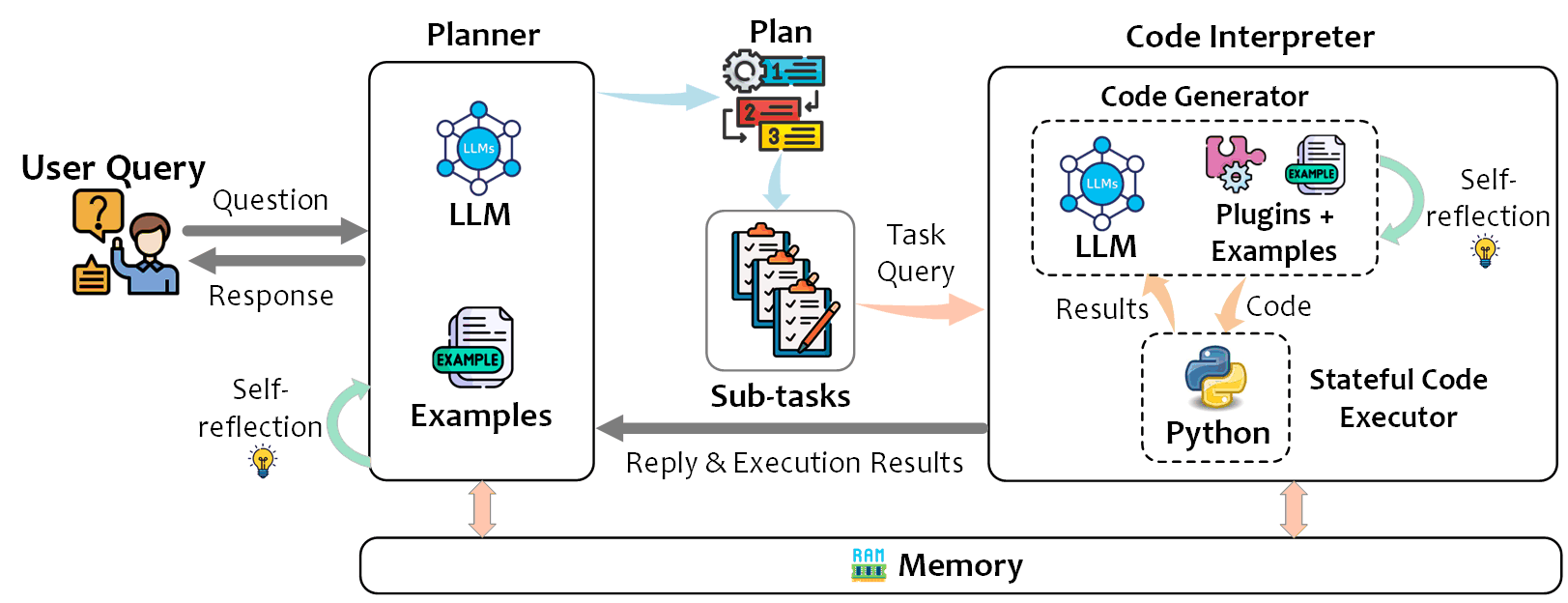
taskweaver -- NL2CODE
https://github.com/microsoft/taskweaver/
TaskWeaver is A code-first agent framework for seamlessly planning and executing data analytics tasks. This innovative framework interprets user requests through code snippets and efficiently coordinates a variety of plugins in the form of functions to execute data analytics tasks in a stateful manner.
Unlike many agent frameworks that only track the chat history with LLMs in text, TaskWeaver preserves both the chat history and the code execution history, including the in-memory data. This feature enhances the expressiveness of the agent framework, making it ideal for processing complex data structures like high-dimensional tabular data.

DB-GPT --- DB-GPT: AI Native Data App Development framework with AWEL and Agents ---- text2sql
https://github.com/eosphoros-ai/DB-GPT
🤖 DB-GPT is an open source AI native data app development framework with AWEL(Agentic Workflow Expression Language) and agents.
The purpose is to build infrastructure in the field of large models, through the development of multiple technical capabilities such as multi-model management (SMMF), Text2SQL effect optimization, RAG framework and optimization, Multi-Agents framework collaboration, AWEL (agent workflow orchestration), etc. Which makes large model applications with data simpler and more convenient.
🚀 In the Data 3.0 era, based on models and databases, enterprises and developers can build their own bespoke applications with less code.
The architecture of DB-GPT is shown in the following figure:

The core capabilities include the following parts:
-
RAG (Retrieval Augmented Generation): RAG is currently the most practically implemented and urgently needed domain. DB-GPT has already implemented a framework based on RAG, allowing users to build knowledge-based applications using the RAG capabilities of DB-GPT.
-
GBI (Generative Business Intelligence): Generative BI is one of the core capabilities of the DB-GPT project, providing the foundational data intelligence technology to build enterprise report analysis and business insights.
-
Fine-tuning Framework: Model fine-tuning is an indispensable capability for any enterprise to implement in vertical and niche domains. DB-GPT provides a complete fine-tuning framework that integrates seamlessly with the DB-GPT project. In recent fine-tuning efforts, an accuracy rate based on the Spider dataset has been achieved at 82.5%.
-
Data-Driven Multi-Agents Framework: DB-GPT offers a data-driven self-evolving multi-agents framework, aiming to continuously make decisions and execute based on data.
-
Data Factory: The Data Factory is mainly about cleaning and processing trustworthy knowledge and data in the era of large models.
-
Data Sources: Integrating various data sources to seamlessly connect production business data to the core capabilities of DB-GPT.
-
DB-GPT-Hub Text-to-SQL workflow with high performance by applying Supervised Fine-Tuning (SFT) on Large Language Models (LLMs).
-
dbgpts dbgpts is the official repository which contains some data apps、AWEL operators、AWEL workflow templates and agents which build upon DB-GPT.
| LLM | Supported |
|---|---|
| LLaMA | ✅ |
| LLaMA-2 | ✅ |
| BLOOM | ✅ |
| BLOOMZ | ✅ |
| Falcon | ✅ |
| Baichuan | ✅ |
| Baichuan2 | ✅ |
| InternLM | ✅ |
| Qwen | ✅ |
| XVERSE | ✅ |
| ChatGLM2 | ✅ |
More Information about Text2SQL finetune
- DB-GPT-Plugins DB-GPT Plugins that can run Auto-GPT plugin directly
- GPT-Vis Visualization protocol
vanna --- text2sql
https://github.com/vanna-ai/vanna
Vanna is an MIT-licensed open-source Python RAG (Retrieval-Augmented Generation) framework for SQL generation and related functionality.
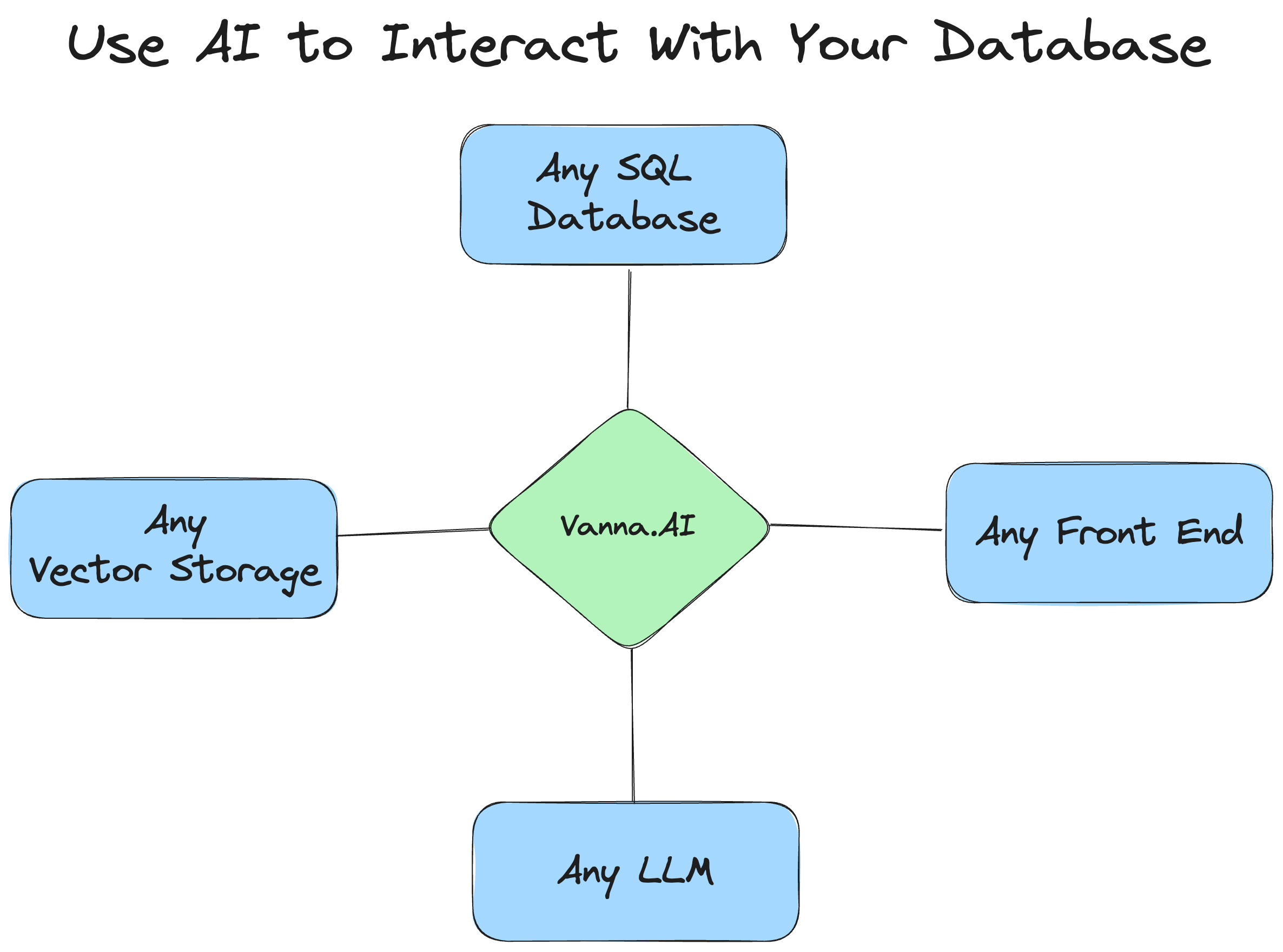
Vanna works in two easy steps - train a RAG "model" on your data, and then ask questions which will return SQL queries that can be set up to automatically run on your database.
- Train a RAG "model" on your data.
- Ask questions.
If you don't know what RAG is, don't worry -- you don't need to know how this works under the hood to use it. You just need to know that you "train" a model, which stores some metadata and then use it to "ask" questions.
See the base class for more details on how this works under the hood.
Data-Copilot
https://github.com/zwq2018/Data-Copilot
Data-Copilot is a LLM-based system that help you address data-related tasks.
Data-Copilot connects data sources from different domains and diverse user tastes, with the ability to autonomously manage, process, analyze, predict, and visualize data.

See our paper: Data-Copilot: Bridging Billions of Data and Humans with Autonomous Workflow, Wenqi Zhang, Yongliang Shen, Weiming Lu, Yueting Zhuang
Chat2DB
https://github.com/CodePhiliaX/Chat2DB
Chat2DB is an intelligent, universal SQL client and data reporting tool that integrates AI capabilities. Chat2DB helps you write SQL queries faster, manage databases, generate reports, explore data, and interact with multiple databases. Chat2DB is an open-source project, and we welcome your contributions.
1. Intelligent SQL Generation:
Chat2DB Pro supports AI-driven intelligent SQL development to help you write SQL queries faster.
2. Database Management:
Supports more than 10 databases, including MySQL, PostgreSQL, H2,
Oracle, SQLServer, SQLite, MariaDB, ClickHouse, DM, Presto, DB2,
OceanBase, Hive, KingBase, MongoDB, Redis, Snowflake, and more.
3. Intelligent Report Generation:
Chat2DB Pro supports AI-driven intelligent data reporting to help you generate dashboards faster.
4. Data Structure Synchronization:
重试
Chat2DB Pro supports database table structure synchronization to help you sync database table structures faster.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号