deer-flow (字节 deep research)
deer-flow
https://github.com/bytedance/deer-flow
DeerFlow is a community-driven Deep Research framework, combining language models with tools like web search, crawling, and Python execution, while contributing back to the open-source community.
DeerFlow
English | 简体中文 | 日本語 | Deutsch | Español | Русский | Portuguese
Originated from Open Source, give back to Open Source.
DeerFlow (Deep Exploration and Efficient Research Flow) is a community-driven Deep Research framework that builds upon the incredible work of the open source community. Our goal is to combine language models with specialized tools for tasks like web search, crawling, and Python code execution, while giving back to the community that made this possible.
Currently, DeerFlow has officially entered the FaaS Application Center of Volcengine. Users can experience it online through the experience link to intuitively feel its powerful functions and convenient operations. At the same time, to meet the deployment needs of different users, DeerFlow supports one-click deployment based on Volcengine. Click the deployment link to quickly complete the deployment process and start an efficient research journey.
Please visit our official website for more details.
In this demo, we showcase how to use DeerFlow to:
- Seamlessly integrate with MCP services
- Conduct the Deep Research process and produce a comprehensive report with images
- Create podcast audio based on the generated report
DeerFlow supports multiple search engines that can be configured in your .env file using the SEARCH_API variable:
-
Tavily (default): A specialized search API for AI applications
- Requires
TAVILY_API_KEYin your.envfile - Sign up at: https://app.tavily.com/home
- Requires
-
DuckDuckGo: Privacy-focused search engine
- No API key required
-
Brave Search: Privacy-focused search engine with advanced features
- Requires
BRAVE_SEARCH_API_KEYin your.envfile - Sign up at: https://brave.com/search/api/
- Requires
-
Arxiv: Scientific paper search for academic research
- No API key required
- Specialized for scientific and academic papers
To configure your preferred search engine, set the SEARCH_API variable in your .env file:
# Choose one: tavily, duckduckgo, brave_search, arxiv
SEARCH_API=tavily
- 🤖 LLM Integration
- It supports the integration of most models through litellm.
- Support for open source models like Qwen
- OpenAI-compatible API interface
- Multi-tier LLM system for different task complexities
-
🔗 MCP Seamless Integration
- Expand capabilities for private domain access, knowledge graph, web browsing and more
- Facilitates integration of diverse research tools and methodologies
-
🧠 Human-in-the-loop
- Supports interactive modification of research plans using natural language
- Supports auto-acceptance of research plans
-
📝 Report Post-Editing
- Supports Notion-like block editing
- Allows AI refinements, including AI-assisted polishing, sentence shortening, and expansion
- Powered by tiptap
- 🎙️ Podcast and Presentation Generation
- AI-powered podcast script generation and audio synthesis
- Automated creation of simple PowerPoint presentations
- Customizable templates for tailored content
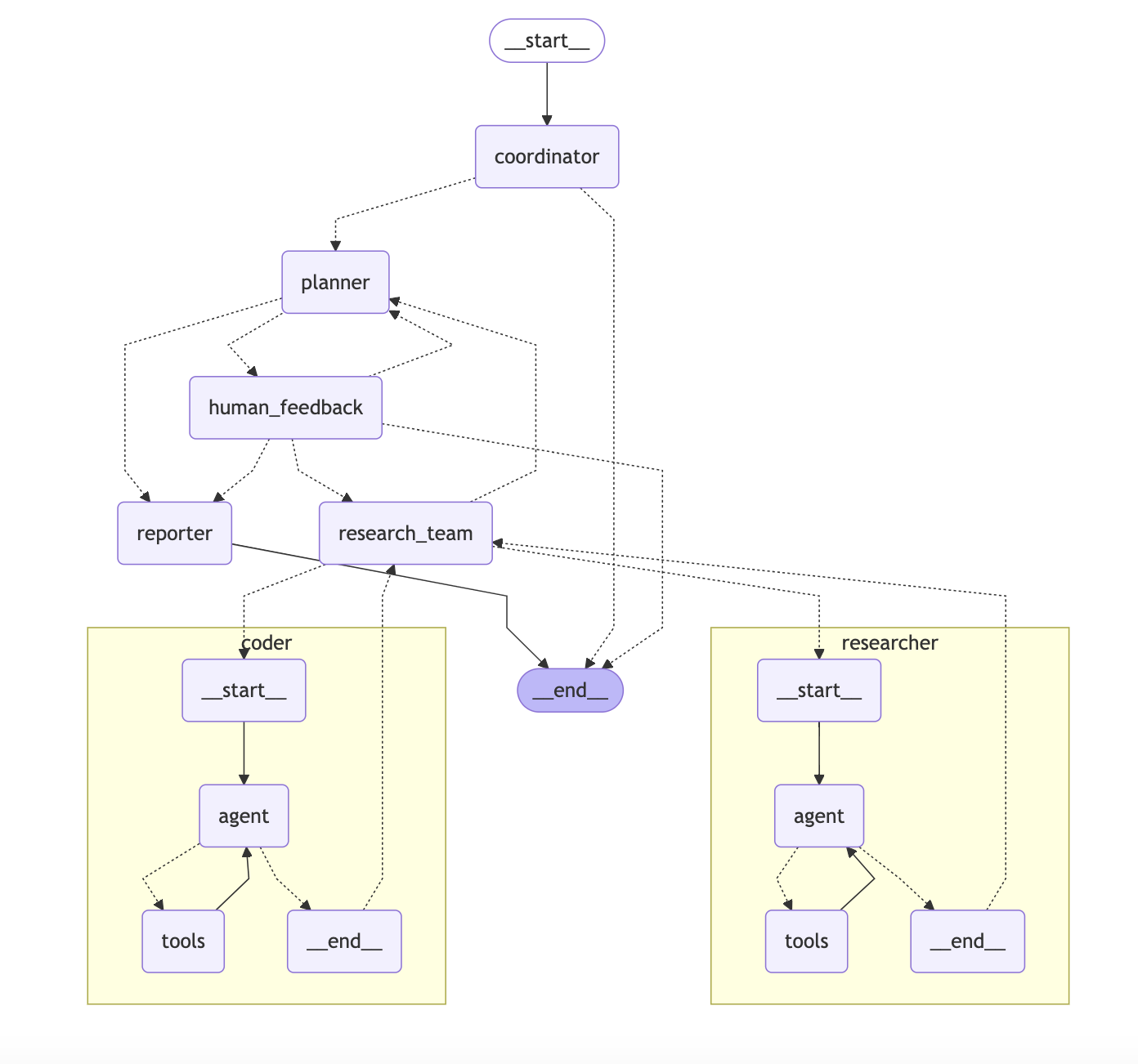
DeerFlow implements a modular multi-agent system architecture designed for automated research and code analysis. The system is built on LangGraph, enabling a flexible state-based workflow where components communicate through a well-defined message passing system.

See it live at deerflow.tech
The system employs a streamlined workflow with the following components:
-
Coordinator: The entry point that manages the workflow lifecycle
- Initiates the research process based on user input
- Delegates tasks to the planner when appropriate
- Acts as the primary interface between the user and the system
-
Planner: Strategic component for task decomposition and planning
- Analyzes research objectives and creates structured execution plans
- Determines if enough context is available or if more research is needed
- Manages the research flow and decides when to generate the final report
-
Research Team: A collection of specialized agents that execute the plan:
- Researcher: Conducts web searches and information gathering using tools like web search engines, crawling and even MCP services.
- Coder: Handles code analysis, execution, and technical tasks using Python REPL tool. Each agent has access to specific tools optimized for their role and operates within the LangGraph framework
-
Reporter: Final stage processor for research outputs
- Aggregates findings from the research team
- Processes and structures the collected information
- Generates comprehensive research reports
-
🔍 Search and Retrieval
- Web search via Tavily, Brave Search and more
- Crawling with Jina
- Advanced content extraction
-
📃 RAG Integration
- Supports mentioning files from RAGFlow within the input box. Start up RAGFlow server.
# .env RAG_PROVIDER=ragflow RAGFLOW_API_URL="http://localhost:9388" RAGFLOW_API_KEY="ragflow-xxx" RAGFLOW_RETRIEVAL_SIZE=10
https://github.com/fanqingsong/deer-flow

 浙公网安备 33010602011771号
浙公网安备 33010602011771号