local-deep-researcher(langchain-ai)
local-deep-researcher
https://github.com/langchain-ai/local-deep-researcher
Fully local web research and report writing assistant
Local Deep Researcher is a fully local web research assistant that uses any LLM hosted by Ollama or LMStudio. Give it a topic and it will generate a web search query, gather web search results, summarize the results of web search, reflect on the summary to examine knowledge gaps, generate a new search query to address the gaps, and repeat for a user-defined number of cycles. It will provide the user a final markdown summary with all sources used to generate the summary.

Short summary video:
Ollama.Deep.Researcher.Overview-enhanced-v2-90p.mp4
📺 Video Tutorials
Local Deep Researcher is inspired by IterDRAG. This approach will decompose a query into sub-queries, retrieve documents for each one, answer the sub-query, and then build on the answer by retrieving docs for the second sub-query. Here, we do similar:
- Given a user-provided topic, use a local LLM (via Ollama or LMStudio) to generate a web search query
- Uses a search engine / tool to find relevant sources
- Uses LLM to summarize the findings from web search related to the user-provided research topic
- Then, it uses the LLM to reflect on the summary, identifying knowledge gaps
- It generates a new search query to address the knowledge gaps
- The process repeats, with the summary being iteratively updated with new information from web search
- Runs for a configurable number of iterations (see
configurationtab)
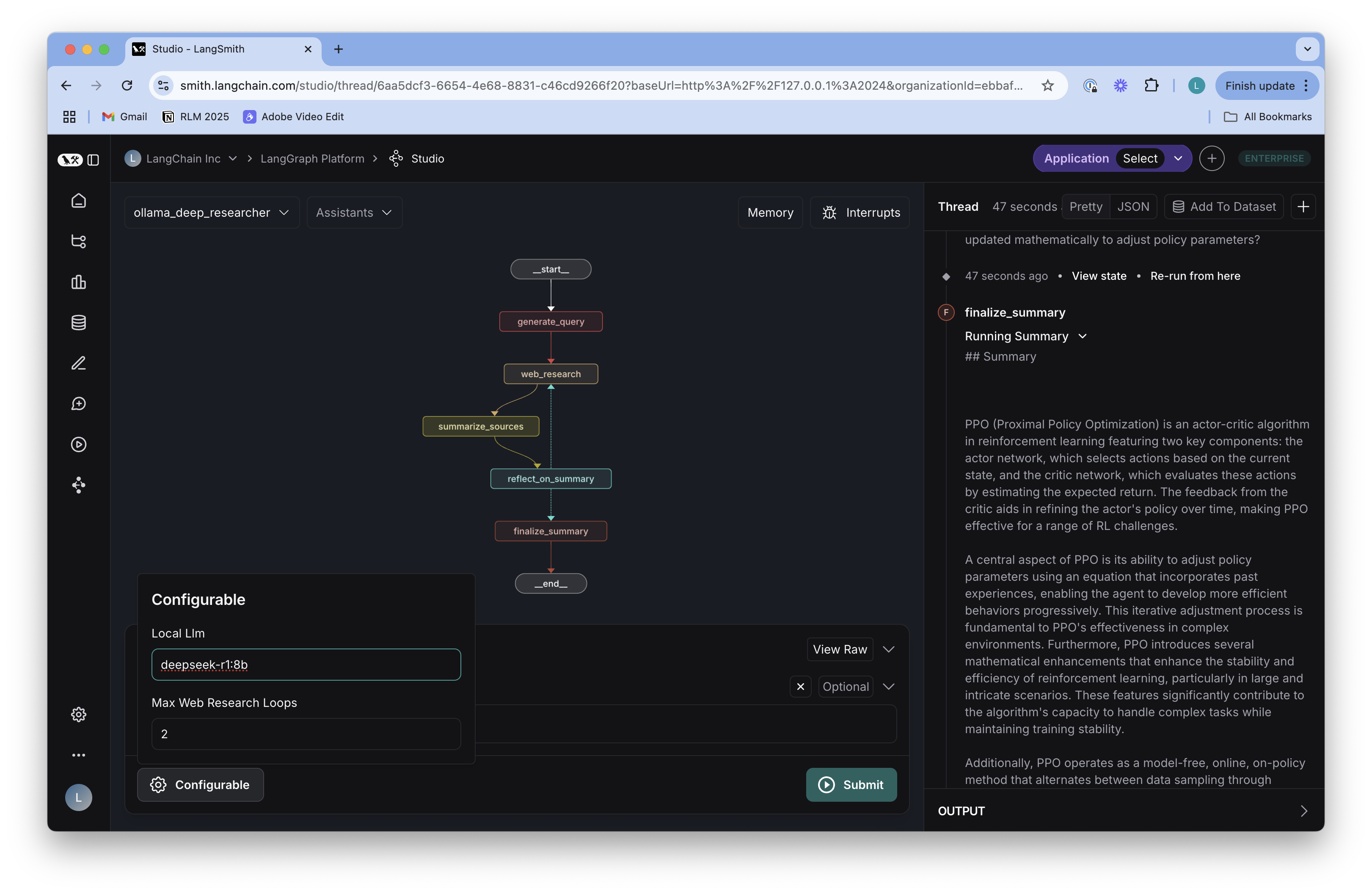
The output of the graph is a markdown file containing the research summary, with citations to the sources used. All sources gathered during research are saved to the graph state. You can visualize them in the graph state, which is visible in LangGraph Studio:

The final summary is saved to the graph state as well:

Code - GRAPH
""" 这个文件实现了一个基于LangGraph的自动化研究助手。 它使用有向图的方式组织多个功能节点,实现自动化的网络研究和总结过程。 主要组件: 1. 查询生成器 (generate_query) - 基于研究主题生成搜索查询 2. 网络研究器 (web_research) - 使用不同搜索API进行网络搜索 3. 信息总结器 (summarize_sources) - 对搜索结果进行总结 4. 反思分析器 (reflect_on_summary) - 分析知识空缺并生成后续查询 5. 最终总结器 (finalize_summary) - 生成最终的研究报告 工作流程: START -> 生成查询 -> 网络研究 -> 总结信息 -> 反思分析 -> [继续研究或完成] -> END """ import json from typing_extensions import Literal from langchain_core.messages import HumanMessage, SystemMessage from langchain_core.runnables import RunnableConfig from langchain_ollama import ChatOllama from langgraph.graph import START, END, StateGraph from ollama_deep_researcher.configuration import Configuration, SearchAPI from ollama_deep_researcher.utils import deduplicate_and_format_sources, tavily_search, format_sources, perplexity_search, duckduckgo_search, searxng_search, strip_thinking_tokens, get_config_value from ollama_deep_researcher.state import SummaryState, SummaryStateInput, SummaryStateOutput from ollama_deep_researcher.prompts import query_writer_instructions, summarizer_instructions, reflection_instructions, get_current_date from ollama_deep_researcher.lmstudio import ChatLMStudio # LangGraph节点定义 def generate_query(state: SummaryState, config: RunnableConfig): """根据研究主题生成优化的搜索查询。 该节点使用LLM(语言模型)基于用户的研究主题创建优化的搜索查询。 支持LMStudio和Ollama作为LLM提供者。 参数: state: 包含研究主题的当前图状态 config: 包含LLM提供者设置的运行时配置 返回: 包含生成的搜索查询的状态更新字典 """ # 格式化提示信息 current_date = get_current_date() formatted_prompt = query_writer_instructions.format( current_date=current_date, research_topic=state.research_topic ) # 生成查询 configurable = Configuration.from_runnable_config(config) # 根据提供者选择合适的LLM if configurable.llm_provider == "lmstudio": llm_json_mode = ChatLMStudio( base_url=configurable.lmstudio_base_url, model=configurable.local_llm, temperature=0, format="json" ) else: # 默认使用Ollama llm_json_mode = ChatOllama( base_url=configurable.ollama_base_url, model=configurable.local_llm, temperature=0, format="json" ) result = llm_json_mode.invoke( [SystemMessage(content=formatted_prompt), HumanMessage(content=f"Generate a query for web search:")] ) # 获取内容 content = result.content # 解析JSON响应并获取查询 try: query = json.loads(content) search_query = query['query'] except (json.JSONDecodeError, KeyError): # 如果解析失败或未找到键,则使用备用查询 if configurable.strip_thinking_tokens: content = strip_thinking_tokens(content) search_query = content return {"search_query": search_query} def web_research(state: SummaryState, config: RunnableConfig): """执行网络研究,使用生成的搜索查询搜索相关信息。 使用配置的搜索API(tavily, perplexity, duckduckgo或searxng)执行网络搜索, 并格式化结果供后续处理。 参数: state: 包含搜索查询和研究循环计数的当前状态 config: 包含搜索API设置的配置 返回: 包含搜集的来源、研究循环计数和网络研究结果的状态更新 """ # 配置 configurable = Configuration.from_runnable_config(config) # 获取搜索API search_api = get_config_value(configurable.search_api) # 搜索网络 if search_api == "tavily": search_results = tavily_search(state.search_query, fetch_full_page=configurable.fetch_full_page, max_results=1) search_str = deduplicate_and_format_sources(search_results, max_tokens_per_source=1000, fetch_full_page=configurable.fetch_full_page) elif search_api == "perplexity": search_results = perplexity_search(state.search_query, state.research_loop_count) search_str = deduplicate_and_format_sources(search_results, max_tokens_per_source=1000, fetch_full_page=configurable.fetch_full_page) elif search_api == "duckduckgo": search_results = duckduckgo_search(state.search_query, max_results=3, fetch_full_page=configurable.fetch_full_page) search_str = deduplicate_and_format_sources(search_results, max_tokens_per_source=1000, fetch_full_page=configurable.fetch_full_page) elif search_api == "searxng": search_results = searxng_search(state.search_query, max_results=3, fetch_full_page=configurable.fetch_full_page) search_str = deduplicate_and_format_sources(search_results, max_tokens_per_source=1000, fetch_full_page=configurable.fetch_full_page) else: raise ValueError(f"Unsupported search API: {configurable.search_api}") return {"sources_gathered": [format_sources(search_results)], "research_loop_count": state.research_loop_count + 1, "web_research_results": [search_str]} def summarize_sources(state: SummaryState, config: RunnableConfig): """总结网络研究结果。 使用LLM基于最新的网络研究结果创建或更新运行总结, 将新信息与现有总结整合。 参数: state: 包含研究主题、运行总结和网络研究结果的当前状态 config: 包含LLM提供者设置的配置 返回: 包含更新后总结的状态更新字典 """ # 现有总结 existing_summary = state.running_summary # 最近的网络研究 most_recent_web_research = state.web_research_results[-1] # 构建用户消息 if existing_summary: human_message_content = ( f"<Existing Summary> \n {existing_summary} \n <Existing Summary>\n\n" f"<New Context> \n {most_recent_web_research} \n <New Context>" f"Update the Existing Summary with the New Context on this topic: \n <User Input> \n {state.research_topic} \n <User Input>\n\n" ) else: human_message_content = ( f"<Context> \n {most_recent_web_research} \n <Context>" f"Create a Summary using the Context on this topic: \n <User Input> \n {state.research_topic} \n <User Input>\n\n" ) # 运行LLM configurable = Configuration.from_runnable_config(config) # 根据提供者选择合适的LLM if configurable.llm_provider == "lmstudio": llm = ChatLMStudio( base_url=configurable.lmstudio_base_url, model=configurable.local_llm, temperature=0 ) else: # 默认使用Ollama llm = ChatOllama( base_url=configurable.ollama_base_url, model=configurable.local_llm, temperature=0 ) result = llm.invoke( [SystemMessage(content=summarizer_instructions), HumanMessage(content=human_message_content)] ) # 如果配置了,去除思维提示词 running_summary = result.content if configurable.strip_thinking_tokens: running_summary = strip_thinking_tokens(running_summary) return {"running_summary": running_summary} def reflect_on_summary(state: SummaryState, config: RunnableConfig): """识别知识空缺并生成后续查询。 分析当前总结以识别需要进一步研究的领域,并生成新的搜索查询来填补这些空缺。 使用结构化输出以JSON格式提取后续查询。 参数: state: 包含运行总结和研究主题的当前状态 config: 包含LLM提供者设置的配置 返回: 包含生成的后续查询的状态更新字典 """ # 生成查询 configurable = Configuration.from_runnable_config(config) # 根据提供者选择合适的LLM if configurable.llm_provider == "lmstudio": llm_json_mode = ChatLMStudio( base_url=configurable.lmstudio_base_url, model=configurable.local_llm, temperature=0, format="json" ) else: # 默认使用Ollama llm_json_mode = ChatOllama( base_url=configurable.ollama_base_url, model=configurable.local_llm, temperature=0, format="json" ) result = llm_json_mode.invoke( [SystemMessage(content=reflection_instructions.format(research_topic=state.research_topic)), HumanMessage(content=f"Reflect on our existing knowledge: \n === \n {state.running_summary}, \n === \n And now identify a knowledge gap and generate a follow-up web search query:")] ) # 如果配置了,去除思维提示词 try: # 尝试先解析为JSON reflection_content = json.loads(result.content) # 获取后续查询 query = reflection_content.get('follow_up_query') # 检查查询是否为空 if not query: # 使用备用查询 return {"search_query": f"Tell me more about {state.research_topic}"} return {"search_query": query} except (json.JSONDecodeError, KeyError, AttributeError): # 如果解析失败或未找到键,则使用备用查询 return {"search_query": f"Tell me more about {state.research_topic}"} def finalize_summary(state: SummaryState): """完成研究总结。 通过去重和格式化来源,然后将它们与运行总结结合, 创建一个结构良好的带有适当引用的研究报告。 参数: state: 包含运行总结和搜集的来源的当前状态 返回: 包含带有来源的格式化最终总结的状态更新字典 """ # 在合并之前去重来源 seen_sources = set() unique_sources = [] for source in state.sources_gathered: # 拆分来源为多行并逐行处理 for line in source.split('\n'): # 仅处理非空行 if line.strip() and line not in seen_sources: seen_sources.add(line) unique_sources.append(line) # 合并去重后的来源 all_sources = "\n".join(unique_sources) state.running_summary = f"## Summary\n{state.running_summary}\n\n ### Sources:\n{all_sources}" return {"running_summary": state.running_summary} def route_research(state: SummaryState, config: RunnableConfig) -> Literal["finalize_summary", "web_research"]: """确定研究流程中的下一步。 通过判断是继续收集信息还是完成总结来控制研究循环, 这个决定基于配置的最大研究循环次数。 参数: state: 包含研究循环计数的当前状态 config: 包含max_web_research_loops设置的配置 返回: 指示下一个要访问的节点的字符串("web_research"或"finalize_summary") """ configurable = Configuration.from_runnable_config(config) if state.research_loop_count <= configurable.max_web_research_loops: return "web_research" else: return "finalize_summary" # 构建工作流图 builder = StateGraph(SummaryState, input=SummaryStateInput, output=SummaryStateOutput, config_schema=Configuration) # 添加节点 builder.add_node("generate_query", generate_query) # 查询生成节点 builder.add_node("web_research", web_research) # 网络研究节点 builder.add_node("summarize_sources", summarize_sources) # 来源总结节点 builder.add_node("reflect_on_summary", reflect_on_summary) # 总结反思节点 builder.add_node("finalize_summary", finalize_summary) # 最终总结节点 # 添加边,定义节点间的工作流转换 builder.add_edge(START, "generate_query") # 从开始到查询生成 builder.add_edge("generate_query", "web_research") # 从查询生成到网络研究 builder.add_edge("web_research", "summarize_sources") # 从网络研究到来源总结 builder.add_edge("summarize_sources", "reflect_on_summary") # 从来源总结到总结反思 builder.add_conditional_edges("reflect_on_summary", route_research) # 从总结反思到条件路由 builder.add_edge("finalize_summary", END) # 从最终总结到结束 # 编译图,生成可执行的工作流 graph = builder.compile() # builder 是 LangGraph 的核心对象,用于构建有状态的研究流程图。 # StateGraph 的参数说明: # - SummaryState: 图中每个节点处理和传递的状态对象类型,包含研究主题、总结、来源等信息。 # - input=SummaryStateInput: 图的输入数据结构,定义了流程启动时需要哪些输入。 # - output=SummaryStateOutput: 图的输出数据结构,定义了流程结束时输出的内容。 # - config_schema=Configuration: 配置模式,定义了流程运行时可用的所有配置项(如LLM模型、搜索API等)。 # 这是流程图的构建器对象,后续会用它添加节点和边
CODE - STATE
import operator from dataclasses import dataclass, field from typing_extensions import Annotated @dataclass(kw_only=True) class SummaryState: research_topic: str = field(default=None) # Report topic search_query: str = field(default=None) # Search query web_research_results: Annotated[list, operator.add] = field(default_factory=list) sources_gathered: Annotated[list, operator.add] = field(default_factory=list) research_loop_count: int = field(default=0) # Research loop count running_summary: str = field(default=None) # Final report @dataclass(kw_only=True) class SummaryStateInput: research_topic: str = field(default=None) # Report topic @dataclass(kw_only=True) class SummaryStateOutput: running_summary: str = field(default=None) # Final report
CODE - PROMPT
from datetime import datetime # Get current date in a readable format def get_current_date(): return datetime.now().strftime("%B %d, %Y") query_writer_instructions="""Your goal is to generate a targeted web search query. <CONTEXT> Current date: {current_date} Please ensure your queries account for the most current information available as of this date. </CONTEXT> <TOPIC> {research_topic} </TOPIC> <FORMAT> Format your response as a JSON object with ALL three of these exact keys: - "query": The actual search query string - "rationale": Brief explanation of why this query is relevant </FORMAT> <EXAMPLE> Example output: {{ "query": "machine learning transformer architecture explained", "rationale": "Understanding the fundamental structure of transformer models" }} </EXAMPLE> Provide your response in JSON format:""" summarizer_instructions=""" <GOAL> Generate a high-quality summary of the provided context. </GOAL> <REQUIREMENTS> When creating a NEW summary: 1. Highlight the most relevant information related to the user topic from the search results 2. Ensure a coherent flow of information When EXTENDING an existing summary: 1. Read the existing summary and new search results carefully. 2. Compare the new information with the existing summary. 3. For each piece of new information: a. If it's related to existing points, integrate it into the relevant paragraph. b. If it's entirely new but relevant, add a new paragraph with a smooth transition. c. If it's not relevant to the user topic, skip it. 4. Ensure all additions are relevant to the user's topic. 5. Verify that your final output differs from the input summary. < /REQUIREMENTS > < FORMATTING > - Start directly with the updated summary, without preamble or titles. Do not use XML tags in the output. < /FORMATTING > <Task> Think carefully about the provided Context first. Then generate a summary of the context to address the User Input. </Task> """ reflection_instructions = """You are an expert research assistant analyzing a summary about {research_topic}. <GOAL> 1. Identify knowledge gaps or areas that need deeper exploration 2. Generate a follow-up question that would help expand your understanding 3. Focus on technical details, implementation specifics, or emerging trends that weren't fully covered </GOAL> <REQUIREMENTS> Ensure the follow-up question is self-contained and includes necessary context for web search. </REQUIREMENTS> <FORMAT> Format your response as a JSON object with these exact keys: - knowledge_gap: Describe what information is missing or needs clarification - follow_up_query: Write a specific question to address this gap </FORMAT> <Task> Reflect carefully on the Summary to identify knowledge gaps and produce a follow-up query. Then, produce your output following this JSON format: {{ "knowledge_gap": "The summary lacks information about performance metrics and benchmarks", "follow_up_query": "What are typical performance benchmarks and metrics used to evaluate [specific technology]?" }} </Task> Provide your analysis in JSON format:"""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号