deep-searcher --- Open Source Deep Research Alternative to Reason and Search on Private Data. Written in Python.
deep-searcher
Open Source Deep Research Alternative to Reason and Search on Private Data. Written in Python.
https://github.com/zilliztech/deep-searcher
![]()

DeepSearcher combines cutting-edge LLMs (OpenAI o3, Qwen3, DeepSeek, Grok 3, Claude 4 Sonnet, Llama 4, QwQ, etc.) and Vector Databases (Milvus, Zilliz Cloud etc.) to perform search, evaluation, and reasoning based on private data, providing highly accurate answer and comprehensive report. This project is suitable for enterprise knowledge management, intelligent Q&A systems, and information retrieval scenarios.

- Private Data Search: Maximizes the utilization of enterprise internal data while ensuring data security. When necessary, it can integrate online content for more accurate answers.
- Vector Database Management: Supports Milvus and other vector databases, allowing data partitioning for efficient retrieval.
- Flexible Embedding Options: Compatible with multiple embedding models for optimal selection.
- Multiple LLM Support: Supports DeepSeek, OpenAI, and other large models for intelligent Q&A and content generation.
- Document Loader: Supports local file loading, with web crawling capabilities under development.

https://zilliztech.github.io/deep-searcher/examples/basic_example/#overview
import logging import os from deepsearcher.offline_loading import load_from_local_files from deepsearcher.online_query import query from deepsearcher.configuration import Configuration, init_config httpx_logger = logging.getLogger("httpx") # disable openai's logger output httpx_logger.setLevel(logging.WARNING) current_dir = os.path.dirname(os.path.abspath(__file__)) config = Configuration() # Customize your config here init_config(config=config) # You should clone the milvus docs repo to your local machine first, execute: # git clone https://github.com/milvus-io/milvus-docs.git # Then replace the path below with the path to the milvus-docs repo on your local machine # import glob # all_md_files = glob.glob('xxx/milvus-docs/site/en/**/*.md', recursive=True) # load_from_local_files(paths_or_directory=all_md_files, collection_name="milvus_docs", collection_description="All Milvus Documents") # Hint: You can also load a single file, please execute it in the root directory of the deep searcher project load_from_local_files( paths_or_directory=os.path.join(current_dir, "data/WhatisMilvus.pdf"), collection_name="milvus_docs", collection_description="All Milvus Documents", # force_new_collection=True, # If you want to drop origin collection and create a new collection every time, set force_new_collection to True ) question = "Write a report comparing Milvus with other vector databases." _, _, consumed_token = query(question, max_iter=1) print(f"Consumed tokens: {consumed_token}")
https://zilliz.com/blog/introduce-deepsearcher-a-local-open-source-deep-research
https://zilliz.com/blog/introduce-deepsearcher-a-local-open-source-deep-research
DeepSearcher Architecture
The architecture of DeepSearcher follows our previous post by breaking the problem up into four steps - define/refine the question, research, analyze, synthesize - although this time with some overlap. We go through each step, highlighting DeepSearcher’s improvements.
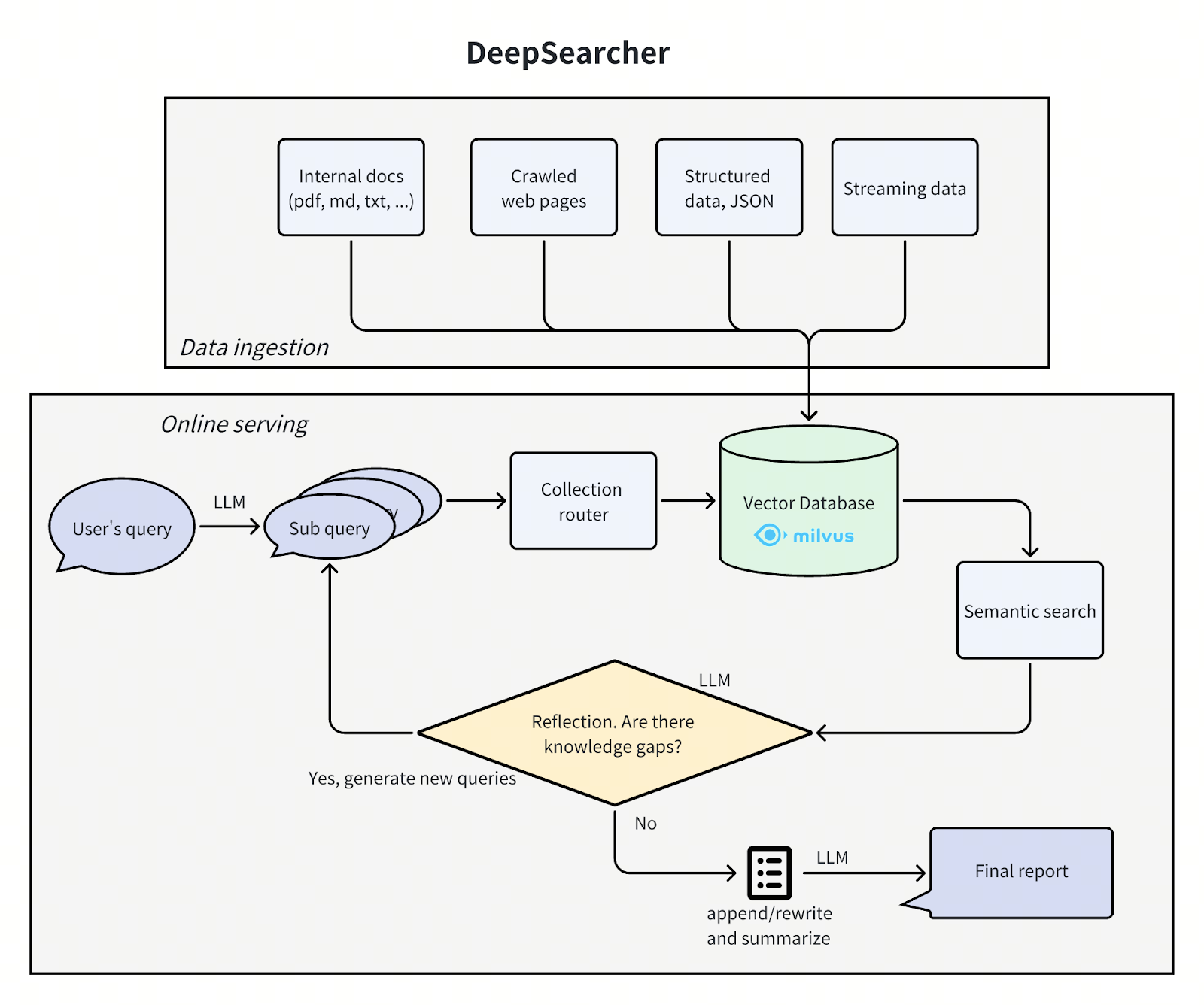 deepsearcher architecture.png
deepsearcher architecture.png
Define and Refine the Question
Break down the original query into new sub queries: [
'How has the cultural impact and societal relevance of The Simpsons evolved from its debut to the present?',
'What changes in character development, humor, and storytelling styles have occurred across different seasons of The Simpsons?',
'How has the animation style and production technology of The Simpsons changed over time?',
'How have audience demographics, reception, and ratings of The Simpsons shifted throughout its run?']
In the design of DeepSearcher, the boundaries between researching and refining the question are blurred. The initial user query is decomposed into sub-queries, much like the previous post. See above for initial subqueries produced from the query “How has The Simpsons changed over time?”. However, the following research step will continue to refine the question as needed.
Research and Analyze
Having broken down the query into sub-queries, the research portion of the agent begins. It has, roughly speaking, four steps: routing, search, reflection, and conditional repeat.
Routing
Our database contains multiple tables or collections from different sources. It would be more efficient if we could restrict our semantic search to only those sources that are relevant to the query at hand. A query router prompts an LLM to decide from which collections information should be retrieved.
Here is the method to form the query routing prompt:
def get_vector_db_search_prompt(
question: str,
collection_names: List[str],
collection_descriptions: List[str],
context: List[str] = None,
):
sections = []
# common prompt
common_prompt = f"""You are an advanced AI problem analyst. Use your reasoning ability and historical conversation information, based on all the existing data sets, to get absolutely accurate answers to the following questions, and generate a suitable question for each data set according to the data set description that may be related to the question.
Question: {question}
"""
sections.append(common_prompt)
# data set prompt
data_set = []
for i, collection_name in enumerate(collection_names):
data_set.append(f"{collection_name}: {collection_descriptions[i]}")
data_set_prompt = f"""The following is all the data set information. The format of data set information is data set name: data set description.
Data Sets And Descriptions:
"""
sections.append(data_set_prompt + "\n".join(data_set))
# context prompt
if context:
context_prompt = f"""The following is a condensed version of the historical conversation. This information needs to be combined in this analysis to generate questions that are closer to the answer. You must not generate the same or similar questions for the same data set, nor can you regenerate questions for data sets that have been determined to be unrelated.
Historical Conversation:
"""
sections.append(context_prompt + "\n".join(context))
# response prompt
response_prompt = f"""Based on the above, you can only select a few datasets from the following dataset list to generate appropriate related questions for the selected datasets in order to solve the above problems. The output format is json, where the key is the name of the dataset and the value is the corresponding generated question.
Data Sets:
"""
sections.append(response_prompt + "\n".join(collection_names))
footer = """Respond exclusively in valid JSON format matching exact JSON schema.
Critical Requirements:
- Include ONLY ONE action type
- Never add unsupported keys
- Exclude all non-JSON text, markdown, or explanations
- Maintain strict JSON syntax"""
sections.append(footer)
return "\n\n".join(sections)
We make the LLM return structured output as JSON in order to easily convert its output to a decision on what to do next.
Search
Having selected various database collections via the previous step, the search step performs a similarity search with Milvus. Much like the previous post, the source data has been specified in advance, chunked, embedded, and stored in the vector database. For DeepSearcher, the data sources, both local and online, must be manually specified. We leave online search for future work.
async def async_retrieve( self, original_query: str, **kwargs ) -> Tuple[List[RetrievalResult], int, dict]: max_iter = kwargs.pop("max_iter", self.max_iter) ### SUB QUERIES ### log.color_print(f"<query> {original_query} </query>\n") all_search_res = [] all_sub_queries = [] total_tokens = 0 sub_queries, used_token = self._generate_sub_queries(original_query) total_tokens += used_token if not sub_queries: log.color_print("No sub queries were generated by the LLM. Exiting.") return [], total_tokens, {} else: log.color_print( f"<think> Break down the original query into new sub queries: {sub_queries}</think>\n" ) all_sub_queries.extend(sub_queries) sub_gap_queries = sub_queries for iter in range(max_iter): log.color_print(f">> Iteration: {iter + 1}\n") search_res_from_vectordb = [] search_res_from_internet = [] # TODO # Create all search tasks search_tasks = [ self._search_chunks_from_vectordb(query, sub_gap_queries) for query in sub_gap_queries ] # Execute all tasks in parallel and wait for results search_results = await asyncio.gather(*search_tasks) # Merge all results for result in search_results: search_res, consumed_token = result total_tokens += consumed_token search_res_from_vectordb.extend(search_res) search_res_from_vectordb = deduplicate_results(search_res_from_vectordb) # search_res_from_internet = deduplicate_results(search_res_from_internet) all_search_res.extend(search_res_from_vectordb + search_res_from_internet) if iter == max_iter - 1: log.color_print("<think> Exceeded maximum iterations. Exiting. </think>\n") break ### REFLECTION & GET GAP QUERIES ### log.color_print("<think> Reflecting on the search results... </think>\n") sub_gap_queries, consumed_token = self._generate_gap_queries( original_query, all_sub_queries, all_search_res ) total_tokens += consumed_token if not sub_gap_queries or len(sub_gap_queries) == 0: log.color_print("<think> No new search queries were generated. Exiting. </think>\n") break else: log.color_print( f"<think> New search queries for next iteration: {sub_gap_queries} </think>\n" ) all_sub_queries.extend(sub_gap_queries) all_search_res = deduplicate_results(all_search_res) additional_info = {"all_sub_queries": all_sub_queries} return all_search_res, total_tokens, additional_info
Reflection
Unlike the previous post, DeepSearcher illustrates a true form of agentic reflection, inputting the prior outputs as context into a prompt that “reflects” on whether the questions asked so far and the relevant retrieved chunks contain any informational gaps. This can be seen as an analysis step.
Here is the method to create the prompt:
def get_reflect_prompt(
question: str,
mini_questions: List[str],
mini_chuncks: List[str],
):
mini_chunk_str = ""
for i, chunk in enumerate(mini_chuncks):
mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n"""
reflect_prompt = f"""Determine whether additional search queries are needed based on the original query, previous sub queries, and all retrieved document chunks. If further research is required, provide a Python list of up to 3 search queries. If no further research is required, return an empty list.
If the original query is to write a report, then you prefer to generate some further queries, instead return an empty list.
Original Query: {question}
Previous Sub Queries: {mini_questions}
Related Chunks:
{mini_chunk_str}
"""
footer = """Respond exclusively in valid List of str format without any other text."""
return reflect_prompt + footer
Once more, we make the LLM return structured output, this time as Python-interpretable data.
Here is an example of new sub-queries “discovered” by reflection after answering the initial sub-queries above:
New search queries for next iteration: [
"How have changes in The Simpsons' voice cast and production team influenced the show's evolution over different seasons?",
"What role has The Simpsons' satire and social commentary played in its adaptation to contemporary issues across decades?",
'How has The Simpsons addressed and incorporated shifts in media consumption, such as streaming services, into its distribution and content strategies?']
Conditional Repeat
Unlike our previous post, DeepSearcher illustrates conditional execution flow. After reflecting on whether the questions and answers so far are complete, if there are additional questions to be asked the agent repeats the above steps. Importantly, the execution flow (a while loop) is a function of the LLM output rather than being hard-coded. In this case there is only a binary choice: repeat research or generate a report. In more complex agents there may be several such as: follow hyperlink, retrieve chunks, store in memory, reflect etc. In this way, the question continues to be refined as the agent sees fit until it decides to exit the loop and generate the report. In our Simpsons example, DeepSearcher performs two more rounds of filling the gaps with extra sub-queries.
Synthesize
Finally, the fully decomposed question and retrieved chunks are synthesized into a report with a single prompt. Here is the code to create the prompt:
def get_final_answer_prompt(
question: str,
mini_questions: List[str],
mini_chuncks: List[str],
):
mini_chunk_str = ""
for i, chunk in enumerate(mini_chuncks):
mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n"""
summary_prompt = f"""You are an AI content analysis expert, good at summarizing content. Please summarize a specific and detailed answer or report based on the previous queries and the retrieved document chunks.
Original Query: {question}
Previous Sub Queries: {mini_questions}
Related Chunks:
{mini_chunk_str}
"""
return summary_prompt
This approach has the advantage over our prototype, which analyzed each question separately and simply concatenated the output, of producing a report where all sections are consistent with each other, i.e., containing no repeated or contradictory information. A more complex system could combine aspects of both, using a conditional execution flow to structure the report, summarize, rewrite, reflect and pivot, and so on, which we leave for future work.
Results
Here is a sample from the report generated by the query “How has The Simpsons changed over time?” with DeepSeek-R1 passing the Wikipedia page on The Simpsons as source material:
Report: The Evolution of The Simpsons (1989–Present)
1. Cultural Impact and Societal Relevance
The Simpsons debuted as a subversive critique of American middle-class life, gaining notoriety for its bold satire in the 1990s. Initially a countercultural phenomenon, it challenged norms with episodes tackling religion, politics, and consumerism. Over time, its cultural dominance waned as competitors like South Park and Family Guy pushed boundaries further. By the 2010s, the show transitioned from trendsetter to nostalgic institution, balancing legacy appeal with attempts to address modern issues like climate change and LGBTQ+ rights, albeit with less societal resonance.
…
Conclusion
The Simpsons evolved from a radical satire to a television institution, navigating shifts in technology, politics, and audience expectations. While its golden-age brilliance remains unmatched, its adaptability—through streaming, updated humor, and global outreach—secures its place as a cultural touchstone. The show’s longevity reflects both nostalgia and a pragmatic embrace of change, even as it grapples with the challenges of relevance in a fragmented media landscape.
Find the full report here, and a report produced by DeepSearcher with GPT-4o mini for comparison.
Discussion
We presented DeepSearcher, an agent for performing research and writing reports. Our system is built upon the idea in our previous article, adding features like conditional execution flow, query routing, and an improved interface. We switched from local inference with a small 4-bit quantized reasoning model to an online inference service for the massive DeepSeek-R1 model, qualitatively improving our output report. DeepSearcher works with most inference services like OpenAI, Gemini, DeepSeek and Grok 3 (coming soon!).
Reasoning models, especially as used in research agents, are inference-heavy, and we were fortunate to be able to use the fastest offering of DeepSeek-R1 from SambaNova running on their custom hardware. For our demonstration query, we made sixty-five calls to SambaNova’s DeepSeek-R1 inference service, inputting around 25k tokens, outputting 22k tokens, and costing $0.30. We were impressed with the speed of inference given that the model contains 671-billion parameters and is 3/4 of a terabyte large. Find out more details here!
We will continue to iterate on this work in future posts, examining additional agentic concepts and the design space of research agents. In the meanwhile, we invite everyone to try out DeepSearcher, star us on GitHub, and share your feedback!
项目docker化
https://github.com/zilliztech/deep-searcher/tree/master
https://github.com/fanqingsong/deep-searcher/tree/master
Milvus API
https://milvus.io/api-reference/restful/v2.5.x/v2/Collection%20(v2)/List.md
deep searcher doc
https://zilliztech.github.io/deep-searcher/configuration/file_loader/#docling
Milvus1 comments
https://ds2man.github.io/posts/Milvus1/
Introuduce Milvus
According to the DB-Engines Ranking website, various VectorDBs exist, including Milvus, Pinecone, and Chroma. Since I have to use a VectorDB going forward, I was uncertain about which DBMS to choose, but ultimately I selected Milvus because it ranks highest among the open-source VectorDB options. (Honestly, I wanted to use Pinecone, but I was discouraged after learning it’s a paid service…)
Functionally, Milvus offers various advantages such as high
performance, scalability, diverse indexing algorithm support,
easy-to-use APIs (REST API), and optimization for cloud and container
environments. Honestly, there are many aspects I’m not entirely familiar
with yet. As an engineer, I plan to approach it primarily from a
practical usage perspective. For further details, refer to Milvus Home.
- DB-Engines Ranking of Vector DBMS(Source: DB-Engines Ranking, update 2nd : 20250309)
| Rank | DBMS | Database Model | Score | ||||
|---|---|---|---|---|---|---|---|
| Mar 2025 |
Feb 2025 |
Mar 2024 |
- | - | Mar 2025 |
Feb 2025 |
Mar 2024 |
| 1. | 1. | 1. | Elasticsearch | Multi-model |
| 131.38 | -3.25 | -3.41 | ||
| 2. | 2. | 2. | Couchbase | Multi-model |
| 15.05 | -0.58 | -4.11 | ||
| 3. | 3. | 3. | Kdb | Multi-model |
| 7.10 | +0.31 | -0.59 | ||
| 4. | 4. | 4. | Aerospike | Multi-model |
| 5.22 | +0.12 | -1.30 |
| 5. | 5. |
| 6. | Pinecone | Vector | 3.17 | +0.22 | -0.16 |
| 6. | 6. |
| 9. | Milvus | Vector | 2.77 | +0.00 | +1.07 |
| 7. | 7. |
| 5. | DolphinDB | Multi-model |
| 2.29 | -0.09 | -1.85 |
| 8. | 8. |
| 12. | Qdrant | Vector | 2.03 | +0.10 | +0.78 |
| 9. | 9. |
| 7. | Chroma | Vector | 1.89 | +0.04 | -0.39 |
| 10. | 10. |
| 8. | Weaviate | Vector | 1.58 | -0.07 | -0.42 |
| 11. | 11. | 11. | Meilisearch | Multi-model |
| 1.20 | +0.07 | -0.13 |
Milvus Architecture(Source: Milvus Architecture)
Install Milvus and MinIO and Attu
The Milvus GitHub Releases page is where you can check and download the official release versions of Milvus. Here, you can find both the latest and previous versions of Milvus. It provides a docker-compose-gpu.yml file, which includes not only Milvus Standalone but also the installation of etcd and MinIO. The reason for installing etcd and MinIO together seems to be related to Milvus’s architecture. Looking at the Milvus architecture, the Standalone mode runs as a single instance, but internally, it still requires metadata management (etcd) and object storage (MinIO).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号