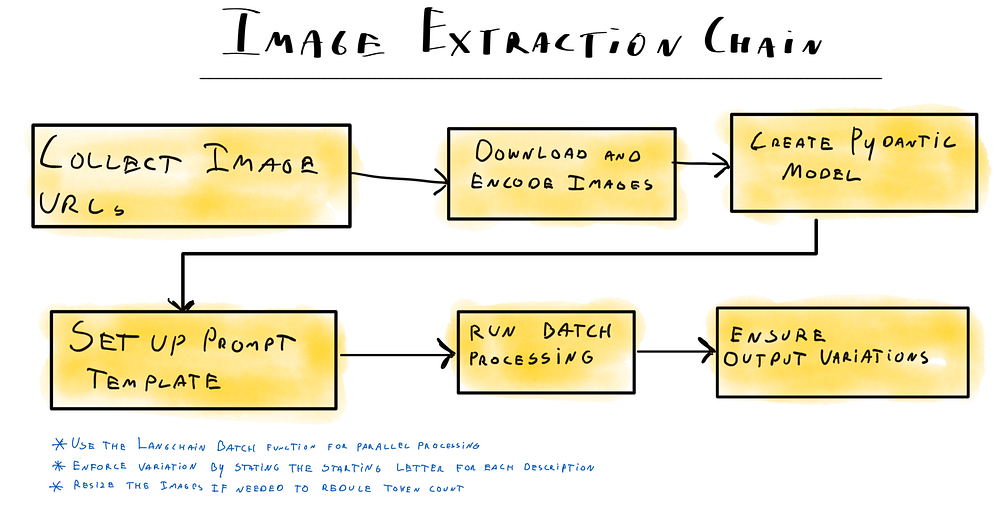
you have a large collection of images that you want to annotate using a language model? This guide will walk you through leveraging Langchain and Gemini-Flash-1.5 to extract content from images and return structured attributes. We’ve implemented this for a large online retailer, processing thousands of product images. By describing the images and extracting additional attributes like color and SEO hashtags, we can generate structured data that enhances user experience and SO ranking when uploaded to an e-commerce site.
We use a combination of LLMs for various sub-tasks and Langchain to efficiently parse the LLM output. Langchain also boosts performance by running operations in parallel.
Our images
For the case example, I have taken pictures of some fruit; we’ll use them to create an extraction pipeline and try annotating them using an LLm.
# Images to extract data from fruits = ['https://storage.googleapis.com/vectrix-public/fruit/apple.jpeg', 'https://storage.googleapis.com/vectrix-public/fruit/banana.jpeg', 'https://storage.googleapis.com/vectrix-public/fruit/kiwi.jpeg', 'https://storage.googleapis.com/vectrix-public/fruit/peach.jpeg', 'https://storage.googleapis.com/vectrix-public/fruit/plum.jpeg']
Passing an Image Directly to the Model
We can pass an image directly to an LLM without using Langchain. Let’s test this with the Gemini Flash model and see how it responds. Make sure to set your API key as an environment variable named GOOGLE_API_KEY.
Example Code
from langchain_core.messages import HumanMessage from langchain_google_genai import ChatGoogleGenerativeAI import base64, httpx
# Initialize the model model = ChatGoogleGenerativeAI(model="gemini-1.5-flash")
# Download and encode the image image_data = base64.b64encode(httpx.get(fruits[0]).content).decode("utf-8")
# Create a message with the image message = HumanMessage( content=[ {"type": "text", "text": "describe the fruit in this image"}, { "type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_data}"}, }, ], )
# Invoke the model with the message response = model.invoke([message])
# Print the model's response print(response.content)
Model Response
The model responds with a detailed description of the fruit in the image. For example:
The fruit is an apple. It is red and yellow, with a small stem on top. The apple has a dimple in the center where the stem was attached. The apple is slightly bruised.
How It Works
Initialize the Model: We use the ChatGoogleGenerativeAI package from Langchain to initialize the Gemini Flash model.
Download and Encode the Image: The image is downloaded and encoded using base64 encoding.
Create the Message: We create a HumanMessage that includes both a text prompt and the encoded image.
Invoke the Model: The model is invoked with the message, and it processes the image to generate a description.
Print the Response: The response from the model is printed, providing a detailed description of the fruit.
By using the ChatGoogleGenerativeAI package, we can directly interact with the Gemini Flash model, passing images and receiving descriptive responses. This approach allows us to quickly test the model's capabilities and understand how it handles image inputs.
Now that we have images and know how to call the model let’s set up the extraction pipeline.
Step 1: Define the output structure
The next step is to extract structured data from the image. We can achieve this by combining a Pydantic parser with a multi-modal message. First, we define a Pydantic data model and then pass that on to the model to extract structured data from the image.
Defining the Data Model
We use Pydantic to define a data model, which helps ensure that the extracted data is structured and validated. In this example, we define a Fruit model with fields for the name, color, taste, and marketing description of the fruit shown in the image.
from langchain.output_parsers import PydanticOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_core.pydantic_v1 import BaseModel, Field
# Define a Pydantic model to parse the model's output class Fruit(BaseModel): name: str = Field(description="The name of the fruit shown in the image") color: str = Field(description="The color of the fruit shown in the image") taste: str = Field(description="The taste of the fruit shown in the image") marketing_description: str = Field(description="A marketing description of the fruit shown in the image")
We create a prompt using ChatPromptTemplate that asks the model to return a response in the desired JSON structure. The prompt includes system and human messages, where the human message provides the image URL encoded in base64.
We then combine the prompt, model, and parser into a chain. The model processes the image and returns the data in JSON format, which the PydanticOutputParser then parses and validates against the Fruit data model.
chain = prompt | model | parser
# Retrieve the encoded image data image_data = base64.b64encode(httpx.get(fruits[3]).content).decode("utf-8")
# Run the chain and print the result print(chain.invoke({ "language": "English", "format_instructions": parser.get_format_instructions(), "image_data": image_data }).json(indent=2))
How It Works
Prompt Creation: The ChatPromptTemplate constructs a prompt instructing the model to respond in a specific JSON format.
Model Processing: The multi-modal LLM, Gemini-Flash-1.5, processes the image and generates a JSON response containing the structured data.
Parsing and Validation: The PydanticOutputParser parses the JSON response and validates it against the Fruit data model, ensuring the data is correctly structured and adheres to the defined schema.
As seen in the example above, we create a new chain combining a prompt, an image, and format instructions that ask the model to return a response in the desired JSON structure. We then use a PydanticOutputParser to extract the JSON from the LLM response and load it as a dictionary. The final response object looks like this:
{ "name": "Peach", "color": "Orange", "taste": "Sweet", "marketing_description": "A juicy and flavorful peach, perfect for a summer snack or dessert." }
Step 2: Processing the images in parallel
The pipeline we defined in the first step works great but can be slow if you want to process thousands of images. Since it can take multiple seconds to parse a single image, running this sequentially for large datasets can take hours or even days. The solution for this is parallel processing, and fortunately, Langchain has a solution for this: the chain.batch function.
Running the Chain in Parallel
To run the chain in parallel for all the images, we first prepare a list of dictionaries containing the necessary data for each image. We then use the batch method on our chain, which allows us to process multiple images simultaneously.
# Prepare the list of image data dictionaries all_images = [{"language": "English", "format_instructions": parser.get_format_instructions(), "image_data": base64.b64encode(httpx.get(url).content).decode("utf-8")} for url in fruits]
How It Works
Prepare Data: We create a list of dictionaries, each containing the language, format instructions, and base64-encoded image data for each image URL.
Parallel Processing: By using the batch method on our chain, we can process all extraction requests in parallel. The max_concurrency The config option helps manage the number of concurrent requests to avoid hitting the model API's rate limits.
Retrieve Results: The results object contains a list of dictionaries with the extracted data for each image.
Example Output
The results object will contain structured data for each image, similar to the following examples:
{ "name": "Apple", "color": "Red and Green", "taste": "Sweet and Tart", "marketing_description": "A crisp and juicy apple with a sweet and tart flavor. Perfect for snacking or baking." } { "name": "Banana", "color": "Yellow", "taste": "Sweet", "marketing_description": "A delicious and nutritious fruit, perfect for a quick snack or a healthy breakfast. Our bananas are ripe and ready to eat, with a sweet and creamy flavor that everyone will love." } ...
Step 3: Ensure the Output Contains Enough Variations
As seen in the examples above, descriptions can be very similar. Language models generate similar output given the same prompt for a similar task. While adjusting the model's temperature might mitigate this, it can also risk breaking the JSON structure if set too high.
Similar output isn’t great for SEO purposes, so we must ensure the model generates unique descriptions. We can achieve some variation by forcing our model to start the output with a random letter and length. Here are the functions we use for this:
First, we update our prompt to include variables for the starting letter and the length.
# A new prompt template that includes the marketing description starting with a given letter prompt = ChatPromptTemplate.from_messages([ ( "system", "Return the requested response object in {language}. Make sure the marketing description starts with the letter '{starting_letter}'\n'{format_instructions}'\n" ), ( "human", [ { "type": "image_url", "image_url": {"url": "data:image/jpeg;base64,{image_data}"}, }, ], ) ])
Adding Randomness to the Batch
Next, we update the dictionary used to call the batch so that it includes some randomness in our prompt.
# Prepare the list of image data dictionaries with added randomness all_images = [{"language": "English", "format_instructions": parser.get_format_instructions(), "image_data": base64.b64encode(httpx.get(url).content).decode("utf-8"), "starting_letter": generate_random_letter()} for url in fruits]
chain = prompt | model | parser
# Run the chain in parallel with a specified max concurrency results = chain.batch(all_images, config={"max_concurrency": 5})
# Print the results for result in results: print(result.json(indent=2))
How It Works
Generate Random Values: We use generate_random_letter Create a random starting letter for each description to ensure output variation.
Update Prompt: The prompt includes the starting letter variable, forcing the model to begin the marketing description with this letter.
Parallel Processing with Randomness: By adding the starting letter to each dictionary in the all_images list, we introduce variation into our batch processing.
Example Output
Printing the results will show output with much more variation:
{ "name": "Apple", "color": "Red and Green", "taste": "Sweet and Tart", "marketing_description": "Crisp, juicy, and bursting with flavor, this apple is the perfect snack for any occasion. Enjoy it on its own, or use it in your favorite recipes." } { "name": "Banana", "color": "Yellow", "taste": "Sweet", "marketing_description": "Bananas are a delicious and versatile fruit that can be enjoyed in many different ways. They are a good source of potassium and fiber, and they are also a good source of vitamins B6 and C. Bananas are a great snack, and they can also be used in smoothies, baked goods, and other recipes. They are also a great source of energy, and they can help to improve your mood." } { "name": "Kiwi", "color": "Green", "taste": "Sweet and tangy", "marketing_description": "Come and try our delicious kiwi! This green fruit is sweet and tangy, perfect for a healthy snack or a refreshing addition to your smoothies." } ...
By incorporating randomness into the prompt, we can ensure that the model generates unique and varied descriptions, which is beneficial for SEO purposes.
Final Thoughts
We hope this informative guide inspires you to experiment with image metadata extraction in your projects. To dive deeper into the code and try it out, check out our Jupyter Notebook on Google Colab.
If you have any questions or want to learn more about our work at Vectrix, feel free to visit our website at https://vectrix.ai. We’re always excited to connect with fellow AI enthusiasts and help bring your ideas to life.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号